深度学习(12):SemanticKITTI论文翻译与学习
SemanticKITTI论文是发表在CVPR 2019上的一篇在KITTI Vision Odometry Benchmark数据集上制作语义分割数据集SemanticKITTI的文章,为基于车载激光雷达语义分割提供了大量的数据;作者单位是德国波恩大学
SemanticKITTI论文地址:https://arxiv.org/abs/1904.01416
SemanticKITTI数据集地址:http://www.semantic-kitti.org/

翻译部分如下:
Abstract
1. Introduction
2. Related Work
3 The SemanticKITTI Dataset
3.1 Labeling Process(标注过程)
3.2 Dataset Statistics(数据集统计)
4.Evaluation of Semantic Segmentation(语义分割评估)
4.1. Single Scan Experiments(单次扫描实验)
State of the Art(最先进的)。
Baseline approaches(基准方法)。
Results and Discussion(结果和讨论)。
4.2. Multiple Scan Experiments(多重扫描实验)
(Task and Metrics)任务和指标。
基准(baselines)。
Result and Discussion(结果和讨论)。
5 Evaluation of Semantic Scene Completion(语义场景补全评估)
Dataset Generation(数据集生成)。
Task and Metrics(任务和指标)。
State of the art(最先进的)。
Baseline Approaches(基准方法)。
Result and Discuss(结果和讨论)。
6. Conclusion and Outlook(结论与展望)
Acknowledgements(致谢)
附录部分
A Consistent Labels for LiDAR Sequences(LiDAR 序列的一致标签)
Tile-Based Labeling(基于图块的标签)。
Moving Objects(移动物体)。
B Basis of the Dataset(数据集的基础)
C Class Definition(类定义)
D Baseline Setup(基线设置)
E Results using Multiple Scans(使用多次扫描的结果)
F Semantic Scene Completion(语义场景补全)
G Qualitative Results(定性结果)
H Dataset and Baseline Access API(数据集和基准访问 API)
部分笔记
1 true positive, true negative, false positive, false negative
2 交并比IoU公式理解
Reference(参考文献)
SemanticKITTI: A Dataset for Semantic Scene Understanding of LiDAR Sequences
SemanticKITTI:用于对 LiDAR 序列进行语义场景理解的数据集
图 1:我们的数据集为来自 KITTI Odometry Benchmark [19] 的所有序列的每次扫描提供密集注释。在这里,我们展示了使用 SLAM 方法估计的位姿信息聚合的多个扫描。
Abstract
语义场景理解对于各种应用都很重要。特别是,自动驾驶汽车需要对其附近的表面和物体有细粒度的了解(fine-grained understanding)。光探测和测距 (LiDAR) 提供有关环境的精确几何信息,因此是几乎所有自动驾驶汽车传感器套件的一部分。尽管语义场景理解与此应用(指的是自动驾驶)相关,但仍缺乏用于此任务的基于汽车 LiDAR 的大型数据集。
在本文中,我们引入了一个大型数据集来推动基于激光的语义分割研究。我们对 KITTI Vision Odometry Benchmark 的所有序列进行了注释,并为所使用的汽车 LiDAR 的完整 360 度视野提供了密集的逐点注释。我们基于该数据集提出了三个基准测试任务: (i) 使用单次扫描对点云进行语义分割,(ii) 使用多次过去扫描的语义分割,以及(iii) 语义场景补全,这需要预测未来的语义场景。我们提供了基准实验(baseline experiments),并表明需要更复杂的模型来有效地处理这些任务。我们的数据集为开发更先进的方法打开了大门,同时也为研究新的研究方向提供了丰富的数据。
1. Introduction
语义场景理解对于许多应用和自动驾驶汽车不可或缺的一部分至关重要。特别是,语义分割提供的细粒度理解(fine-grained understanding)对于区分可驾驶和不可驾驶表面以及推理功能属性(如停车区和人行道)是必要的。目前,这种以所谓的高清地图(high definition maps)为代表的理解主要是使用测绘车辆预先生成的。然而,自动驾驶汽车也应该能够在没有地图的区域内行驶,并在环境发生变化时调整其行为。
大多数自动驾驶汽车目前使用多个不同的传感器来感知环境。互补的传感器模式能够应对特定传感器的缺陷或故障。除了相机外,还经常使用光检测和测距 (LiDAR) 传感器,因为它们可以提供不受光照影响的精确距离测量。
公开可用的数据集和基准对于研究的实证评估至关重要。它们主要实现三个目的: (i) 它们提供了衡量进展的基础,因为它们允许提供可重复和可比较的结果, (ii) 他们发现了当前技术水平的缺陷,因此为新方法和研究方向铺平了道路,并且(iii) 它们使开发方法成为可能,而无需首先费力地收集和标记数据。虽然存在多个用于基于图像的语义分割的大型数据集 [10, 39],但具有三维点云逐点注释的公开可用数据集仍然相对较小,如表 1 所示。

表 1:具有语义注释的其他点云数据集概述。我们的数据集是迄今为止最大的带有序列信息的数据集。#1 训练和测试集的扫描次数,#2 点数以百万为单位,#3 用于评估的类数和括号中的是标注的类数。
为了缩小这一差距,我们提出了 SemanticKITTI,这是一个大型数据集,在具有 28 个类的逐点注释中显示出前所未有的细节,适用于各种任务。在本文中,我们主要关注基于激光的语义分割,以及语义场景补全(scene completion)。该数据集不同于其他激光数据集,因为我们提供了准确的序列扫描注释。总体而言,我们注释了 KITTI Vision Benchmark [19] 里程计基准的所有 22 个序列,包括超过 43 000 次扫描。此外,我们标记了旋转激光传感器的完整水平 360° 视野。图 1 显示了来自所提供数据集的示例场景。 总之,我们的主要贡献是:
• 我们提出了一个点云序列的逐点注释数据集,具有前所未有的类别数量和每次扫描的看不见的细节水平(unseen level-of-detail)。
• 我们还提供了对点云语义分割最先进方法的评估。
• 我们使用多次扫描研究使用序列信息进行语义分割。
• 基于移动汽车序列的注释,我们进一步引入了用于语义场景补全(semantic scene completion)的真实世界数据集并提供基准结果(baseline results)。
• 与基准网站一起,点云标记工具也是公开的,使其他研究人员能够在未来生成其他标记数据集。
这个庞大的数据集将刺激新算法的发展,使研究新的研究方向成为可能,并为这些新算法的评估和比较奠定更坚实的基础。
2. Related Work
计算机视觉的进步一直是由基准和数据集 [55] 推动的,但特别是大规模数据集的可用性(例如 ImageNet [13])甚至是深度学习出现的关键先决条件。
更多针对自动驾驶汽车的特定任务数据集(task-specific datasets)也被提出。值得注意的是 KITTI Vision Benchmark [19],因为它表明现成的解决方案(off-the-shelf solution)并不总是适用于自动驾驶。Cityscapes 数据集 [10] 是第一个用于自动驾驶汽车应用的数据集,它提供了大量适用于深度学习的像素级标记图像。与 Cityscapes 相比,Mapillary Vistas 数据集 [39] 标记数据的数量更多和多样性更丰富。
同样基于点云的表示(point cloud-based interpretation),例如语义分割,基于 RGB-D 的数据集实现了巨大的进步。ShapeNet [8] 对显示单个对象的点云尤其值得注意,但此类数据不能直接转移到其他领域。具体来说,LiDAR 传感器通常不会像 RGB-D 传感器那样密集地覆盖物体,因为它们的角分辨率较低,尤其是在垂直方向上。
对于室内环境,有几个数据集 [48, 46, 24, 3, 11, 35, 32, 12] 可用,主要使用 RGB-D 相机记录或合成生成。然而,与室外环境相比,这些数据显示出非常不同的特征,这也是由环境的大小造成的,因为在室内捕获的点云由于扫描对象的距离而往往更密集。 此外,传感器在稀疏性和准确性方面具有不同的属性。虽然激光传感器比 RGB-D 传感器更精确,但与后者相比,它们通常只捕获稀疏的点云。
对于室外环境,最近提出了使用地面激光扫描仪 (TLS,terrestrial laser scanner) 记录的数据集,如 Semantic3d 数据集 [23],或使用汽车激光雷达,如 Paris-Lille-3D 数据集 [47]。然而,Paris-Lille-3D 仅提供了 50 个类别的聚合扫描(aggregated scans)和逐点注释,从中选择了 9 个类别进行评估。另一个最近用于自动驾驶的大型数据集 [57],但类别较少,尚未公开。
Virtual KITTI 数据集 [17] 提供了具有深度信息和密集像素级注释的综合生成的序列图像。深度信息也可用于生成点云。然而,这些点云并没有显示出与真正的旋转 LiDAR 相同的特征,包括反射和异常值等缺陷。
与这些数据集相比,我们的数据集结合了大量标记点、种类繁多的类别以及由自动驾驶中常用传感器生成的顺序扫描(sequential scans),这与所有公开可用的数据集不同,如表 1 所示.
3 The SemanticKITTI Dataset
我们的数据集基于 KITTI Vision Benchmark [19] 的里程计数据集,显示了内城交通(inner city traffic)、住宅区(residential areas),以及德国卡尔斯鲁厄周围的高速公路场景和乡村道路。原始里程计数据集(the original odometry dataset)由 22 个序列组成,并把序列 00 到 10 作为训练集,11 到 21 作为测试集。为了与原始基准保持一致,我们对训练集和测试集采用相同的划分。此外,我们通过仅为训练数据提供标签,这不会干扰原始里程计基准。总体而言,我们提供了 23201 个完整的 3D 扫描用于训练和 20351 个用于测试,这使其成为公开可用的最大数据集。
我们决定使用 KITTI 数据集作为我们标记工作的基础,因为它使我们能够利用汽车捕获的最大可用原始点云数据集合之一。我们还期望我们的注释和现有基准之间也存在潜在的协同作用,这将有助于调查和评估其他研究方向,例如使用语义进行基于激光的里程计估计。
与其他数据集(参见表 1)相比,我们为使用常用汽车激光雷达(即 Velodyne HDL64E)生成的顺序点云提供了标签。其他公开可用的数据集,如 Paris-Lille-3D [47] 或 Wachtberg [6],也使用此类传感器,但仅分别提供整个采集序列的聚合点云或整个序列的一些单独扫描。由于我们提供了整个序列的单个扫描,因此还可以研究聚合多个连续扫描如何影响语义分割的性能(how aggregating multiple consecutive scans influences the performance of the semantic segmentation),并使用这些信息来识别移动对象。
我们注释了 28 个类,我们确保(我们标注的类)与 Mapillary Vistas 数据集 [39] 和 Cityscapes 数据集 [10] 的类有很大的重叠,并在必要时进行了修改以考虑稀疏性和垂直视野(the sparsity and vertical field-of-view)。更具体地说,我们不区分骑车人和车辆,而是将车辆和人标记为骑自行车的人或骑摩托车的人。
我们进一步区分了移动和非移动的车辆和人类,即,如果车辆或人类在观察它们的同时进行一些扫描,则得到相应的移动类别,如图 2 的下部所示。所有带注释的类都列在图 3 中,不同类的更详细的讨论和定义可以在补充材料中找到。总而言之,我们有 28 个类,其中 6 个类被分配了移动或非移动属性,并且包含一个由反射或其他影响引起的错误激光测量的异常值类。
该数据集可通过基准网站公开获得,我们仅提供带有真实标签的训练集并在线执行测试集评估。此外,我们还将限制可能的用于评估的测试集数量,以防止过度拟合测试集 [55](We furthermore will also limit the number of possible test set evaluations to prevent overfitting to the test set [55])。
Figure 2: Single scan (top) and multiple superimposed scans with labels (bottom). Also shown is a moving car in the center of the image resulting in a trace of points.
图 2:单次扫描(顶部)和带有标签的多次叠加扫描(底部)。 还在图像中心显示了由移动汽车产生的点的痕迹。

Figure 3: Label distribution. The number of labeled points per class and the root categories for the classes are shown. For movable classes, we also show the number of points on non-moving (solid bars) and moving objects (hatched bars).
图 3:标签分布。 显示了每个类的标记点数和类的根类别。 对于可移动类,我们还显示了非移动(实心条)和移动对象(阴影条)上的点数。
3.1 Labeling Process(标注过程)
为了使点云序列的标记变得实用,我们将多个扫描叠加在彼此之上(superimpose multiple scans above each other),相反,这允许我们一致地标记多个扫描(label multiple scans consistently)。为此,我们首先使用现成的基于激光的 SLAM 系统 [5] 注册并循环关闭序列(register and loop close the sequence)。这一步是必要的,因为惯性导航系统(INS,the intertial navigation system)提供的信息通常会导致地图不一致(map inconsistencies),即一段时间后重新访问的街道具有不同的高度。对于三个序列,我们必须手动添加闭环约束(add loop closure constraints)来获得正确的闭环轨迹(loop closed trajectories),因为这对于获得一致的点云进行注释(consistent point clouds for annotation)至关重要。循环闭合位姿(the loop closed poses)允许我们加载特定位置的所有重叠点云并将它们一起可视化,如图 2 所示。
我们将点云序列细分为 100 m x 100 m 的图块(tiles)。 对于每个图块,我们只加载与图块重叠的扫描。这使我们能够一致地标记所有扫描,即使我们遇到时间上遥远的闭环(temporally distant loop closures)。为了确保与多个图块重叠的扫描的一致性,我们显示每个图块内的所有点以及与相邻图块重叠的小边界。因此,可以从相邻图块继续标签。
遵循最佳实践,我们编写了标签说明并提供了有关如何标记某些物体的教学视频,例如靠近墙壁的汽车和自行车。与基于图像的注释相比,使用点云的注释过程更加复杂,因为标注人员经常需要改变视角(viewpoint)。在标记与遇到的最复杂的场景相对应的住宅区时,标注人员平均每个图块需要 4.5 小时,而标记高速公路图块平均需要 1.5 小时。
我们明确地没有使用 KITTI 数据集边界框或其他可用的注释,因为我们要确保标签是一致的,并且逐点标签应该只包含对象本身。
我们定期向标注人员提供反馈,以提高标签的质量和准确性。 尽管如此,单个标注人员还在第二遍中验证了标签,即纠正了不一致并添加了缺失的标签。总之,整个数据集包含 518 个图块,并且已经投入了超过 1400 小时的标记工作,每个图块额外进行了 10-60 分钟的验证和校正,总计超过 1700 小时。
3.2 Dataset Statistics(数据集统计)
图 3 显示了不同类别的分布,其中我们还将根类别作为 x 轴上的标签。地面(ground)类中,道路(road)、人行道(sidewalk)、建筑物(building)、植被(vegetation)和地形(terrain)是最常见的类。骑摩托车的人(motorcyclist)这个类很少出现,但仍有超过 100 000 个点被注释。
类的不平衡计数(the unblanced count of classes)对于在自然环境中捕获的数据集很常见,并且某些类的代表性总是不足,因为它们不经常发生。因此,不平衡的类分布是一种方法必须掌握的问题的一部分。总体而言,在其他数据集中,类之间的分布和相对差异非常相似,例如 城市景观 [10]。
4.Evaluation of Semantic Segmentation(语义分割评估)
在本节中,我们提供了几种最先进的单次扫描语义分割方法的评估。我们还提供了利用多次扫描序列提供的信息的实验。
4.1. Single Scan Experiments(单次扫描实验)
Task adn Metrics(任务和指标)。在点云的语义分割中,我们想要推断每个三维点(each three-dimensional)的标签。因此,所有评估方法的输入是三维点的坐标列表及其反射强度(remission),即取决于被击中的表面的特性的反射激光束的强度。然后,每种方法都应为扫描的每个点输出一个标签,即旋转 LiDAR 传感器的一整圈。
为了评估标记性能,我们依赖于所有类中常用的平均 Jaccard 指数或平均交叉联合(mIoU)度量 [15],由下式给出(注:公式理解见“部分笔记(2)”):

式中 TPc 、 FPc 和 FNc 对应于类别 c 的真阳性、假阳性和假阴性(true positive, false positive, and false negative,分析见“部分笔记(1)”)预测的数量,C 是类别的数量。
由于类 other-structure 和 other-object 要么只有几个点,要么类内变化很大过于多样化,我们决定不将这些类包括在评估中。因此,我们使用 25 个类而不是 28 个类,在训练和推理过程中忽略异常值、其他结构和其他对象(outlier,other-structure,and other-object)。
此外,我们不能指望通过单次扫描来区分移动物体和非移动物体,因为这种 Velodyne LiDAR 无法像利用多普勒效应(the Doppler effect)的雷达那样测量速度。因此,我们将移动类与相应的非移动类结合起来,总共有 19 个类用于训练和评估。
State of the Art(最先进的)。
点云的语义分割或逐点分类是一个由来已久的话题 [2],传统上是使用特征提取器(如 Spin Images [29])结合传统分类器(如支持向量机 [1]甚至语义哈希 [4])来解决的 。许多方法使用条件随机场 (CRF,Conditional Random Fields) 来强制相邻点的标签一致性 [56、37、36、38、63]。
随着基于图像分类的深度学习方法的出现,特征提取和分类的整个流程已被端到端深度神经网络所取代。基于体素的方法将点云转换为体素网格,然后应用具有 3D 卷积的卷积神经网络 (CNN) 进行对象分类 [34] 和语义分割 [26] 是最早研究的模型之一,因为他们允许利用以图像闻名的(深度学习)架构和洞察力。
为了克服基于体素表示(the voxel-based representation)的限制,例如当体素网格的分辨率增加时内存消耗爆炸式增长,最近的方法要么使用 CRF 上采样体素预测 [53],要么使用不同的表示,如更有效的空间细分 [30, 44, 64, 59, 21],渲染成2D 图像视图 [7]、图 [31, 54]、splats [51]、甚至直接点 [41, 40, 25, 22, 43, 28, 14](more recent approaches either upsample voxel-predictions [53] using a CRF or use different representations, like more efficient spatial subdivisions [30, 44, 64, 59, 21], rendered 2D image views [7], graphs [31, 54], splats [51], or even directly the points [41, 40, 25, 22, 43, 28, 14])。
Baseline approaches(基准方法)。
我们为数据集中的点云语义分割提供了六种最先进架构的结果:PointNet [40]、PointNet++ [41]、Tangent Convolutions [52]、SPLATNet [51]、Superpoint Graph [31 ] 和 SqueezeSeg(V1 和 V2)[60, 61]。此外,我们研究了 SqueezeSeg 的两个扩展:DarkNet21Seg 和 DarkNet53Seg。
PointNet [40] 和 PointNet++ [41] 使用原始无序点云数据作为输入。这些方法的核心是最大池化以获得一个顺序不变的算子(an order-invariant operator),该算子对于形状的语义分割和其他几个基准测试工作得非常好。然而,由于这种性质,PointNet 无法捕捉特征之间的空间关系。为了缓解这种情况,PointNet++ [41] 将单个 PointNets 应用于局部邻域(local neighborhoods),并使用分层方法来组合它们的输出。这使其能够构建复杂的分层特征(hierarchical features),同时捕获局部细粒度和全局上下文信息(local fine-grained and global contextual information)。
Tangent Convolutions [52] 还通过在表面上直接应用卷积神经网络来处理非结构化点云。这是通过假设数据是从光滑表面(smooth surfaces)采样,并将切线卷积定义为应用于在每个点的局部表面投影(the projection of the local surface)到切平面(the tangent plane)的卷积来实现的。
SPLATNet [51] 采用类似于上述体素化方法的方法,并在高维稀疏点阵中表示点云。与基于体素的方法一样,这在计算和内存成本方面的扩展性都很差,因此他们通过bilateral convolutions [27]来处理这种表示的稀疏性(they exploit the sparsity of this representation by using bilateral convolutions),它只对占用的格子部分进行操作。
与 PointNet 类似,Superpoint Graph [31] 通过将几何上同质的点组(geometrically homogeneous groups of points)汇总为超点(superpoints)来捕获局部关系,这些点随后由局部 PointNet 嵌入。结果是一个超点图(superpoint graph)表示,它比利用超点之间的上下文关系的原始点云更紧凑和丰富。、
SqueezeSeg [60, 61] 还以一种方式离散点云,该方式利用旋转 LiDAR 的传感器几何特性将 2D 卷积应用于点云数据。在旋转激光雷达的情况下,可以使用球面投影将单次旋转(single turn)的所有点投影到图像上。应用完全卷积神经网络,然后最后用 CRF 过滤以平滑结果。由于 SqueezeSeg 的良好结果和快速训练,我们研究了标签性能(labeling performance)如何受模型参数数量的影响。为此,我们使用了基于 Darknet 架构 [42] 的不同主干,分别具有 21 层和 53 层,以及 25 和 50 百万个参数。我们还去除了架构中使用的垂直下采样(vertical downsampling)。
我们修改了可用的实现(available implementations),以便可以在我们的大规模数据集上训练和评估这些方法。请注意,到目前为止,这些方法中的大多数仅在shape[8] 或 RGB-D 室内数据集 [48] 上进行了评估。然而,由于内存限制,一些方法 [40, 41] 只能在相当大的下采样到 50 000 点的情况下运行。
Results and Discussion(结果和讨论)。
表 2 显示了我们直接使用点云信息 [40、41、51、52、31] 或点云投影 [60] 的各种方法的基准实验结果。结果表明,当前的点云语义分割技术水平不足以满足我们数据集的大小和复杂性。
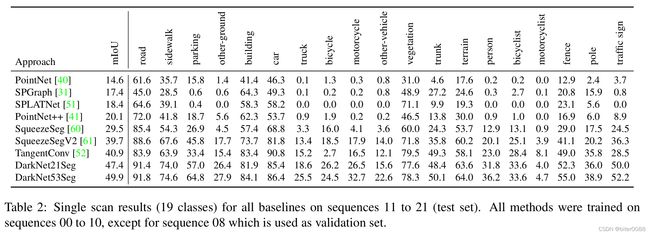
表 2:序列 11 到 21(测试集)上所有基准的单次扫描结果(19 类)。除了用作验证集的序列 08 之外,所有方法都在序列 00 到 10 上进行了训练。
我们认为这主要是由于所用架构的容量有限(见表 7),因为这些方法的参数数量远低于领先的基于图像的语义分割网络中使用的参数数量。如上所述,我们添加了 DarkNet21Seg 和 DarkNet53Seg 来测试这个假设,结果表明,这个简单的修改将准确率从 SqueezeSeg 的 29.5% 提高到了 DarkNet21Seg 的 47.4% 和 DarkNet53Seg 的 49.9%。

表 3:方法统计。

表 7:方法统计。 epochs数字旁边的*号表示它是从单扫描版本的预训练权重开始的。
另一个原因是 LiDAR 生成的点云相对稀疏,尤其是随着与传感器的距离增加。这在 SqueezeSeg 中得到了部分解决,它利用旋转扫描仪捕获数据的方式来生成密集距离/深度图像,其中每个像素大致对应于扫描中的一个点。
图 4 中进一步分析了这些影响,其中 mIoU 是关于到传感器的距离绘制的。它表明,随着距离的增加,所有方法的结果都会变得更糟。这进一步证实了我们的假设,即稀疏性是远距离结果较差的主要原因。然而,结果还表明,一些方法,如 SPGraph,受距离相关稀疏性(the distance-dependent sparsity)的影响较小,这可能是未来研究结合两种范式优势的有希望的方向。

图 4:IoU 与传感器距离的关系。
尤其是像摩托车手和卡车这样的例子很少的类,似乎对所有方法都更加困难。但是,在单个点云中只有少量点的类,如自行车和电线杆,也是难以解决的类。
最后,具有 49.9% mIoU 的最佳性能方法 (DarkNet53Seg) 仍远未达到与基于图像的方法相当的结果,例如,在 Cityscapes 基准测试中达到 80% [10]。
4.2. Multiple Scan Experiments(多重扫描实验)
(Task and Metrics)任务和指标。
在这项任务中,我们允许方法利用来自多个过去扫描序列的信息来改进当前扫描的分割。我们还想要区分移动和非移动类的方法,即必须预测所有 25 个类,因为该信息可以在多次过去扫描的时间信息中得到。该任务的评估指标仍然与单次扫描情况相同,即,无论过去多少次扫描用于计算结果,我们都会评估当前扫描的平均 IoU。
基准(baselines)。
我们通过将 5 次扫描组合成单个大点云(single, large point cloud)来利用顺序信息,即时间戳 t 处的当前扫描和时间戳 t-1,...t-4 之前的 4 次扫描。我们评估了 DarkNet53Seg 和 TangentConv,因为这些方法可以处理大量点而无需对点云进行下采样,并且仍然可以在合理的时间内进行训练。
Result and Discussion(结果和讨论)。
表 4 显示了可移动类(the movable class)的每类结果和所有类的平均 IoU (mIoU)。对于每种方法,我们在行的上半部分显示不移动的 IoU(无阴影),在行的下半部分显示移动对象的 IoU(阴影)。其余静态类的表现(the performance of the remaining static classes)类似于单次扫描结果,我们参考了包含所有类的表的补充。

表 4:使用一系列过去扫描的 IoU 结果(以 % 为单位)。 阴影格子对应于移动类的 IoU,而无阴影格子是非移动类。
投影方法(the projective methods)比基于点的方法(the point-based methods)表现更好的总体趋势仍然很明显,这也可以归因于单次扫描情况下的大量参数(注:这句结论性语句好像在文中没有支撑,但可能用这个支撑----TangentConv是局部表面上点的切线什么的卷积、DarlkNet53Seg是SqueezeSeg 的拓展且SqueezeSeg 是基于投影的)。这两种方法在分离移动和非移动对象方面都存在困难,这可能是由于我们的设计决定将多个扫描聚合到单个大点云(aggregate mulitiple scans into a single large point cloud)中造成的。结果表明,尤其是骑自行车的人和摩托车的人永远不会被正确地分配到不动的类别,这很可能是这些类的点云通常会更稀疏(which is most likely a consequence from the generally sparser object point clouds)。
我们期望新方法可以通过使用架构的多个输入流(multiple input streams)甚至循环神经网络来明确利用序列信息以解释时间信息(temporal information),这可能再次开辟一条新的研究方向。
5 Evaluation of Semantic Scene Completion(语义场景补全评估)
在利用一系列过去的扫描进行语义点云分割之后,我们现在展示一个利用未来扫描的场景。由于其顺序性,我们的数据集提供了扩展 3D 语义场景补全任务(the task of 3D semantic scene completion)的独特机会。请注意,这是该任务的第一个真实世界户外基准(outdoor benchmark)。现有的点云数据集不能用于解决此任务,因为它们不允许聚合在空间和时间上都足够密集的标记点云(aggregating labeled point clouds that are sufficiently dense in both space and time)。
在语义场景补全中,一个基本问题是获取真实世界数据集的真实标签。在 NYUv2 [48] 的情况下,使用 Kinect 传感器捕获的 RGB-D 图像将 CAD 模型拟合到场景 [45] 中。新方法经常致力于证明它们在更大但合成的 SUNCG 数据集上的有效性 [49]。但是,仍然缺少结合合成数据集的规模和真实世界数据使用(两个特性)的数据集。
在我们提出的数据集的情况下,搭载 LiDAR 的汽车经过场景中的 3D 对象,从而记录它们的背面(backsides),这些背面由于自遮挡(self-occlusion)而在初始扫描中隐藏。这正是语义场景完成所需的信息,因为它包含所有对象的完整 3D 几何信息,而它们的语义由我们的密集注释提供。
Dataset Generation(数据集生成)。
通过在汽车前方的预定义区域(predefined region)中叠加大量未来的激光扫描,我们可以生成与语义场景补全任务相对应的输入和目标对(pairs of inputs and targets,参考图5理解)。正如宋[49]等人提出的那样,我们用于场景补全任务的数据集是 3D 场景的体素化表示(voxelized representation)。
我们选择汽车前方 51.2 m 的体积,每边 25.6 m,高度 6.4 m,体素分辨率为 0.2 m,这导致要预测的体积为 256×256×32 体素。我们基于对体素内所有标记点的多数投票为每个体素分配一个标签。不包含任何点的体素被标记为空。
为了计算哪些体素属于被遮挡的空间(the occluded space),我们通过追踪光线(tracing a ray)来检查汽车的每个姿势,哪些体素对传感器是可见的。一些体素,例如 那些在物体内部或墙后的东西永远是不可见的,所以我们在训练和评估时会忽略它们。
总体而言,我们提取了 19130 对输入和目标体素网格用于训练,815 对用于验证,3992 对用于测试。对于测试集,我们只提供未标记的输入体素网格(unlabel input voxel grid)并保留目标体素网格(target voxel grids)。图 5 显示了输入和目标对的示例。

图 5:左:语义场景补全基准的不完整输入的可视化;请注意,我们显示标签只是为了更好地可视化,但真正的输入是没有任何标签的单个原始体素网格。右图:对应的目标输出表示已完成且完全标记的 3D 场景。
Task and Metrics(任务和指标)。
在语义场景补全中,我们感兴趣的是通过一次初始扫描来预测某个体积内的完整场景。更具体地说,我们使用体素网格作为输入,其中每个体素被标记为空或被占用,具体取决于它是否包含激光测量。对于语义场景补全,需要预测一个体素是否被占用及其在已完成场景中的语义标签。
对于评估,我们遵循 Song[49] 等人的评估协议,并计算场景补全任务的 IoU,它仅将体素分类为被占用或空,即忽略语义标签,以及和用于单次扫描语义分割任务相同的19个类(参见第 4 节)上的语义场景完成任务的 mIoU (参见公式1) 。
State of the art(最先进的)。
早期的方法解决了场景补全的任务,要么没有预测语义 [16],因此无法提供对场景的整体理解,要么试图将固定数量的网格模型拟合到场景几何 [20],这限制了该方法的表现力 。
宋等人 [49] 是第一个以端到端的方式解决语义场景完成任务的人。他们的工作引发了对该领域构建模型(yielding models)的极大兴趣。或结合使用颜色和深度信息 [33, 18] 或通过引入子流形卷积[65] 来解决稀疏3D特征图的问题,或通过部署多阶段粗到细训练方案来提高输出分辨率 [12] (combine the usage of color and depth information [33, 18] or address the problem of sparse 3D feature maps by introducing sub-manifold convolutions [65] or increase the output resolution by deploying a multi-stage coarse to fine training scheme [12]. )。其他工作尝试了新的编码器-解码器 CNN 架构,并通过添加对抗性损失组件(adding adversarial loss components)来改进损失项 [58]。
Baseline Approaches(基准方法)。
我们报告了四种语义场景补全方法的结果。在第一种方法中,我们应用 SSCNet [49] 并使用没有翻转(flipped)的 TSDF 作为输入特征。这对性能的影响很小,但由于更快的预处理[18],显着加快了训练时间。接着我们使用Two Stream(TS3D)方法[18],它利用来自与输入激光扫描(the input laser scan)相对应的 RGB 图像的附加信息。因此,RGB 图像首先由 2D 语义分割网络处理,即使用在 Cityscapes 上训练的 DeepLab v2 (ResNet-101) [9] 方法生成语义分割。来自单次激光扫描的深度信息和从 RGB 图像推断的标签在早期融合中组合在一起。此外,我们分两步修改 TS3D 方法:首先,直接使用基于 LiDAR 的最佳语义分割方法 (DarkNet53Seg) 的标签,其次,通过 SATNet [33] 交换 3D-CNN 主干。
Result and Discuss(结果和讨论)。
表 5 显示了每个基线的结果,而补充中报告了各个类别的结果。TS3D 网络结合了 RGB 图像的 2D 语义分割,其性能类似于仅使用深度信息的 SSCNet。然而,直接在点云上工作的最佳语义分割的使用在语义场景补全(TS3D +DarkNet53Seg)上略胜于 SSCNet。请注意,前三种方法基于 SSCNet 的 3D-CNN 架构,该架构在前向传递中执行 4 倍下采样,因此无法处理场景的细节。在我们的最终方法中,我们将 TS3D + DarkNet53Seg 的 SSCNet-backbone 与 SATNet [33] 交换,它能够处理所需的输出分辨率。由于内存限制,我们在训练期间使用随机裁剪。在推理过程中,我们将每个体积分成六个相等的部分,分别对它们执行场景补全,然后将它们融合。这种方法的性能比基于 SSCNet 的方法好得多。
除了处理目标分辨率之外,当前模型面临的挑战是远场(far field)中激光输入信号的稀疏性,如图 5 所示。为了在远场获得更高分辨率的输入信号,方法必须更有效地利用与每次激光扫描一起提供的高分辨率 RGB 图像的信息。
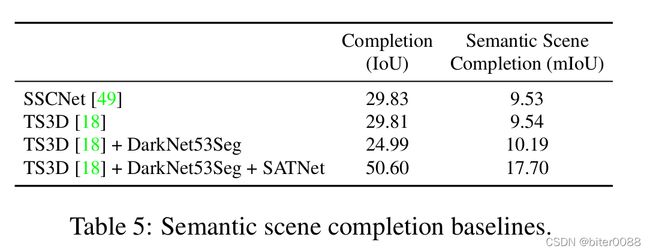
表 5:语义场景完成对照组。
6. Conclusion and Outlook(结论与展望)
在这项工作中,我们提出了一个大规模的数据集,在点云序列的逐点(point-wise)注释中显示出前所未有的规模。 我们为三个任务提供了一系列不同的基准实验:
(i)使用单次扫描的语义分割,
(ii)使用多次扫描的语义分割,以及
(iii)语义场景补全。
在未来的工作中,我们计划在整个序列上提供实例级(instance-level)注释,即,我们希望在扫描中区分不同的对象,但也要随着时间的推移识别相同的对象。这将能够研究序列上的时间实例分割(temporal instance segmentation)。然而,我们也看到了基于我们的标签工作的其他新任务的潜力,例如语义 SLAM 的评估。
Acknowledgements(致谢)
我们感谢所有帮助注释数据的学生。这项工作由德意志研究基金会(DFG,德国研究基金会)资助,根据 FOR 1505 Mapping on Demand、BE 5996/1-1、GA 1927/2-2 和德国卓越战略、EXC-2070 – 390732324(PhenoRob )。
附录部分
A Consistent Labels for LiDAR Sequences(LiDAR 序列的一致标签)

图 6:点云标记工具。 在左上角,用户可以看到图块和红色轨迹指示的传感器路径。
在本节中,我们将更详细地解释我们的点云标记工具的实现,以及我们决定在空间上而非时间上细分序列以获得一致标记的点云序列的基本原理。标签工具本身对于提供具有如此细粒度标签(fine-grained labels)的扫描量至关重要。
总之,我们开发了一个基于 OpenGL 的标签工具,它利用了 GPU 上的并行化。主要挑战是海量点数据的可视化(the visualization of vast amounts of point data),同时还要处理这些数据,同时达到允许标注人员以交互方式标记聚合点云(label interactively the aggregated point clouds)的响应能力(responsiveness)。图 6 显示了我们的点云注释程序,它可视化了超过 2000 万个点的聚合点云。我们提供了广泛的注释工具,如画笔、多边形工具和不同的过滤方法来隐藏选定的标签。即使有这么多点,我们仍然能够保持交互式标注功能。聚合点云内点标签的更改会反映在各个扫描中,这使得标签随着时间的推移保持高度一致性。
由于我们标记了每个点,我们能够标注物体/对象(objects),即使是复杂的遮挡(occlusiona),也比仅仅使用包围体(bounding volumes) [62] 更精确。例如,我们确保汽车下方的地面点被相应地标记,这是通过我们的注释工具的过滤功能实现的。
为了加速搜索必须标记的点,我们使用投影方法来分配标签。为此,我们为每个点确定屏幕上的二维投影(the two-dimensional projection),然后确定该点是否靠近单击位置(the clicked position)(以画笔为例)还是在选定的多边形内。因此,标注人员必须确保他们没有选择一个基本上破坏了的先前分配的点的视图(Therefore, annotators had to ensure that they did not choose a view that essentially destroyed previously assigned points.)。
Tile-Based Labeling(基于图块的标签)。
一个重要的细节是将完整的聚合点云空间细分为图块(也显示在图 6 的左上部分)。最初,我们只是在一个时间戳范围内渲染所有扫描,比如 100-150,然后移动到下一部分,比如 150-200。但是,这很快会导致标签不一致,因为来自这些部分的扫描仍然重叠,因此必须重新标记以匹配之前的标签。此外,由于我们遇到了具有相当大时间距离的闭环(loop closures with a considerable temporal distance),这种重叠甚至可能发生在时间上不接近的部分序列之间,这使任务更加复杂。
因此,很明显,这种确保标签一致的额外努力将导致不合理的复杂注释过程(an unreasonable complicated annotations),从而导致结果不充分(insufficient results)。因此,我们决定在空间上将序列细分为图块,其中每个图块包含与该图块重叠的扫描中的所有点。图块之间边界的一致性是通过图块之间的小重叠来实现的,这使得标签能够始终如一地从一个图块延续到另一个相邻图块。
Moving Objects(移动物体)。
我们标注了所有的运动物体,即汽车、卡车、人、自行车和摩托车手,并且每个运动物体都由不同的类表示,以将其与其对应的非运动类区分开来。在我们的例子中,当用传感器观察物体在某个时间点移动时,我们为它分配了相应的移动类。
由于在聚合从不同传感器位置捕获的扫描时,移动对象会出现在不同的位置,因此我们必须特别注意对移动对象进行注释。当多种类型的车辆在同一车道上行驶时,这尤其具有挑战性,就像在大多数遇到的高速公路场景中一样。我们通过过滤地面点(filtering ground points)或单独标记每个扫描(labeling each scan individually)来注释移动对象,标记汽车和自行车轮胎点或人脚点通常是所必需的。但是,在上述情况下,当多辆不同类型的车辆在同一车道上行驶时,也需要逐个扫描标记(scan-by-scan labeling)。标记移动对象通常是标注图块的第一步,因为这允许注释器过滤所有移动点,然后专注于环境的静态部分。
B Basis of the Dataset(数据集的基础)
我们数据集的基础是来自 KITTI Vision Benchmark [19] 的数据,在撰写本文时,它仍然是自动驾驶中使用的最大数据集合。KITTI 数据集是在不同背景下进行许多实验评估的基础,并且随着时间的推移通过新任务或额外数据进行了扩展。因此,我们决定在这一遗产的基础上再接再厉,同时实现我们的注释与 KITTI Vision Benchmark 的其他部分和任务之间的协同作用。
我们特别决定使用里程计基准(the Odometry Benchmark),以便在此任务中使用注释数据。我们期望在里程计估计(the odometry estimation)中利用语义信息是未来研究的一个有趣途径。此外,KITTI Vision Benchmark 的其他任务也可能从我们的注释和我们将在数据集网站上发布的预训练模型中受益。
尽管如此,我们希望我们的努力和点标记工具的可用性将使其他人能够在未来来自汽车 LiDAR 的公开可用数据集上复制我们的工作。
C Class Definition(类定义)
在标记如此大量的数据的过程中,我们必须在某个时间点决定要标注哪些类。一般来说,我们遵循 Mapillary Vistas 数据集 [39] 和 Cityscapes [10] 数据集的类定义和选择,但对使用的数据源进行了一些简化和调整。
首先,我们没有明确考虑骑摩托车或自行车的人的骑手类别,因为单次扫描中可用点云的密度不足以区分骑车的人。此外,我们仅获得此类类的移动示例,因此无法轻松聚合点云以增加点云的保真度来更容易区分车辆的骑手和车辆。
other-structure、other-vehicle 和 otherobject 类是它们各自根类别下的不清楚情况或缺失类(unclear cases or missing classes)中的后备类(fallback classes),因为这样可以简化标记过程,并且将来可能用于进一步区分这些类别。
标注人员经常注释某些对象或场景的一部分,然后隐藏标记点以避免覆盖或删除标签。因此,在不明确的情况下或缺少特定类的情况下(in ambiguous cases or cases where a specific class was missing)分配后备类(fallback classes)可以简单地隐藏该类以避免覆盖它。如果我们指示标注人员将这些部分标记为未标记,那么将会导致一致地标记点云出现问题。
我们进一步区分了移动和非移动的车辆和人类,即,如果车辆或人类在被激光雷达传感器观察到的某些连续扫描(consecutive scans)中移动,则会获得“移动”标签。
总之,我们注释了 28 个类,所有注释类及其各自的定义列在下一页的表 6 中。
| 类别目录 |
定义 |
|
| ground-related 地面相关 |
road 道路 |
允许汽车行驶的可行驶区域(drivable areas)包括服务车道、自行车道、街道上的交叉区域。只有路面被标记,不包括路缘(curb)。 |
| sidewalk 人行道 |
主要供行人、自行车使用的区域,但不适合开车驾驶。这包括路边(curb)和不允许您以超过 5 公里/小时的速度行驶的空间。私人车道(private driveways)也被标记为人行道;但在这里,汽车也不应以常规速度行驶(例如 30 或 50 公里/小时)。 |
|
| parking 停车场 |
明确用于停车的区域,通过小路缘石(a small curb)与人行道和道路明显分开。如果不清楚,则可以选择其他地面或人行道。车库(garages)被标记为建筑物而不是停车场。 |
|
| other-ground 其他地面 |
每当人行道和地形(terrain)之间的区别不明确时,就会选择此标签。 它包括不适合步行的(铺砌/抹灰)交通岛(traffic islands)。加油站(a gas station)的铺砌部分也不适合停车。 |
|
| structures 建筑物 |
building 建筑物 |
整个建筑包括建筑的墙壁、门、窗、楼梯等。车库算作建筑。 |
| other-structure 其他建筑 |
这包括其他垂直结构,例如隧道墙、桥柱、建筑工地建筑物上的脚手架或带屋顶的公共汽车站。 |
|
| vehicle 车辆 |
car 汽车 |
包括具有连续车身形状的汽车、吉普车、SUV、货车(即驾驶室和货舱为一体)。 |
| truck 卡车 |
卡车、车身与驾驶室分开的厢式货车、皮卡车及其附属拖车。 |
|
| bicycle 自行车 |
没有骑车人或其他乘客的自行车。如果自行车由人驾驶或有人站在车辆附近,我们将其标记为自行车手。 |
|
| motorcycle 摩托车 |
没有司机或其他乘客的摩托车、轻便摩托车。还包括有盖罩的摩托车。如果摩托车是由人驾驶或有人站在车辆附近,我们将其标记为摩托车手。 |
|
| other-vehicle 其他车辆 |
未在基础类别车辆中明确定义的车辆的大篷车、拖车和后备类别。包括供 9 人以上乘坐公共或长途交通工具的巴士。 这进一步包括在轨道上移动的所有车辆,例如电车、火车。 |
|
| nature 自然景观 |
vegetation 植被 |
植被是所有灌木、灌木、树叶(bushes,shrubs,foliage)和其他清晰可辨的植被。 |
| trunk 树干 |
树干被标记为树干,与获得标签植被的树梢(treetop)分开。 |
|
| terrain 地形(先这样理解吧) |
草和所有其他类型的水平蔓延植被(horizontal spreading vegetation),包括土壤。 |
|
| 人类 human |
person 人 |
人类靠自己的腿、坐着或任何不寻常的姿势移动,但不是为了开车。 |
| bicyclist 自行车手 |
人类驾驶自行车或站在自行车附近(在手臂范围内)。我们不区分骑手和骑自行车的人。 |
|
| motorcyclist 摩托车手 |
驾驶摩托车或站在摩托车附近的人(伸手可及的范围内)。 |
|
| object 物体 |
fence 栅栏 |
分隔物,如栅栏、小墙和防撞屏障。 |
| pole 杆 |
灯柱和交通标志杆。 |
|
| traffic sign 交通标志 |
不包括其安装的交通标志。交通标志前后图层中的杂散点也被标记为交通标志,而不是异常值。 |
|
| other-object 其他物体 |
包含广告栏的后备类别。 |
|
| outlier 异常点 |
outlier 异常点 |
异常值是由扫描偏斜的反射或不准确引起的,不清楚这些点的来源。 |
Table 6: Class definitions.(类定义)
D Baseline Setup(基线设置)
我们修改了可用的实现,以便可以在我们的大规模数据集(由于 LiDAR 传感器,点云非常稀疏)上训练和评估这些方法。请注意,到目前为止,这些方法中的大多数仅在小型 RGB-D 室内数据集上进行了评估。
由于某些方法 [40, 41] 的内存限制,我们通过随机采样将单次扫描中的点数限制为 50 000。
对于 SPLATNet,我们使用了[51]中的SPLATNet 3D架构。输入由每个点的3D位置及其法线组成。法线在此之前由给定30个最近的邻点估计得出。
(注:SPLATNet 3D:https://github.com/NVlabs/splatnet)
在 TangentConv中,我们使用了 Semantic3D 的现有配置。我们通过预先计算扫描批次(precomputing scan batches)并添加异步数据加载(asynchronous data loading)来加快训练和验证过程。在训练期间提供了完整的单次扫描。在多扫描实验中,由于内存限制,我们将每批次的点数固定为 500 000,并从单扫描权重(the single scan weights)开始训练。
(注:TangentConv:https://github.com/tatarchm/tangent_conv)
对于 SqueezeSeg [60] 及其Darknet backbone等效物,我们以与原始 SqueezeSeg 方法相同的方式使用扫描的球形投影。对应于传感器的单独光束,投影包含 64 条高线;SqueezeSeg 配置时仅使用前 90° 和 512 水平分辨率,我们外推到使用 2048 进行整个扫描。因为在这个采样过程中有些点是重复的,所以我们总是保持最接近的范围值,并且在每次扫描的推断中,我们迭代整个点列表并检查它在输出网格中的语义值。
表 7 中给出了使用参数的概述。我们还提供了训练的 epoch 的数量,以及我们是否可以获得似乎在给定时间内收敛的结果。

表 7:方法统计。 epochs上面的* 表示它是从单扫描版本的预训练权重开始的。(converged:收敛的)
E Results using Multiple Scans(使用多次扫描的结果)
表 8 中列出了多次扫描实验的每类 IoU 的完整结果。正如正文中已经提到的,我们通常观察到静态类的 IoU(the IoU of static classes) 基本上不受过去多次扫描的可用性的影响。在某种程度上,某些类的 IoU 略有增加。mIoU 方面的性能下降主要是由于准确区分移动类和非移动类的额外挑战造成的。

表 8:使用一系列过去扫描的 IoU 结果(以 % 为单位)。
F Semantic Scene Completion(语义场景补全)

表 9:场景补全的结果和语义场景完成的分类结果(以 % 为单位)。
表 9 显示了语义场景完成的分类结果以及场景完成的精度和召回率。可以看出 TS3D + DarkNet53Seg 的性能略好于 SSCNet 和 TS3D。请注意,Dark-Net53Seg 已经在与语义场景完成所需的完全相同的类上进行了预训练。另一方面,TS3D 使用在 Cityscapes [10] 数据集上预训练的 DeepLab v2 (ResNet-101) [9],它不区分其他地面、停车场或后备箱等类别。另一个原因可能是投影回点云的 2D 语义标签不是很准确,尤其是在对象边界处,标签经常渗入远处的对象。这是因为在 2D 投影中,它们彼此靠近,这是投影方法固有的问题。最好的方法(TS3D + Dark-Net53Seg + SATNet)明显优于其他方法(场景补全+20.77% IoU,语义场景补全+7.51% mIoU)。如上所述,它是唯一能够产生高分辨率输出的方法。然而,这种方法存在巨大的内存消耗。因此,在训练期间,输入体积(the input volume)被随机裁剪为网格大小为 64×64×32 的体积,而在推理过程中,每个体积被分成 6 个大小为 90×138×32 的重叠块,单独执行推理。随后将各个块融合以获得最终结果。图 7 显示了这种方法的示例结果。
图 7:语义场景补全方法 TS3D + DarkNet53Seg + SATNet 的定性结果。左:输入体积。中间:网络预测。右:真值。由于内存限制,必须在重叠子体积上分六个步骤进行推理。子体积随后被融合以获得最终结果。
自行车、摩托车、摩托车手和人等稀有类不被识别或几乎不被识别。这表明这些类可能很难识别,因为它们代表 SemanticKITTI 数据中的一个小而罕见的信号。
G Qualitative Results(定性结果)


Figure 8: Examples of inference for all methods. The point clouds were projected to 2D using a spherical projection to make the comparison easier.
图 8:所有方法的推理示例。使用球形投影将点云投影到 2D 以使比较更容易。
图8 显示了对验证数据进行扫描的评估基线方法的定性结果。在这里,我们显示了结果的球面投影,以便更轻松地比较结果。
随着平均 IoU(从上到下)性能的提高,另请参见论文的表 2,我们看到地面点更好地分为人行道、道路和停车场。特别是,停车区需要大量上下文信息(textual information)以及来自相邻点的信息,因为通常一个小的路缘石可以将停车区与道路区分开来。
一般来说,对于较小的物体,如图像右侧的路灯杆,我们肯定可以看到精度有所提高,这表明容量最大的模型的额外参数(DarkNet21Seg 为 2500 万,DarkNet53Seg 为 5000 万) 需要被用来区分较小的类和具有少量示例的类。
H Dataset and Baseline Access API(数据集和基准访问 API)
除了注释和标签工具,我们还提供了一个用 Python 实现的公共 API。
我们的标签工具旨在允许用户轻松扩展此数据集,并为其他目的生成其他数据,与我们的标签工具相比,此 API 旨在用于轻松访问数据、计算统计数据、评估指标以及访问多个不同的最先进的语义分割实现方法。我们希望这个 API 将作为实现新点云语义分割方法的基准,并提供一个通用框架来评估它们,并将它们与其他方法进行更透明的比较。选择 Python 作为 API 的底层语言是因为它是当前深度学习框架开发人员前端的首选语言,因此也是深度学习从业者的首选语言。
图 9 给出了标记序列的概述,显示了整个序列的估计轨迹和聚合点云。
图 9:标记序列和轨迹的定性概述。
部分笔记
1 true positive, true negative, false positive, false negative
| predicted \ actual |
1 |
0 |
| 1 |
true positive |
false positive |
| 0 |
false negative |
true negative |
true positive: 预测结果是正确的,且真实值就是positive
true negative: 预测结果是正确的,且真实值就是negative
false positive: 预测结果是错误的,预测结果是positive,但真实值是negative
false negative:预测结果是错误的,预测结果是negative,但真实值是positive
参考链接:https://blog.csdn.net/u011238634/article/details/9405413
2 交并比IoU公式理解

3 @meng
Reference(参考文献)
[1] Anuraag Agrawal, Atsushi Nakazawa, and Haruo Takemura. MMM-classification of 3D Range Data. In Proc. of the IEEE Intl. Conf. on Robotics & Automation (ICRA), 2009. 5
[2] Dragomir Anguelov, Ben Taskar, Vassil Chatalbashev, Daphne Koller, Dinkar Gupta, Geremy Heitz, and Andrew Ng. Discriminative Learning of Markov Random Fields for Segmentation of 3D Scan Data. In Proc. of the IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), pages 169–176, 2005. 5
[3] Iro Armeni, Alexander Sax, Amir R. Zamir, and Silvio Savarese. Joint 2D-3D-Semantic Data for Indoor Scene Understanding. arXiv preprint, 2017. 2
[4] Jens Behley, Kristian Kersting, Dirk Schulz, Volker Steinhage, and Armin B. Cremers. Learning to Hash Logistic Regression for Fast 3D Scan Point Classification. In Proc. of the IEEE/RSJ Intl. Conf. on Intelligent Robots and Systems (IROS), pages 5960–5965, 2010. 5
[5] Jens Behley and Cyrill Stachniss. Efficient Surfel-Based SLAM using 3D Laser Range Data in Urban Environments. In Proc. of Robotics: Science and Systems (RSS), 2018. 3
[6] Jens Behley, Volker Steinhage, and Armin B. Cremers. Performance of Histogram Descriptors for the Classification of 3D Laser Range Data in Urban Environments. In Proc. of the IEEE Intl. Conf. on Robotics & Automation (ICRA), 2012. 2, 3
[7] Alexandre Boulch, Joris Guerry, Bertrand Le Saux, and Nicolas Audebert. SnapNet: 3D point cloud semantic labeling with 2D deep segmentation networks. Computers & Graphics, 2017. 5
[8] Angel X. Chang, Thomas Funkhouser, Leonidas J. Guibas, Pat Hanrahan, Qixing Huang, Zimo Li, Silvio Savarese, Manolis Savva, Shuran Song, Hao Su, Jianxiong Xiao, Li Yi, and Fisher Yu. ShapeNet: An Information-Rich 3D Model Repository. Technical Report arXiv:1512.03012 [cs.GR], Stanford University and Princeton University and Toyota Technological Institute at Chicago, 2015. 2, 5
[9] Liang-Chieh Chen, George Papandreou, Iasonas Kokkinos, Kevin Murphy, and Alan L. Yuille. DeepLab: Semantic Image Segmentation withDeep Convolutional Nets, Atrous Convolution,and Fully Connected CRFs. IEEE Transactions on Pattern Analysis and Machine Intelligence (PAMI), 40(4):834–848, 2018. 8, 14
[10] Marius Cordts, Mohamed Omran, Sebastian Ramos, Timo Rehfeld, Markus Enzweiler, Rodrigo Benenson, Uwe Franke, Stefan Roth, and Bernt Schiele. The Cityscapes Dataset for Semantic Urban Scene Understanding. In Proc. of the IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2016. 2, 3, 4, 6, 12, 14
[11] Angela Dai, Angel X. Chang, Manolis Savva, Maciej Halber, Thomas Funkhouser, and Matthias Nießner. ScanNet: Richly-annotated 3D Reconstructions of Indoor Scenes. In Proc. of the IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2009. 2
[12] Angela Dai, Daniel Ritchie, Martin Bokeloh, Scott Reed,Jürgen Sturm, and Matthias Nießner. ScanComplete: Large-Scale Scene Completion and Semantic Segmentation for 3D Scans. In Proc. of the IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2018. 2, 8
[13] Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. ImageNet: A Large-Scale Hierarchical Image Database. In Proc. of the IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2009. 2
[14]Francis Engelmann, Theodora Kontogianni, Jonas Schult, and Bastian Leibe. Know What Your Neighbors Do: 3D Semantic Segmentation of Point Clouds. arXiv preprint, 2018.5
[15]Mark Everingham, S.M. Ali Eslami, Luc van Gool, Christopher K.I. Williams, John Winn, and Andrew Zisserman. The Pascal Visual Object Classes Challenge a Retrospective. International Journal on Computer Vision (IJCV), 111(1):98–136, 2015. 4
[16]Michael Firman, Oisin Mac Aodha, Simon Julier, and Gabriel J. Brostow. Structured Prediction of Unobserved Voxels From a Single Depth Image. In Proc. of the IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), pages 5431–5440, 2016. 7
[17]Adrien Gaidon, Qiao Wang, Yohann Cabon, and Eleonora Vig. Virtual Worlds as Proxy for Multi-Object Tracking Analysis. In Proc. of the IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2016. 3
[18]Martin Garbade, Yueh-Tung Chen, J. Sawatzky, and Juergen Gall. Two Stream 3D Semantic Scene Completion. In Proc. of the IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR) Workshops, 2019. 7, 8
[19]Andreas Geiger, Philip Lenz, and Raquel Urtasun. Are we ready for Autonomous Driving? The KITTI Vision Benchmark Suite. In Proc. of the IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), pages 3354–3361, 2012. 1, 2, 3, 12
[20]Andres Geiger and Chaohui Wang. Joint 3d Object and Lay- out Inference from a single RGB-D Image. In Proc. of the German Conf. on Pattern Recognition (GCPR), pages 183–195, 2015. 7
[21]Benjamin Graham, Martin Engelcke, and Laurens van der Maaten. 3D Semantic Segmentation with Submanifold Sparse Convolutional Networks. In Proc. of the IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2018. 5
[22]Fabian Groh, Patrick Wieschollek, and Hendrik Lensch. Flex-Convolution (Million-Scale Pointcloud Learning Beyond Grid-Worlds). In Proc. of the Asian Conf. on Computer Vision (ACCV), Dezember 2018. 5
[23]Timo Hackel, Nikolay Savinov, Lubor Ladicky, Jan D. Wegner, Konrad Schindler, and Marc Pollefeys. SEMAN-TIC3D.NET: A new large-scale point cloud classification benchmark. In ISPRS Annals of the Photogrammetry, Remote Sensing and Spatial Information Sciences, volume IV-1-W1, pages 91–98, 2017. 2
[24]Binh-Son Hua, Quang-Hieu Pham, Duc Thanh Nguyen, Minh-Khoi Tran, Lap-Fai Yu, and Sai-Kit Yeung. SceneNN: A Scene Meshes Dataset with aNNotations. In Proc. of the Intl. Conf. on 3D Vision (3DV), 2016. 2
[25]Binh-Son Hua, Minh-Khoi Tran, and Sai-Kit Yeung. Point-wise Convolutional Neural Networks. In Proc. of the IEEE Conf. on Computer Vision and Pattern Recognition (CVPR),018. 5
[26]Jing Huang and Suya You. Point Cloud Labeling using 3D Convolutional Neural Network. In Proc. of the Intl. Conf. on Pattern Recognition (ICPR), 2016. 5
[27]Varun Jampani, Martin Kiefel, and Peter V. Gehler. Learning Sparse High Dimensional Filters: Image Filtering, Dense CRFs and Bilateral Neural Networks. In Proc. of the IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2016. 5
[28]Mingyang Jiang, Yiran Wu, and Cewu Lu. PointSIFT: A SIFT-like Network Module for 3D Point Cloud Semantic Segmentation. arXiv preprint, 2018. 5
[29]Andrew E. Johnson and Martial Hebert. Using spin images for effcient object recognition in cluttered 3D scenes. Trans. on Pattern Analysis and Machine Intelligence (TPAMI), 21(5):433–449, 1999. 5
[30]Roman Klukov and Victor Lempitsky. Escape from Cells: Deep Kd-Networks for the Recognition of 3D Point Cloud Models. In Proc. of the IEEE Intl. Conf. on Computer Vision (ICCV), 2017. 5
[31]Loic Landrieu and Martin Simonovsky. Large-scale Point Cloud Semantic Segmentation with Superpoint Graphs. In Proc. of the IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2018. 5, 6, 15
[32]Wenbin Li, Sajad Saeedi, John McCormac, Ronald Clark, Dimos Tzoumanikas, Qing Ye, Yuzhong Huang, Rui Tang, and Stefan Leutenegger. InteriorNet: Mega-scale Multi-sensor Photo-realistic Indoor Scenes Dataset. In Proc. of the British Machine Vision Conference (BMVC), 2018. 2
[33]Shice Liu, Yu Hu, Yiming Zeng, Qiankun Tang, Beibei Jin, Yainhe Han, and Xiaowei Li. See and Think: Disentangling Semantic Scene Completion. In Proc. of the Conf. on Neural Information Processing Systems (NeurIPS), pages 261–272, 2018. 7, 8
[34]Daniel Maturana and Sebastian Scherer. VoxNet: A 3D Convolutional Neural Network for Real-Time Object Recognition. In Proc. of the IEEE/RSJ Intl. Conf. on Intelligent Robots and Systems (IROS), 2015. 5
[35]John McCormac, Ankur Handa, Stefan Leutenegger, and Andrew J. Davison. SceneNet RGB-D: Can 5M Synthetic Images Beat Generic ImageNet Pre-training on Indoor Segmentation? In Proc. of the IEEE Intl. Conf. on Computer Vision (ICCV), 2017. 2
[36]Daniel Munoz, J. Andrew Bagnell, Nicolas Vandapel, and 、 [30]Martial Hebert. Contextual Classification with Functional Max-Margin Markov Networks. In Proc. of the IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2009. 2, 5
[37]Daniel Munoz, Nicholas Vandapel, and Marial Hebert. Directional Associative Markov Network for 3-D Point Cloud Classification. In Proc. of the International Symposium on 3D Data Processing, Visualization and Transmission (3DPVT), pages 63–70, 2008. 5
[38]Daniel Munoz, Nicholas Vandapel, and Martial Hebert. On-board Contextual Classification of 3-D Point Clouds with Learned High-order Markov Random Fields. In Proc. of the IEEE Intl. Conf. on Robotics & Automation (ICRA), 2009. 5
[39] Gerhard Neuhold, Tobias Ollmann, Samuel Rota Bulo, and Peter Kontschieder. The Mapillary Vistas Dataset for Semantic Understanding of Street Scenes. In Proc. of the IEEE Intl. Conf. on Computer Vision (ICCV), 2017. 2, 3, 12
[40] Charles R. Qi, Hao Su, Kaichun Mo, and Leonidas J. Guibas. PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation. In Proc. of the IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2017. 5, 6, 14, 15
[41] Charles R. Qi, Li Yi, Hao Su, and Leonidas J. Guibas. PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space. In Proc. of the Conf. on Neural Information Processing Systems (NeurIPS), 2017. 5, 6, 14, 15
[42] Joseph Redmon and Ali Farhadi. YOLOv3: An Incremental Improvement. arXiv preprint, 2018. 5
[43] Dario Rethage, Johanna Wald, Jürgen Sturm, Nassir Navab, and Frederico Tombari. Fully-Convolutional Point Networks for Large-Scale Point Clouds. Proc. of the European Conf. on Computer Vision (ECCV), 2018. 5
[44] Gernot Riegler, Ali Osman Ulusoy, and Andreas Geiger. OctNet: Learning Deep 3D Representations at High Resolutions. In Proc. of the IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2017. 5
[45] Jason Rock, Tanmay Gupta, Justin Thorsen, JunYoung Gwak, Daeyun Shin, and Derek Hoiem. Completing 3D Object Shape from One Depth Image. In Proc. of the IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2015. 7
[46] German Ros, Laura Sellart, Joanna Materzynska, David Vazquez, and Antonio Lopez. The SYNTHIA Dataset: A Large Collection of Synthetic Images for Semantic Segmentation of Urban Scenes. In Proc. of the IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), June 2016. 2
[47] Xavier Roynard, Jean-Emmanuel Deschaud, and Francois Goulette. Paris-Lille-3D: A large and high-quality groundtruth urban point cloud dataset for automatic segmentation and classification. Intl. Journal of Robotics Research (IJRR), 37(6):545–557, 2018. 2, 3
[48] Nathan Silberman, Derek Hoiem, Pushmeet Kohli, and Rob Fergus. Indoor Segmentation and Support Inference from RGBD Images. In Proc. of the European Conf. on Computer Vision (ECCV), 2012. 2, 5, 7
[49] Shuran Song, Fisher Yu, Andy Zeng, Angel X. Chang, Manolis Savva, and Thomas Funkhouser. Semantic Scene Completion from a Single Depth Image. In Proc. of the IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2017. 7, 8
[50] Bastian Steder, Giorgio Grisetti, and Wolfram Burgard. Robust Place Recognition for 3D Range Data based on Point Features. In Proc. of the IEEE Intl. Conf. on Robotics & Automation (ICRA), 2010. 2
[51] Hang Su, Varun Jampani, Deqing Sun, Subhransu Maji, Evangelos Kalogerakis, Ming-Hsuan Yang, and Jan Kautz. SPLATNet: Sparse Lattice Networks for Point Cloud Processing. In Proc. of the IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2018. 5, 6, 14, 15
[52] Maxim Tatarchenko, Jaesik Park, Vladen Koltun, and QianYi Zhou. Tangent Convolutions for Dense Prediction in 3D. In Proc. of the IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2018. 5, 6, 7, 15
[53] Lyne P. Tchapmi, Christopher B. Choy, Iro Armeni, Jun Young Gwak, and Silvio Savarese. SEGCloud: Semantic Segmentation of 3D Point Clouds. In Proc. of the Intl. Conf. on 3D Vision (3DV), 2017. 5
[54] Gusi Te, Wei Hu, Zongming Guo, and Amin Zheng. RGCNN: Regularized Graph CNN for Point Cloud Segmentation. arXiv preprint, 2018. 5
[55] Antonio Torralba and Alexei A. Efros. Unbiased Look at Dataset Bias. In Proc. of the IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2011. 2, 3
[56] Rudolph Triebel, Krisitian Kersting, and Wolfram Burgard. Robust 3D Scan Point Classification using Associative Markov Networks. In Proc. of the IEEE Intl. Conf. on Robotics & Automation (ICRA), pages 2603–2608, 2006. 5
[57] Shenlong Wang, Simon Suo, Wei-Chiu Ma, Andrei Pokrovsky, and Raquel Urtasun. Deep Parametric Continuous Convolutional Neural Networks. In Proc. of the IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2018. 3
[58] Yida Wang, Davod Tan Joseph, Nassir Navab, and Frederico Tombari. Adversarial Semantic Scene Completion from a Single Depth Image. In Proc. of the Intl. Conf. on 3D Vision (3DV), pages 426–434, 2018. 8
[59] Zongji Wang and Feng Lu. VoxSegNet: Volumetric CNNs for Semantic Part Segmentation of 3D Shapes. arXiv preprint, 2018. 5
[60] Bichen Wu, Alvin Wan, Xiangyu Yue, and Kurt Keutzer. SqueezeSeg: Convolutional Neural Nets with Recurrent CRF for Real-Time Road-Object Segmentation from 3D LiDAR Point Cloud. In Proc. of the IEEE Intl. Conf. on Robotics & Automation (ICRA), 2018. 5, 6, 14, 15
[61] Bichen Wu, Xuanyu Zhou, Sicheng Zhao, Xiangyu Yue, and Kurt Keutzer. SqueezeSegV2: Improved Model Structure and Unsupervised Domain Adaptation for Road-Object Segmentation from a LiDAR Point Cloud. Proc. of the IEEE Intl. Conf. on Robotics & Automation (ICRA), 2019. 5, 6
[62] Jun Xie, Martin Kiefel, Ming-Ting Sun, and Andreas Geiger. Semantic Instance Annotation of Street Scenes by 3D to 2D Label Transfer. In Proc. of the IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2016. 11
[63] Xuehan Xiong, Daniel Munoz, J. Andrew Bagnell, and Martial Hebert. 3-D Scene Analysis via Sequenced Predictions over Points and Regions. In Proc. of the IEEE Intl. Conf. on Robotics & Automation (ICRA), pages 2609–2616, 2011. 5
[64] Wei Zeng and Theo Gevers. 3DContextNet: K-d Tree Guided Hierarchical Learning of Point Clouds Using Local and Global Contextual Cues. arXiv preprint, 2017. 5
[65] Jiahui Zhang, Hao Zhao, Anbang Yao, Yurong Chen, Li Zhang, and Hongen Liao. Efficient Semantic Scene Completion Network with Spatial Group Convolution. In Proc. of the European Conf. on Computer Vision (ECCV), pages 733–749, 2018. 8
[66] Richard Zhang, Stefan A. Candra, Kai Vetter, and Avideh Zakhor. Sensor Fusion for Semantic Segmentation of Urban Scenes. In Proc. of the IEEE Intl. Conf. on Robotics & Automation (ICRA), 2015. 2