树模型:决策树、随机森林(RF)、AdaBoost、GBDT、XGBoost、LightGBM和CatBoost算法区别及联系
一、算法提出时间
1966年,决策树算法起源于E.B.Hunt等人提出。
1979年,Quinlan(罗斯.昆兰)提出了ID3算法,掀起了决策树研究的高潮,让决策树成为机器学习主流算法。
1993年,Quinlan(罗斯.昆兰)提出了C4.5算法。
1995年,Freund等人提出AdaBoost算法。
1999年,Friedman在其论文中最早提出GBDT。
2001年,Breiman提出随机森林算法。
2014 年 3 月,XGBOOST 最早作为研究项目,由陈天奇提出。
2017 年 1 月,微软发布首个稳定版 LightGBM。
2017 年 4 月,俄罗斯顶尖技术公司 Yandex 开源 CatBoost。
二、树模型算法对比
模型集成学习(EL, Ensemble Learning)方法有:Bagging(装袋,各树模型独立,最后投票确定(回归则求平均)。如随机森林算法),Boosting(提升,当前树模型依赖上一个模型。如,AdaBoost,GBDT及基于它的树模型),Stacking(堆叠,多个模型基础上组合一个更高层的模型。首先我们先训练多个不同的模型,然后再以之前训练的各个模型的输出为输入来训练一个模型,以得到一个最终的输出。可能有过拟合风险,可用交叉验证法)。集成方法可以弥补弱模型的性能,但需要更多的计算和参数。对比现在的深度学习算法,Boosting 算法,在训练样本量有限、所需训练时间较短、缺乏调参知识的场景中,它们依然拥有绝对优势。因此,它们仍然是中小规模数据集上首选使用的模型。
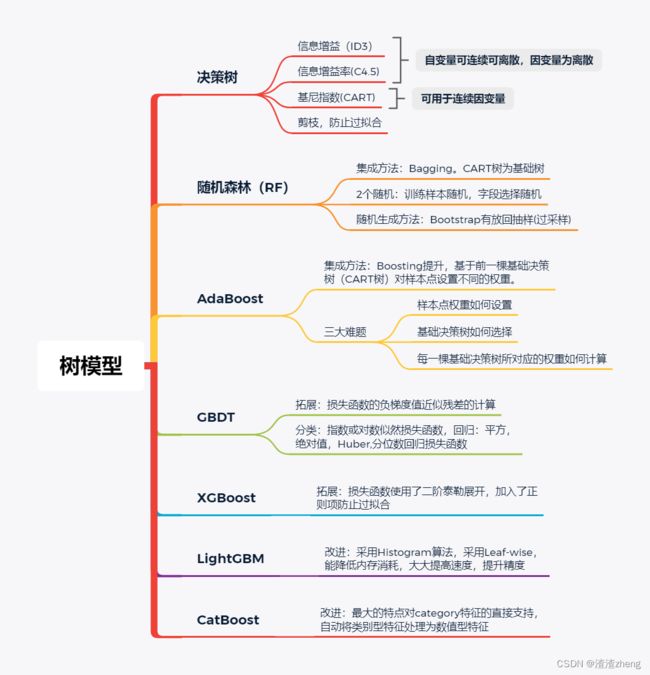
决策树
1、ID3和C4.5是多分支的决策树,CART为二分支决策树。
2、自变量对因变量的影响程度,信息增益,基尼系数下降的越快,自变量对因变量的影响就越强。
3、基础决策树容易产生过拟合的情况,在训练集上有很好的预测精度,在测试集上效果不明显。为解决此问题,可以考虑剪枝处理或采用随机森林算法。
4、剪枝包括预剪枝和后剪枝。预剪枝是在树生长过程中就进行必要的剪枝,如限制树的最大深度。后剪枝是树充分生长前提下再返工修剪。常用有误差降低剪枝法(自底向上),悲观剪枝法(自顶向下),代价复杂度剪枝法。
随机森林(RF)
1、随机森林的随机性体现在两个方面,一是每棵树的训练样本是随机的,二是树中每个节点的分裂字段也是随机选择的。
2、这里随机选择采用Bootstrap抽样法(过采样),它是有放回的抽样。从中抽取k个数据集,即k棵树,每棵树是相互独立的,最后采用投票法,将最高得票的类别用作最终判别。(集成方法为Bagging方法)
3、RF的随机抽样使得树与树之间没有太多关联性,可能导致拟合效果达到瓶颈,主要降低模型方差。
AdaBoost
1、不同于RF,AdaBoost基于前一棵基础决策树对样本点设置不同的权重,如果在前一棵基础决策树中将某样本点预测错误,就会增大该样本点的权重,否则相应降低样本点的权重,进而再构建下一棵基础决策树,更加关注权重大的样本点。
2、如果将所有训练样本点带入损失函数中,一定存在一个最佳的权重和决策树,使得损失函数尽量最大化地降低。主要降低模型偏差。
梯度提升决策树(GBDT)
1、梯度提升树(GBDT)为提升算法的拓展版,原始提升树中,损失函数为平方损失和指数损失,当损失函数为一般的函数(如绝对值损失,Huber损失函数),目标值的求解会相对复杂很多。
2、利用损失函数的负梯度值近似残差的计算就是GBDT的拓展,使得目标函数的求解更为方便。损失函数一阶泰勒展开。
XGBoost
1、XGBoost,传统GBDT发展过来,损失函数使用了二阶泰勒展开,可以更为精准的逼近真实的损失函数。损失函数支持自定义,只需要新的损失函数二阶可导。
2、损失函数加入了正则项,用来控制模型复杂度,因而有利于模型获得更低的方差,防止过拟合。
3、支持并行计算(树之间虽然是串联的,并行是特征维度的并行,在训练之前,每个特征按特征值对样本进行预排序,并存储为block结构),支持多种类型的基分类器(比如线性分类器),支持建模字段的随机选择。
LightGBM和CatBoost则是在XGBoost基础上做了进一步的改进优化
LightGBM
1、Histogram算法。将连续的浮点型特征值离散化成K个整数。加速,且内存减少。
2、带深度限制的Leaf-wise的叶子生长策略。它是一种更为高效的策略,每次从当前所有叶子中,找到分裂增益最大的一个叶子,然后分裂,如此循环。相比XGBoost 的Level-wise不加区分的对待同一层的叶子,实际上很多叶子的分裂增益较低,它比Level-wise降低了很多没必要的开销。增加了一个最大深度的限制,在保证高效率的同时防止过拟合。
3、GOSS(gradient-based one side sampling)的方法来选择训练集,梯度大的样本会直接被保留,用于下一颗树的训练,梯度较小的样本通过采样的方式来决定是否进入到下一轮的训练样本中。
CatBoost
1、CatBoost,基于boosting的梯度提升树模型框架,最大的特点对类别型(category)特征的直接支持,甚至支持字符串类型的特征。自动将类别型特征处理为数值型特征。而LightGBM中则需要指定类别特征名称,算法才可对其自动进行处理。
2、Catboost对类别特征进行组合,极大的丰富了特征维度。
3、采用排序提升的方法对抗训练集中的噪声点,从而避免梯度估计的偏差,进而解决预测偏移的问题。
4、采用了完全对称树作为基模型。
不是越新的算法就是最好的,针对不同的问题,各个算法模型的表现性能可能有所不同。根据无免费午餐定理,没有一种算法能够在所有问题上都取得最好的结果。对于自己的问题,可以多尝试几个模型验证效果。