极智AI | 再谈昇腾CANN量化
欢迎关注我的公众号 [极智视界],获取我的更多笔记分享
大家好,我是极智视界,本文介绍一下 再谈昇腾CANN量化。
在上一篇已经介绍了昇腾CANN量化的原理,对于原理或公式推导有兴趣的同学可以去看一看:《谈谈昇腾CANN量化》。这篇咱们继续,来谈谈昇腾CANN量化的命令行操作。
要进行量化操作,首先要安装好量化环境,这里先简单介绍一下量化环境的安装:
# (1) Anacona3安装,用conda管理python环境,略过
# (2) conda创建amct环境,python版本3.7.5
conda create -n amct_py375 python=3.7.5
# (3) 激活conda环境
conda activate amct_py375
# (4) 安装onnx=1.8.0,onnxruntime=1.6.0,protobuf=3.11.3
pip install -i https://pypi.douban.com/simple onnx=1.8.0 onnxruntime=1.6.0 protobuf=3.11.3
# (5) 下载Ascend-cann-amct_{software version}_{arch}.tar.gz并解压
tar -zxvf Ascend-cann-amct_{software version}_{arch}.tar.gz
# (6) 安装amct_onnx-{version}-py3-none-linux_{arch}.whl ==> 以onnx为例
pip install amct_onnx-{version}-py3-none-linux_{arch}.whl
# (7) 编译并安装自定义算子包
tar -zxvf amct_onnx_op.tar.gz
## 解压后目录
## amct_onnx_op
## |--inc
## |--src
## |--setup.py
cd amct_onnx_op
python setup.py build
# (8) 验证amct_onnx是否安装成功
amct_onnx需要注意的是:在编译自定义算子包前,在amct_onnx_op/inc 里面还需要手动下载四个头放进去,下载路径:https://github.com/microsoft/onnxruntime/tree/v1.6.0/include/onnxruntime/core/session(注意版本的对应,否则在执行amct_onnx时会出现segmentation fault)。
四个头包括:
onnxruntime_cxx_api.honnxruntime_cxx_inline.honnxruntime_c_api.honnxruntime_session_options_config_keys.h
这样就完成了CANN量化工具的安装,接着来看命令行的方式怎么使用。主要包括两个方面:(1) 量化数据集的制作;(2) 命令行量化。
首先来说量化数据集的制作,先把量化图片放在一个叫images的文件夹里面,然后使用如下脚本生成calibration.bin:
import os
import numpy as np
import cv2
PATH = os.path.realpath('./')
IMAGE_PATH = os.path.join(PATH, './images')
BIN_PATH = os.path.join(PATH, './calibration')
BIN_FILE = os.path.join(BIN_PATH, 'calibration.bin')
# 前处理参数
MEAN = [0.485, 0.456, 0.406]
STD = [0.229, 0.224, 0.225]
CALIBRATION_SIZE = 16
def get_labels_from_txt(label_file):
"""Read all images' name and label from label_file"""
image_names = []
labels = []
label_file = os.path.realpath(label_file)
with open(label_file, 'r') as fid:
lines = fid.readlines()
for line in lines:
image_names.append(line.split(' ')[0])
labels.append(int(line.split(' ')[1]))
return image_names, labels
# h、w可自定义
def prepare_image_input(images, height=256, width=256, crop_size=224):
"""Read image files to blobs [batch_size, 3, 224, 224]"""
input_array = np.zeros((len(images), 3, crop_size, crop_size), np.float32)
mean = MEAN
std = STD
imgs = np.zeros((len(images), 3, height, width), np.float32)
for index, im_file in enumerate(images):
im_data = cv2.imread(im_file)
im_data = cv2.resize(
im_data, (256, 256), interpolation=cv2.INTER_CUBIC)
cv2.cvtColor(im_data, cv2.COLOR_BGR2RGB)
imgs[index] = im_data.transpose(2, 0, 1).astype(np.float32)
h_off = int((height - crop_size) / 2)
w_off = int((width - crop_size) / 2)
input_array = imgs[:, :, h_off:(h_off + crop_size),
w_off:(w_off + crop_size)]
# trans uint8 image data to float
input_array /= 255
# do channel-wise reduce mean value
for channel in range(input_array.shape[1]):
input_array[:, channel, :, :] -= mean[channel]
# do channel-wise divide std
for channel in range(input_array.shape[1]):
input_array[:, channel, :, :] /= std[channel]
return input_array
def process_data():
"""process data"""
# prepare cur batch data
image_names, labels = get_labels_from_txt(
os.path.join(IMAGE_PATH, 'image_label.txt'))
if len(labels) < CALIBRATION_SIZE:
raise RuntimeError(
'num of image in {} is less than total_num{}'
.format(IMAGE_PATH, CALIBRATION_SIZE))
labels = labels[0:CALIBRATION_SIZE]
image_names = image_names[0:CALIBRATION_SIZE]
image_names = [
os.path.join(IMAGE_PATH, image_name) for image_name in image_names
]
input_array = prepare_image_input(image_names)
return input_array
def main():
"""process image and save it to bin"""
input_array = process_data()
if not os.path.exists(BIN_PATH):
os.mkdir(BIN_PATH)
input_array.tofile(BIN_FILE)
if __name__ == '__main__':
main()在执行完上述量化脚本后,会生成一个输入数据calibration.bin,然后可以使用命令行进行量化。基本量化命令如下:
amct_onnx calibration --model {model}.onnx --input_shape "input:1,3,224,224" --data_type "float32" --data_dir ./calibration/ --save_path ./results量化执行成功后,会在results目录下生成可用的量化模型results_deploy_model.onnx,并附有一些量化监督文件、仿真文件和量化日志。下面是量化模型的局部节点截图,可以看到包含了量化节点和解量化节点。

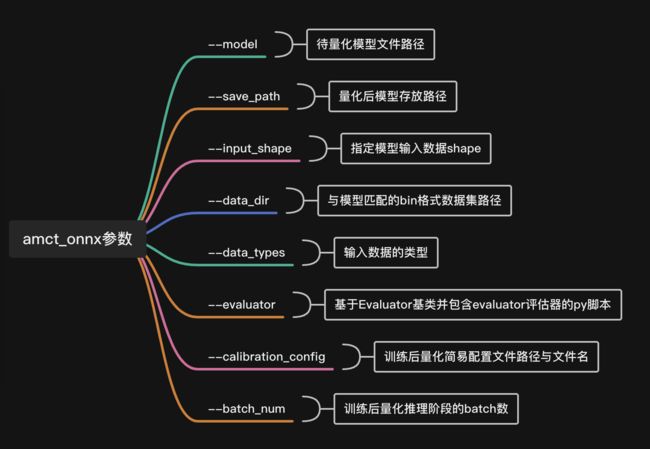
关于amct_onnx命令行的参数,我也进行了整理,如下:
当生成了deploy model后,就可以进一步使用atc工具进行om模型的转换和部署了。
下篇咱们再来说说CANN的量化的python API。
好了,以上分享再谈昇腾CANN量化,希望我的分享能对你的学习有一点帮助。
【极智视界】
《极智AI | 再谈昇腾CANN量化》

搜索关注我的微信公众号「极智视界」,获取我的更多经验分享,让我们用极致+极客的心态来迎接AI !