全同态加密:BGV
参考文献:
- Brakerski Z, Vaikuntanathan V. Efficient fully homomorphic encryption from (standard) LWE[J]. SIAM Journal on computing, 2014, 43(2): 831-871.
- Brakerski Z, Gentry C, Vaikuntanathan V. (Leveled) fully homomorphic encryption without bootstrapping[J]. ACM Transactions on Computation Theory (TOCT), 2014, 6(3): 1-36.
- Peikert C. A decade of lattice cryptography[J]. Foundations and trends® in theoretical computer science, 2016, 10(4): 283-424.
文章目录
- 基础知识
- BGV
-
- Basic Encryption Scheme
- Homomorphic Operations
- Key Switching
- Modulus Switching
- (Leveled) FHE Based on GLWE without Bootstrapping
- Optimizations
-
- Batching
- Bootstrapping as an Optimization
- Batching the Bootstrapping Operation
- Plaintext Spaces
基础知识
快速数论变换 NTT,在文章 深入理解NTT 中介绍。BGV 方案中,使用多项式环 R = Z [ x ] / ( f ( x ) ) R = \mathbb Z[x]/(f(x)) R=Z[x]/(f(x)),其中 f ( x ) = x d + 1 f(x)=x^d+1 f(x)=xd+1 是分圆多项式, d = 2 k d=2^k d=2k 是二的幂次。环 R R R 包含所有次数小于 d d d 的整系数多项式。然后,选取它的一个主理想 I = ( q ( x ) ) I=(q(x)) I=(q(x)),满足它的指数 [ R : I ] = p [R:I]=p [R:I]=p 是个素数,即环 R R R 是 p p p 个陪集 a i + I , a i ∈ R a_i+I,\, a_i \in R ai+I,ai∈R 的不交并。做商环:
R q = R / I = R = Z [ x ] / ( q ( x ) , f ( x ) ) R_q = R/I = R = \mathbb Z[x]/(q(x),f(x)) Rq=R/I=R=Z[x]/(q(x),f(x))
最简单的,可令 q ( x ) = p q(x)=p q(x)=p 是个素数,那么 R q = Z p [ x ] / ( f ( x ) ) R_q = \mathbb Z_p[x]/(f(x)) Rq=Zp[x]/(f(x))
假如 p ≡ 1 m o d 2 d p \equiv 1 \mod 2d p≡1mod2d,那么在 R p R_p Rp 上多项式 f ( x ) f(x) f(x) 可以完全分解为线性的互素因式,
f ( x ) = x d + 1 = ∏ i = 1 d ( x − ξ i ) f(x) = x^d+1 = \prod_{i=1}^d (x-\xi_i) f(x)=xd+1=i=1∏d(x−ξi)
从而根据 CRT,令 P i = ( x − ξ i , p ) P_i = (x-\xi_i,\, p) Pi=(x−ξi,p) 为彼此互素的理想,有:
R p ≅ Z [ x ] / P 1 × ⋯ Z [ x ] / P d R_p \cong \mathbb Z[x]/P_1 \times \cdots \mathbb Z[x]/P_d Rp≅Z[x]/P1×⋯Z[x]/Pd
简记 Z [ x ] / P i = R P i \mathbb Z[x]/P_i = R_{P_i} Z[x]/Pi=RPi
LWE 和 RLWE 问题,在文章 格上困难问题 中介绍。为了方便方案的描述,BGV 不想对两种格困难问题分别构造方案,因此定义了 General Learning with Errors (GLWE) Problem:

其中的噪声分布(一般取做离散高斯分布) χ \chi χ 是 B-bounded distributions,定义如下:
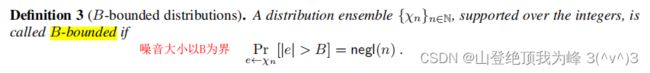
格上的陷门,在文章 格密码:陷门OWF 中介绍。在 BGV 中对 Gadget 的描述为:
G : = I n ⊗ g = [ g 0 ⋯ 0 g 0 ⋮ 0 ⋱ ⋮ . . . g ] ∈ Z q n × n l G:=I_n \otimes g= \left[ \begin{array}{c | c c c} g & 0 & \cdots \\ \hline 0 & g & 0 \\ \vdots & 0 & \ddots & \vdots\\ & & ... & g\\ \end{array} \right] \in \mathbb Z_q^{n \times nl} G:=In⊗g=⎣ ⎡g0⋮0g0⋯0⋱...⋮g⎦ ⎤∈Zqn×nl
其中 q q q 是素数, l = ⌈ log q ⌉ l = \lceil \log q \rceil l=⌈logq⌉, g = [ 1 , 2 , 4 , ⋯ , 2 l ] g=[1,2,4,\cdots,2^{l}] g=[1,2,4,⋯,2l]
- x ⃗ = G u ⃗ \vec x = G \vec u x=Gu:将向量 u ⃗ ∈ R 2 n l \vec u \in R_2^{nl} u∈R2nl 分成 n n n块,每个长为 l l l的 block 做二进制合成,得到向量 x ⃗ ∈ R q n \vec x \in R_q^n x∈Rqn
- u ⃗ = G − 1 ( x ) \vec u = G^{-1}(x) u=G−1(x):将向量 x ⃗ ∈ R q n \vec x \in R_q^n x∈Rqn 的每个分量都做二进制分解,得到向量 u ⃗ ∈ R 2 n l \vec u \in R_2^{nl} u∈R2nl
BGV
Basic Encryption Scheme
BGV 方案基于 BV 方案(在文章 全同态加密(FHE) 中介绍)。在 BGV 中,首先表述了基于 GLWE 的 BV 方案:
-
E . S e t u p ( 1 λ , 1 μ , b ) E.Setup(1^\lambda,1^\mu,b) E.Setup(1λ,1μ,b):
- 如果 b = 0 b=0 b=0,那么设置 d = 1 d=1 d=1(LWE),如果 b = 1 b=1 b=1,那么设置 n = 1 n=1 n=1(RLWE)。甚至,可以设置这两个极端之间的参数?
- 选取 μ \mu μ比特的素数模 q q q,设置 d = d ( λ , μ , b ) d=d(\lambda,\mu,b) d=d(λ,μ,b), n = n ( λ , μ , b ) n=n(\lambda,\mu,b) n=n(λ,μ,b), N = ⌈ ( 2 n + 1 ) log q ⌉ N=\lceil (2n+1)\log q \rceil N=⌈(2n+1)logq⌉, χ = χ ( λ , μ , b ) \chi = \chi(\lambda,\mu,b) χ=χ(λ,μ,b),使得 GLWE 实例的强度为 2 λ 2^\lambda 2λ
- 令 R = Z [ x ] / ( x d + 1 ) R=\mathbb Z[x]/(x^d+1) R=Z[x]/(xd+1),明文空间为 R p R_p Rp,其中 p ≪ q p \ll q p≪q是素数(例如 p = 2 p=2 p=2),密文空间为 R q n + 1 R_q^{n+1} Rqn+1
- 设置 p a r a m s = ( R , p , q , d , n , N , χ ) params=(R,p,q,d,n,N,\chi) params=(R,p,q,d,n,N,χ)
-
E . S e c r e t K e y G e n ( p a r a m s ) E.SecretKeyGen(params) E.SecretKeyGen(params):
- 采样 s ′ ← χ n s' \leftarrow \chi^n s′←χn,设置 s k = s = ( 1 , s ) ∈ R q n + 1 sk = s = (1,s) \in R_q^{n+1} sk=s=(1,s)∈Rqn+1
-
E . P u b l i c K e y G e n ( p a r a m s , s k ) E.PublicKeyGen(params,\, sk) E.PublicKeyGen(params,sk):
- 生成均匀随机矩阵 A ′ ← U ( R q N × n ) A' \leftarrow U(R_q^{N \times n}) A′←U(RqN×n),采样 e ← χ N e \leftarrow \chi^N e←χN
- 计算 b = A ′ s ′ + p e b=A's'+pe b=A′s′+pe,使得噪音 p e pe pe 属于理想 ( p ) (p) (p)
- 设置 p k = A = ( b , − A ′ ) ∈ R q N × ( n + 1 ) pk = A = (b,-A') \in R_q^{N \times (n+1)} pk=A=(b,−A′)∈RqN×(n+1),易知 A s = p e ≡ 0 m o d ( p ) As=pe \equiv 0 \mod (p) As=pe≡0mod(p)
-
E . E n c ( p a r a m s , p k , m ) E.Enc(params,\, pk,\, m) E.Enc(params,pk,m):
-
给定明文 m ∈ R p m \in R_p m∈Rp,设置行向量 m ⃗ = ( m , 0 , ⋯ , 0 ) ∈ R q n + 1 \vec m = (m,0,\cdots,0) \in R_q^{n+1} m=(m,0,⋯,0)∈Rqn+1
-
采样行向量 r ← R p N r \leftarrow R_p^N r←RpN,输出密文
c = m ⃗ + r A ∈ R q n + 1 c = \vec m+rA \in R_q^{n+1} c=m+rA∈Rqn+1
-
-
E . D e c ( p a r a m s , s k , c ) E.Dec(params,\, sk,\, c) E.Dec(params,sk,c):
-
给定密文 c ∈ R q n + 1 c \in R_q^{n+1} c∈Rqn+1,输出明文
m = [ [ < c , s > ] q ] p ∈ R p m=[[其中 [ ⋅ ] q [\cdot]_q [⋅]q 表示模 q q q的余数,范围 ( − q / 2 , q / 2 ] (-q/2,q/2] (−q/2,q/2]
-
在 BGV 中 m ≡ [ < c , s > ] q m o d p m \equiv [
Homomorphic Operations
矩阵 A ∈ R m × n , B ∈ R p × q A \in R^{m \times n},\, B \in R^{p \times q} A∈Rm×n,B∈Rp×q的 Kronecker product 定义为:
A ⊗ B = [ A i j ⋅ B ] i j ∈ R m p × n q A \otimes B = \left[ A_{ij} \cdot B \right]_{ij} \in R^{mp \times nq} A⊗B=[Aij⋅B]ij∈Rmp×nq
- 克罗内克积是结合的,但不是交换的
- 克罗内克积与矩阵加法间,满足左右分配律
- ( A ⊗ B ) T = A T ⊗ B T (A \otimes B)^T = A^T \otimes B^T (A⊗B)T=AT⊗BT, ( A ⊗ B ) − 1 = A − 1 ⊗ B − 1 (A \otimes B)^{-1} = A^{-1} \otimes B^{-1} (A⊗B)−1=A−1⊗B−1,注意对比 ( A B ) T = B T A T (AB)^T = B^TA^T (AB)T=BTAT、 ( A B ) − 1 = B − 1 A − 1 (AB)^{-1} = B^{-1}A^{-1} (AB)−1=B−1A−1、 ( A B ) ∗ = B ∗ A ∗ (AB)^* = B^*A^* (AB)∗=B∗A∗(穿脱原理)
- ( X ⊗ Y ) ( U ⊗ V ) = ( X U ) ⊗ ( Y V ) (X\otimes Y)(U \otimes V) = (XU) \otimes (YV) (X⊗Y)(U⊗V)=(XU)⊗(YV)
- 对于 A ∈ R m × m , B ∈ R n × n A \in R^{m \times m},B \in R^{n \times n} A∈Rm×m,B∈Rn×n,有 d e t ( A ⊗ B ) = d e t ( A ) n ⋅ d e t ( B ) m det(A \otimes B)=det(A)^n \cdot det(B)^m det(A⊗B)=det(A)n⋅det(B)m
- r a n k ( A ⊗ B ) = r a n k ( A ) ⋅ r a n k ( B ) rank(A \otimes B) = rank(A) \cdot rank(B) rank(A⊗B)=rank(A)⋅rank(B)
根据上述性质,易知
< c 1 ⊗ c 2 , s 1 ⊗ s 2 > = ( c 1 ⊗ c 2 ) T ( s 1 ⊗ s 2 ) = ( c 1 T ⊗ c 2 T ) ( s 1 ⊗ s 2 ) = ( c 1 T s 1 ) ⊗ ( c 2 T s 2 ) = < c 1 , s 1 > ⋅ < c 2 , s 2 > \begin{aligned}
因此,
- 同态加法: D e c ( c 1 + c 2 , s ) = D e c ( c 1 , s ) + D e c ( c 2 , s ) Dec(c_1+c_2,\, s) = Dec(c_1,s)+Dec(c_2,s) Dec(c1+c2,s)=Dec(c1,s)+Dec(c2,s)
- 同态乘法: D e c ( c 1 ⊗ c 2 , s ⊗ s ) = D e c ( c 1 , s ) ⋅ D e c ( c 2 , s ) Dec(c_1 \otimes c_2,\, s \otimes s) = Dec(c_1,s) \cdot Dec(c_2,s) Dec(c1⊗c2,s⊗s)=Dec(c1,s)⋅Dec(c2,s)
然而,上述的同态乘法有很大的缺陷:密文和私钥的规模指数级增大,噪声指数级增大。
Key Switching
密钥切换技术,用于降低密文和密钥的维度。
BGV 将 Gadget 视为二进制合并和分解,

有 B i t D e c o m p ( c ) = G − 1 ( c ) , P o w e r s o f ( s ) = s T G BitDecomp(c)=G^{-1}(c),\, Powersof(s)=s^TG BitDecomp(c)=G−1(c),Powersof(s)=sTG,易知:
< B i t D e c o m p ( c , q ) , P o w e r s o f ( s , q ) > = ∑ j = 0 l − 1 < u j , 2 j s > = < c , s > = s T G ⋅ G − 1 ( c ) \begin{aligned} &
密钥切换的程序为:

可以理解为:寻找 s 2 T K = s 1 T G s_2^TK=s_1^TG s2TK=s1TG的 K K K,设置 c 2 = K ⋅ G − 1 ( c 1 ) c_2=K \cdot G^{-1}(c_1) c2=K⋅G−1(c1),于是 s 2 T c 2 = ( s 1 T G ) ⋅ G − 1 ( c 1 ) = s 1 T c 1 s_2^Tc_2 = (s_1^TG) \cdot G^{-1}(c_1) = s_1^Tc_1 s2Tc2=(s1TG)⋅G−1(c1)=s1Tc1
Modulus Switching
模切换技术,用于降低噪声的绝对大小(相对大小略有上升)。
模切换技术并不能降低噪声比率(the ratio of the noise to the “noise ceiling” (the modulus size)),而噪声比率约束了密文的同态能力。似乎降低噪音绝对大小并不会提高同态能力。然而,对于乘法来说:
- 噪声大小为 x x x,假设 q ≈ x k q\approx x^k q≈xk,于是噪声比率为 x / q ≈ x 1 − k x/q \approx x^{1-k} x/q≈x1−k
- 选择 a ladder of gradually decreasing moduli { q i ≈ q x i } \{q_i \approx \dfrac{q}{x^i}\} {qi≈xiq}
- 每次密文乘法,导致结果的噪声从 x a x^a xa成为 x 2 a x^{2a} x2a
- 假设不做模切换,那么下一次乘法将会达到 x 4 x^4 x4的噪声,最多只能做 log k \log k logk次乘法,噪声就会达到 x k = q x^k=q xk=q,导致不可解密。
- 如果每次都做模切换,第 j j j次乘法后,从 q j − 1 q_{j-1} qj−1切换到 q j q_{j} qj上,同时噪声从 x 2 x^2 x2降低到 x x x,比率为 x / q j = x j − k x/q_{j} = x^{j-k} x/qj=xj−k,因此最多可以做 k k k次乘法。
模切换的程序为:

(Leveled) FHE Based on GLWE without Bootstrapping
如果设置 Basic Encryption Scheme 的明文空间为 R 2 R_2 R2,那么 BGV 方案如下:

其同态运算为:

由于密钥切换和模切换,都是算术电路上计算的,因此它们比 Bootstrapping 的布尔电路计算要高效的多。为了计算深度 d d d 的算术电路,只要在初始化的时候设置 L = d L=d L=d 即可。
但随着 L L L 增大,模数 q L q_L qL的比特长度会线性增长,从而导致每个 Gate 的计算复杂度上升。对于很深的电路,我们可以重新引入 Bootstrapping 作为优化(而非必需)。
Optimizations
Batching
上述的 BGV 方案中,设置了 p = 2 p=2 p=2,从而可以对商环 R 2 R_2 R2 上的明文做运算。
奇素数 p ≡ 1 m o d 2 d p \equiv 1 \mod 2d p≡1mod2d,根据数论可以知道,
R p ≅ R P 1 × ⋯ × R P d R_p \cong R_{P_1} \times \cdots \times R_{P_d} Rp≅RP1×⋯×RPd
其中 P i = ( p , x − ξ i ) P_i = (p,x-\xi_i) Pi=(p,x−ξi),且陪集 0 + P i , ⋯ , ( p − 1 ) + P i 0+P_i,\cdots,(p-1)+P_i 0+Pi,⋯,(p−1)+Pi 恰好拼成整个环 R = Z [ x ] / ( f ( x ) ) R=\mathbb Z[x]/(f(x)) R=Z[x]/(f(x)),或者说 I I I作为加群的指数为 [ R : I ] = p [R:I]=p [R:I]=p(Emmmm, 怎么觉得不太对呢?奥,没问题)
上述的每个理想都是同构的,存在环 R R R 的自同构(automorphism) σ i → j \sigma_{i \to j} σi→j,使得 σ i → j ( P i ) = P j \sigma_{i \to j}(P_i)=P_j σi→j(Pi)=Pj,确切地说:
σ i → j ( ∑ o = 0 d − 1 r o x o ∈ P i ) = ∑ o = 0 d − 1 r o x e i j o m o d 2 d ∈ P j \sigma_{i \to j}\left(\sum_{o=0}^{d-1}r_ox^{o} \in P_i \right) = \sum_{o=0}^{d-1}r_ox^{e_{ij}o \mod 2d} \in P_j σi→j(o=0∑d−1roxo∈Pi)=o=0∑d−1roxeijomod2d∈Pj
其中 1 < e i j < 2 d 1< e_{ij} <2d 1<eij<2d 是奇数(是多少?论文里没说啊!)。
结合文章 全同态加密:CKKS 中内容,应为 e i j = ( 2 j + 1 ) − 1 ⋅ ( 2 i + 1 ) m o d 2 d , ∀ i , j = 0 , 1 , ⋯ , d − 1 e_{ij} = (2j+1)^{-1} \cdot (2i+1) \mod 2d,\, \forall i,j=0,1,\cdots,d-1 eij=(2j+1)−1⋅(2i+1)mod2d,∀i,j=0,1,⋯,d−1。因为 d d d 是素数 2 2 2 的幂次,所以 ϕ ( 2 d ) = d \phi(2d)=d ϕ(2d)=d,因此有 ϕ 2 d ( x ) = x d + 1 \phi_{2d}(x) = x^d+1 ϕ2d(x)=xd+1。这个分圆多项式的 d d d 个根就是 2 d 2d 2d 次本原单位根 ξ 2 d k , ∀ k ∈ Z 2 d ∗ \xi_{2d}^k,\, \forall k \in \mathbb Z_{2d}^* ξ2dk,∀k∈Z2d∗。易知, Z 2 d ∗ = { 1 , 3 , ⋯ , 2 d − 1 } Z_{2d}^* = \{1,3,\cdots,2d-1\} Z2d∗={1,3,⋯,2d−1},因此 k k k 都是奇数,从而 e i j = k 1 − 1 ⋅ k 2 m o d 2 d ∈ Z 2 d ∗ e_{ij}=k_1^{-1} \cdot k_2 \mod 2d \in \mathbb Z_{2d}^* eij=k1−1⋅k2mod2d∈Z2d∗ 也是奇数,这里 k 1 = 2 j + 1 k_1=2j+1 k1=2j+1, k 2 = 2 i + 1 k_2=2i+1 k2=2i+1。此时, f ′ ( x ) = σ i → j ( f ( x ) ) = f ( x e i j ) f'(x) = \sigma_{i \to j}(f(x)) = f(x^{e_{ij}}) f′(x)=σi→j(f(x))=f(xeij) 满足:
f ′ ( ξ 2 d 2 j + 1 ) = σ i → j ( f ( ξ 2 d 2 j + 1 ) ) = f ( ξ 2 d ( 2 j + 1 ) e i j ) = f ( ξ 2 d 2 i + 1 ) f'(\xi_{2d}^{2j+1}) = \sigma_{i \to j}(f(\xi_{2d}^{2j+1})) = f(\xi_{2d}^{(2j+1)e_{ij}}) = f(\xi_{2d}^{2i+1}) f′(ξ2d2j+1)=σi→j(f(ξ2d2j+1))=f(ξ2d(2j+1)eij)=f(ξ2d2i+1)
于是,我们可以将一个密文上划分出 d d d(或者 d d d 的因子,类似不完全NTT)个明文槽(plaintext slots),第 i i i 个明文的取值范围是理想 P i P_i Pi 对应的商环 R P i R_{P_i} RPi
我们使用 RLWE 版本的 BGV 方案,
- 设置 n = 1 n=1 n=1,令 d = 2 k d=2^k d=2k是二的幂次,选取奇素数 p ≡ 1 m o d 2 d p \equiv 1 \mod 2d p≡1mod2d
- 在 E . P u b l i c K e y G e n ( ) E.PublicKeyGen() E.PublicKeyGen() 中,设置 A s = p e As=pe As=pe
- 在 E . D e c ( ) E.Dec() E.Dec() 中,设置 m = [ [ < c , s > ] q ] p m = [[
- 在 S c a l e ( ) Scale() Scale() 中,设置 r = p r=p r=p
- 同态运算都是在 mod-p gates 的电路上的
注意,这里的 p = O ( p o l y ( λ ) ) p=O(poly(\lambda)) p=O(poly(λ)),此时同态运算的额外的噪声是多项式的。对于超多项式的 p p p ,噪音增长严重,从而无法使用。
使用 Batching 技术,计算一个密文的同态运算,就达到了 d d d 个明文的运算,因此效率几乎(因为模数 q ( x ) q(x) q(x) 从 2 2 2增大到了 p p p,算术运算会慢一些)提高了 d d d 倍。
Bootstrapping as an Optimization
自举的优点为:
- Performance: L L L 不必设置的和电路深度一样大,于是每个门的计算复杂度独立于电路深度,计算效率高。
- Flexibility:假设循环安全,那么自举将导致无限深度的电路,而不必预设电路深度上界,更加灵活。
- Memory:可以把原始数据的密文用 AES 存储,占内存很小。当需要计算时,用 Bootstrapping 执行解密电路,解压(de-compressed)为长密文,再执行同态运算。解压的长密文没法重新变回 AES 短密文。
对于 LWE 版本的 BGV,解密函数为: m = [ [ < c , s > ] q ] 2 m = [[
-
内积中的对应分量两两乘积,由于 c [ i ] c[i] c[i] 有 log q \log q logq 比特,因此 c [ i ] ⋅ s [ i ] c[i] \cdot s[i] c[i]⋅s[i] 可以写成至多(比特 0 0 0 的不必相加) log q \log q logq 个 s [ i ] s[i] s[i] 的左移的加和。一个 s [ i ] s[i] s[i] 的左移,它的长度至多为 2 log q 2 \log q 2logq 比特。
-
一个内积有 n n n个对应分量,共需要 n log q n \log q nlogq 个 2 log q 2 \log q 2logq 比特数的加和。使用二叉树式的电路,深度为 O ( log ( n log g ) ) = O ( log n + log log q ) O(\log(n \log g)) = O(\log n + \log\log q) O(log(nlogg))=O(logn+loglogq),逻辑门的数量为 O ( n log q ⋅ log q ) = O ( n log 2 q ) O(n \log q \cdot \log q) = O(n \log^2 q) O(nlogq⋅logq)=O(nlog2q)
-
然后,计算 < c , s > m o d q
-
最后,计算 ( < c , s > m o d q ) m o d 2 (
-
综上所述,Bootstrapping 的电路深度为:
O ( log n + log log q ) O(\log n + \log\log q) O(logn+loglogq)电路大小为:
O ( n log 2 q ) O(n \log^2 q) O(nlog2q)代入安全参数 n = O ( λ ) n=O(\lambda) n=O(λ) 和 log q = O ( log λ ) \log q = O(\log \lambda) logq=O(logλ):电路大小为 O ~ ( λ ) \tilde O(\lambda) O~(λ),电路深度为 O ( log λ ) O(\log \lambda) O(logλ)
对于 RLWE 版本的 BGV,解密函数中的向量长度为 2 2 2,每个分量都是多项式环 Z 2 [ x ] / ( f ( x ) ) \mathbb Z_2[x]/(f(x)) Z2[x]/(f(x)) 上的乘积,可以使用 DFT 来计算。其 Bootstrapping 的电路规模与 LWE 版本的类似。
由于噪声增长的没那么快,因此我们可以 Bootstrapping Lazily,每 L L L 层才自举一次,其他层都不执行自举程序。经最优化,得到:
L = θ ( log λ ) L = \theta(\log \lambda) L=θ(logλ)
Batching the Bootstrapping Operation
上述的 Batching 方案,每个明文槽都只能和对应的明文槽内的明文做运算。如果我们想让它们之间也可以交互计算怎么办呢?
思路是,
-
规定普通密文仅使用第一个明文槽 R P 1 R_{P_1} RP1,其他的槽中都是 0 ∈ R P i , i ≠ 1 0 \in R_{P_i},\, i \neq 1 0∈RPi,i=1
-
利用理想之间的环 R R R 自同构映射 σ i → j \sigma_{i \to j} σi→j,将各个槽里的明文进行搬移,
m = [ [ < c , s > ] q ] P i ⟺ m = [ [ < σ i → j ( c ) , σ i → j ( s ) > ] q ] P j m=[[ -
选取 u ∈ 1 + P 1 u \in 1+P_1 u∈1+P1,且 u ∈ P i , i ≠ 1 u \in P_i,i \neq 1 u∈Pi,i=1,这用于将其他槽的内容清零。
实现 Pack 和 Unpack 函数,进行 normal homomorphic operation 和 batch operation 之间的转换:


只要上边的私钥链 s 1 , s 2 , ⋯ s_1,s_2,\cdots s1,s2,⋯ 是无环的,那么就可以避免 circular security problem,但需要存储的密钥切换映射 τ \tau τ 就会多一些。如果我们假设它是循环安全的,那么就只需要存储一个私钥 s s s 的那些映射即可。
利用上述的 Pack 和 Unpack,就可以对电路同一层的密文执行并行的 Bootstrapping。如果电路的宽度足够大(每一层的宽度为 O ( λ ) O(\lambda) O(λ)),那么 Bootstrapping 的计算复杂度可以降低一个 log λ \log \lambda logλ 因子。
其实上边的 Pack 和 Unpack 更重要的是:可以在明文需要串行计算时串行,可以并行计算时并行。从而加速单个算术电路的计算效率。否则,Batching 只能并行计算 d d d 个相同电路的 copy,对于不同的明文输入。
Plaintext Spaces
上述的方案中, R q R_q Rq上的 q j ( x ) q_j(x) qj(x) 都选做了素数。如果我们想要在很大的明文空间 Z p \mathbb Z_p Zp上运算,那么 q j q_j qj就不得不选取为安全参数 λ \lambda λ的指数级。此时 q j / B q_j/B qj/B( B B B是噪声上界)是指数级的,导致 LWE 问题不难。
因此,我们不直接使用 Z p \mathbb Z_p Zp作为明文空间,而是使用同构的 R / I R/I R/I,其中理想 I I I 作为加群的指数为 [ R : I ] = p [R:I]=p [R:I]=p,同时获得理想 I I I的一组短格基 B I B_I BI( ∥ B I ∥ = O ( p o l y ( d ) ⋅ p 1 / d ) \|B_I\|=O(poly(d) \cdot p^{1/d}) ∥BI∥=O(poly(d)⋅p1/d))。对于梯子“ladder”,我们选取多项式 q j ∈ R q_j \in R qj∈R,构造主理想 ( q j ) (q_j) (qj),使它满足 q j ∈ 1 + I q_j \in 1+I qj∈1+I 且 ∥ q j + 1 ∥ / ∥ q j ∥ \|q_{j+1}\|/\|q_j\| ∥qj+1∥/∥qj∥ 大约为 2 μ 2^\mu 2μ 大小,令理想 ( q j ) (q_j) (qj) 的 rotation basis 为:
B q j = { x i q j ( x ) m o d f ( x ) } i = 0 d − 1 B_{q_j} = \{x^iq_j(x) \mod f(x)\}_{i=0}^{d-1} Bqj={xiqj(x)modf(x)}i=0d−1
从 R q j + 1 R_{q_{j+1}} Rqj+1 模切换到 R q j R_{q_j} Rqj 的算法为:

说实话,这一节博主我没怎么看懂 (╥﹏╥) ,
- 最后一层 ∥ q 0 ∥ ≈ 2 μ \|q_0\| \approx 2^\mu ∥q0∥≈2μ,噪音远小于 q 0 q_0 q0。那么每次 reflesh 都降低 μ \mu μ 比特,是不是太奢侈了?
- 理想 I I I 怎么选取?除了 ( p ) (p) (p) 外还能有其他理想的指数也是素数 p p p 么?或者 p p p 不是素数?
- 怎么选的多项式 q j ( x ) q_j(x) qj(x)? I I I 的生成元的某个倍数再加一?
- 多项式范数 ∥ q j ( x ) ∥ \|q_j(x)\| ∥qj(x)∥ 怎么定义的?是系数向量的无穷范数么?相邻多项式的范数之比是什么几何意义?
先写在这儿等以后回顾。