Flume:自定义拦截器-选择器-kafka
文章目录
- 一、kafka基本操作与flume级联案例操作手册(不使用选择器、拦截器)
-
- 1、启动hdfs、kafka
- 2、准备级联配置:(第一版:不使用选择器、拦截器)
- 3、kafka的基本命令操作:
- 4、启动flume
- 二、channel选择器-自定义拦截器-项目分流需求
-
- 1、调用:
- 2、两种选择器:
- 3、复制选择器(默认):replicating selector
- 4、多路复用选择器:multiplexing selector
- 三、序列化和反序列化
-
- 1、序列化的定义:
- 2、如何实现序列化:
- 3、几种序列化方式:
- 四、级联下的高可用
-
- 1、grouping processor(组处理器)
- 2、实现第二级高可用:
一、kafka基本操作与flume级联案例操作手册(不使用选择器、拦截器)
1、启动hdfs、kafka
(1)如果是第一次启动kafka,启动前需要设置一下broker.id=0或1:
vi /opt/apps/kafka_2.11-2.0.0/config/server.properties
①broker.id=0或broker.id=1
②zookeeper地址:
zookeeper.connect=doitedu01:2181,doitedu02:2181,doitedu03:2181
(2)①先启动zookeeper:
zkall.sh start
②后台启动kafka:(后台:-daemon;三台都需要启动)
bin/kafka-server-start.sh -daemon config/server.properties
③查看端口:jps -m
④如果出现下面这种情况:
1356 -- process information unavailable
说明进程程序已经退出的,但是进程没有关掉
⑤找到这个进程:
find / -name 1356
得到如下地址:
/tmp/hsperfdata_impala/1356
这是个impala的进程
⑥删掉即可:
rm -rf /tmp/hsperfdata_impala
2、准备级联配置:(第一版:不使用选择器、拦截器)
agent级联配置,没有加选择器和拦截器,使用avro,kafka sink
##第一级配置,第一级所有的节点配置都一样
a1.sources = r1
a1.channels = c1
a1.sinks = k1
a1.sources.r1.channels = c1
a1.sources.r1.type = TAILDIR
a1.sources.r1.filegroups = g1
a1.sources.r1.filegroups.g1 = /logdata/a.*
a1.sources.r1.fileHeader = false
a1.channels.c1.type = file
a1.sinks.k1.channel = c1
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = doitedu02
a1.sinks.k1.port = 4444
##第二级agent配置,使用file channel,下一级bind、端口决定上一级
a1.sources = r1
a1.channels = c1
a1.sinks = k1
a1.sources.r1.channels = c1
a1.sources.r1.type = avro
a1.sources.r1.bind = doitedu02
a1.sources.r1.port = 4444
a1.sources.r1.batchSize = 100
a1.channels.c1.type = file
a1.sinks.k1.channel = c1
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.kafka.bootstrap.servers = doitedu01:9092,doitedu02:9092,doitedu03:9092
a1.sinks.k1.topic = doitedu17
a1.sinks.k1.flumeBatchSize = 100
a1.sinks.k1.producer.acks = 1
3、kafka的基本命令操作:
启动kafka
bin/kafka-server-start.sh -daemon config/server.properties
(1)topic查看
bin/kafka-topics.sh --list --zookeeper doitedu01:2181
(2)topic创建(指定topic名、分区数、副本数)
bin/kafka-topics.sh --create --topic topic2 --partitions 2 --replication-factor 2 --zookeeper doitedu01:2181
(3)启动一个控制台生产者来生产数据
bin/kafka-console-producer.sh --broker-list doitedu01:9092,doitedu02:9092,doitedu03:9092 --topic topic2
(4)启动一个控制台消费者来消费数据
bin/kafka-console-consumer.sh --bootstrap-server doitedu01:9092,doitedu02:9092,doitedu03:9092 --topic topic2 --from-beginning
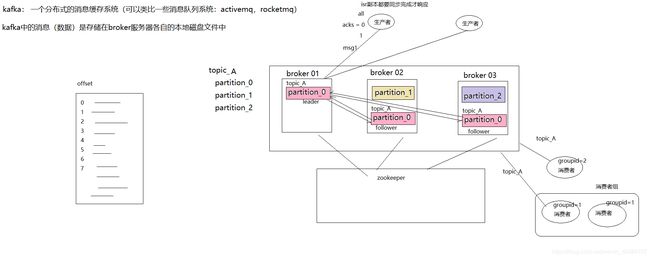
(5)kafka基本概念示意图:
4、启动flume
doitedu01作为第一级,doitedu02作为第二级
(1)将配置文件按分级放在不同机器上
①第一台机器:
vi /opt/apps/flume-1.9.0/agentconf/tail-flume-avrosink.properties
将第一级配置放入properties中
②第二台机器:
vi /opt/apps/flume-1.9.0/agentconf/tail-flume-avrosink.properties
将第一级配置放入properties中
(2)模拟日志生成:
cd /logdata
while true;do echo "123456$RANDOM i love you" >> a.log;sleep 0.2;done
(3)启动kafka
bin/kafka-server-start.sh -daemon config/server.properties
(4)启动flume;
①先启动第二级:(doitedu02中)
bin/flume-ng agent -c conf -f agentconf/avro-flume-kfksink.properties -n a1 -Dflume.root.logger=debug,console
查看进程得知,启动了一个application,可以查看一下application的端口号:
netstat -nltp | grep 120017
得到结果如下:
tcp6 0 0 192.168.77.42:4444 :::* LISTEN 120017/java
②再启动第一级:(doitedu01中)
bin/flume-ng agent -c conf -f agentconf/avro-flume-kfksink.properties -n a1 -Dflume.root.logger=debug,console
(5)查看kafka中:
①查看是否写入:
bin/kafka-topics.sh --list --zookeeper doitedu01:2181
②检查数据是否到了kafka,启动消费者:
bin/kafka-console-consumer.sh --bootstrap-server doitedu01:9092,doitedu02:9092,doitedu03:9092 --topic doitedu17
③停止:CTRL+C
二、channel选择器-自定义拦截器-项目分流需求
1、调用:
source先调用拦截器,得到结果,再调用选择器,将结果放入指定channel。
2、两种选择器:
replicating selector和multiplexing selector
3、复制选择器(默认):replicating selector
(1)场景:
selector将event复制,taildir采集完,分发给所有下游节点,一个是hdfs,一个是kafka
(2)配置:
a1.sources = r1
a1.channels = c1 c2
a1.sinks = k1 k2
a1.sources.r1.channels = c1 c2
a1.sources.r1.type = TAILDIR
a1.sources.r1.filegroups = g1
a1.sources.r1.filegroups.g1 = /logdata/a.*
a1.sources.r1.fileHeader = false
a1.sources.r1.selector.type = replicating
a1.sources.r1.selector.optional = c2
a1.sources.r1.interceptors = i1 i2
a1.sources.r1.interceptors.i1.type = timestamp
a1.sources.r1.interceptors.i1.headerName = timestamp
a1.sources.r1.interceptors.i2.type = cn.doitedu.yiee.flume.MultiplexingInterceptor$MultiplexingInterceptorBuilder
a1.sources.r1.interceptors.i2.flagfield = 2
a1.channels.c1.type = memory
a1.channels.c2.type = memory
a1.sinks.k1.channel = c1
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.kafka.bootstrap.servers = doitedu01:9092,doitedu02:9092,doitedu03:9092
a1.sinks.k1.kafka.topic = doitedu17
a1.sinks.k1.kafka.producer.acks = 1
a1.sinks.k2.channel = c2
a1.sinks.k2.type = hdfs
a1.sinks.k2.hdfs.path = hdfs://doitedu01:8020/flumedata/%Y-%m-%d/%H
a1.sinks.k2.hdfs.filePrefix = doitedu-log-
a1.sinks.k2.hdfs.fileSuffix = .log
a1.sinks.k2.hdfs.rollSize = 268435456
a1.sinks.k2.hdfs.rollInterval = 120
a1.sinks.k2.hdfs.rollCount = 0
a1.sinks.k2.hdfs.batchSize = 1000
a1.sinks.k2.hdfs.fileType = CompressedStream
a1.sinks.k2.hdfs.codeC = snappy
a1.sinks.k2.hdfs.useLocalTimeStamp = false
注:
source中:
①type:selector的类型使用复制选择器replicating。
②optional:选择器的可选channel,如果不写,代表c1和c2都是必须的。
③interceptors:拦截器。
sink中:
①k1是kafka,k2是hdfs。
②k1.kafka.bootstrap.servers:服务器地址,写法:主机名:端口号,用逗号隔开。
③rollInterval:大小与hdfs切块大小无关。
4、多路复用选择器:multiplexing selector
(1)简介:
①可以根据event中的一个指定key的value来决定这条消息会写入哪个channel,具体在选择时,需要配置一个映射关系;
②场景:多路选择器是用来做分流的,将不同类型的数据写入到不同目的地;
③关键:需要在event中加入不同标记,然后去找header,根据header带的值(CZ、US、default),由source将消息发给不同的channel。
④例子:
Example for agent named a1 and it's source called r1:
a1.sources = r1
a1.channel = c1 c2 c3
a1.sources.r1.selector.type = multiplexing
a1.sources.r1.selector.header = state
a1.sources.r1.selector.mapping.CZ = c1
a1.sources.r1.selector.mapping.US = c2
a1.sources.r1.selector.default = c3
注:
header:去找source定的header;CZ、US、default都是header带的值;
CZ表示:如果state=CZ,发给c1;US表示:如果state=US,发给c2;default表示:如果默认default,发给c3。
(2)写java程序(MultiplexingInterceptor.java);打成jar包,上传到flume-1.9.0/lib下。
(3)模拟日志生成:
while true
do
if [ $(($RANDOM % 2)) -eq 0 ]
then
echo "u$RANDOM,e1,waimai,`date +%s`000" >> a.log
else
echo "u$RANDOM,e1,mall,`date +%s`000" >> a.log
fi
sleep 0.2
done
注:
日志格式:u01,ev1,mall,1564598789
模拟生成日志中,``是成对出现,里面放指令(date+%s是指令,表示时间,默认单位是秒)
(4)flume的agent配置:
1个source,2个channel,2个sink,一个分路选择器:multiplexing,一个自定义拦截器(type是自定义拦截器的全类名)
a1.sources = r1
a1.channels = c1 c2
a1.sinks = k1 k2
a1.sources.r1.channels = c1 c2
a1.sources.r1.type = TAILDIR
a1.sources.r1.filegroups = g1
a1.sources.r1.filegroups.g1 = /logdata/a.*
a1.sources.r1.fileHeader = false
##自定义拦截器
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = cn.doitedu.yiee.flume.MultiplexingInterceptor$MultiplexingInterceptorBuilder
a1.sources.r1.interceptors.i1.flagfield = 2
a1.sources.r1.interceptors.i1.timestampfield = 3
##选择器
a1.sources.r1.selector.type = multiplexing
a1.sources.r1.selector.header = flag
a1.sources.r1.selector.mapping.mall = c1
a1.sources.r1.selector.mapping.waimai = c2
a1.sources.r1.selector.default = c2
##channel:c1和c2
a1.channels.c1.type = memory
a1.channels.c1.capacity = 2000
a1.channels.c1.transactionCapacity = 1000
a1.channels.c2.type = memory
a1.channels.c2.capacity = 2000
a1.channels.c2.transactionCapacity = 1000
##kafka sink:k1和k2
##k1:kafka sink
a1.sinks.k1.channel = c1
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.kafka.bootstrap.servers = doitedu01:9092,doitedu03:9092
a1.sinks.k1.kafka.topic = mall
a1.sinks.k1.kafka.producer.acks = 1
##k2:hdfs sink
a1.sinks.k2.channel = c2
a1.sinks.k2.type = hdfs
a1.sinks.k2.hdfs.path = hdfs://doitedu01:8020/waimai/%Y-%m-%d/%H
a1.sinks.k2.hdfs.filePrefix = doitedu-log-
a1.sinks.k2.hdfs.fileSuffix = .log
a1.sinks.k2.hdfs.rollSize = 268435456
a1.sinks.k2.hdfs.rollInterval = 120
a1.sinks.k2.hdfs.rollCount = 0
a1.sinks.k2.hdfs.batchSize = 1000
a1.sinks.k2.hdfs.fileType = DataStream
a1.sinks.k2.hdfs.useLocalTimeStamp = false
将配置文件上传到flume/agentconf,文件名:multiplexing-interceptor.properties
(5)启动kafka
bin/kafka-server-start.sh -daemon config/server.properties
(6)启动hdfs
start-dfs.sh
(7)启动flume agent
bin/flume-ng agent -c conf -f agentconf/multiplexing-interceptor.properties -n a1 -Dflume.root.logger=debug,console
(8)检查数据是否到了kafka,启动消费者:
bin/kafka-console-consumer.sh --bootstrap-server doitedu01:9092,doitedu02:9092,doitedu03:9092 --topic mall from-beginning
三、序列化和反序列化
1、序列化的定义:
序列化:将一个有结构的对象转换成一串线性的二进制序列。
2、如何实现序列化:
开发人员自己控制,把这个对象的方方面面的信息(字段值,字段名,类名,继承体系…),依次表达成二进制。
3、几种序列化方式:
ObjectOutputStream:
(1)jdk中自带的序列化工具,它会把这个对象的方方面面的信息都序列化出去,产生的二进制序列体积臃肿庞大,但是信息很全。
(2)为什么要实现Serializable接口?
①Serializable接口是一个标记接口,实现此接口不用重写方法;
②有些对象不应该被序列化,比如:对象中存储的数据是与本机挂钩的,或者有些存在时间令牌等,如果被反序列化到其他机器上不能使用;
③实现接口是为了提醒写代码的人这个对象应不应该被序列化。
(3)代码实现:
序列化的类:
import java.io.FileOutputStream;
import java.io.ObjectOutputStream;
public class SerDeDemo {
public static void main(String[] args) throws Exception {
Person p = new Person("小明", 288899998.8, 18);
ObjectOutputStream objout = new ObjectOutputStream(new FileOutputStream("d:/p.obj"));
objout.writeObject(p);
objout.close();
}
}
bean类:
import java.io.Serializable;
public class Person implements Serializable {
private String name;
private Double salary;
private int age;
public Person() {
}
public Person(String name, Double salary, int age) {
this.name = name;
this.salary = salary;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Double getSalary() {
return salary;
}
public void setSalary(Double salary) {
this.salary = salary;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}
DataOutputStream
(1)DataOutputStream是以字节(byte)为基本处理单位,从OutputStream派生而来,不用实现Serializable接口;
而且使用DataOutputStream序列化后的文件占用体积比较小。
(2)代码实现:
序列化的类:
import java.io.DataOutputStream;
import java.io.FileOutputStream;
public class SerDeDemo {
public static void main(String[] args) throws Exception {
Person p = new Person("小明", 288899998.8, 18);
DataOutputStream dataout = new DataOutputStream(new FileOutputStream("d:/p2.obj"));
dataout.writeUTF(p.getName());
dataout.writeDouble(p.getSalary());
dataout.writeInt(p.getAge());
DataOutputStream dataout2 = new DataOutputStream(new FileOutputStream("d:/p3.obj"));
dataout2.writeInt(18);
dataout2.writeUTF("18");
}
}
bean类:
public class Person {
private String name;
private Double salary;
private int age;
public Person() {
}
public Person(String name, Double salary, int age) {
this.name = name;
this.salary = salary;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Double getSalary() {
return salary;
}
public void setSalary(Double salary) {
this.salary = salary;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}
分布式计算框架中实现序列化的方法:
Writable
(1)MapReduce中将对象序列化,实现Writable接口,是调用了对象上的write方法,反序列化调用readFields方法;借鉴了DateOutputStream和DateInputStream;
(2)实例是FSDataOutputStream和FSDataInputStream,FSDataOutputStream和FSDataInputStream又继承了DataOutputStream和DataInputStream;
(3)write方法 和 readFields方法 都是类的定义者自己实现的,相当于序列化的具体行为是由开发者自己控制的;
Kryo
(1)spark中将对象序列化,默认调用都是jdk的objectoutputstream(serializable),效率低;
所以,我们在spark代码中,一般都要修改序列化器,可以用kryo序列化框架;
kryo序列化框架的序列化结果要比jdk的序列化结果更精简(少了一些类的元信息);
(2)kryo在序列化时,还是会带上一些必要的类元信息,以便于下游task能正确反序列化;
可以提前将这些可能要被序列化的类型,注册到kryo的映射表中,这样,kryo在序列化时就不需要序列化类元信息了。
(3)代码实现:
主类
import java.util
import java.util.{ArrayList, List}
import org.apache.spark.SparkConf
import org.apache.spark.serializer.KryoSerializer
import org.apache.spark.sql.SparkSession
object SparkSerde {
def main(args: Array[String]): Unit = {
/**
spark中将对象序列化,默认调用都是jdk的objectoutputstream(serializable),效率低;
所以,我们在spark代码中,一般都要修改序列化器,可以用kryo序列化框架;
kryo序列化框架的序列化结果要比jdk的序列化结果更精简(少了一些类的元信息)。
*/
val spark1 = SparkSession.builder.config("spark.serializer", classOf[KryoSerializer].getName).appName("").master("local").getOrCreate
//导入隐式转换
import spark1.implicits._
spark1.createDataset(Seq(new Person("zz", 1888.8, 28)));
/**
上面的做法中:kryo在序列化时,还是会带上一些必要的类元信息,以便于下游task能正确反序列化;
下面的做法中:可以提前将这些可能要被序列化的类型,注册到kryo的映射表中,这样,kryo在序列化时就不需要序列化类元信息了。
*/
val conf = new SparkConf
conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
conf.registerKryoClasses(Array(classOf[Person],classOf[Person2]))
val spark2 = SparkSession.builder()
.config(conf)
.master("local")
.appName("序列化案例")
.getOrCreate()
}
}
bean类
public class Person {
private String name;
private Double salary;
private int age;
public Person() {
}
public Person(String name, Double salary, int age) {
this.name = name;
this.salary = salary;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Double getSalary() {
return salary;
}
public void setSalary(Double salary) {
this.salary = salary;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}
avro
avro与kryo类似,但是avro是个跨平台、跨语言的序列化工具。
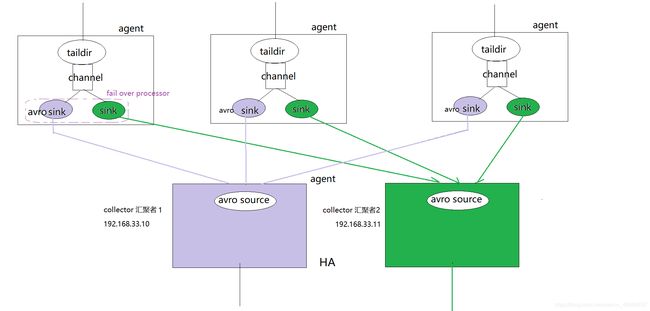
四、级联下的高可用
1、grouping processor(组处理器)
一个agent中,多个sink可以被组装到一个组,而数据在组内多个sink之间发送,有两种模式:
(1)模式1:Failover Sink Processor失败切换
一组中只有优先级高的那个sink在工作,另一个是等待中
如果高优先级的sink发送数据失败,则专用低优先级的sink去工作!并且,在配置时间penalty之后,还会尝试用高优先级的去发送数据!
a1.sinkgroups = g1
a1.sinkgroups.g1.sinks = k1 k2
a1.sinkgroups.g1.processor.type = failover
\## 对两个sink分配不同的优先级
a1.sinkgroups.g1.processor.priority.k1 = 200
a1.sinkgroups.g1.processor.priority.k2 = 100
\## 主sink失败后,停用惩罚时间
a1.sinkgroups.g1.processor.maxpenalty = 5000
(2)模式2:Load balancing Sink Processor负载均衡
允许channel中的数据在一组sink中的多个sink之间进行轮转,策略有:
****round-robin****(轮着发)
****random****(随机挑)
a1.sinkgroups = g1
a1.sinkgroups.g1.sinks = k1 k2
a1.sinkgroups.g1.processor.type = load_balance
a1.sinkgroups.g1.processor.backoff = true
a1.sinkgroups.g1.processor.selector = random
2、实现第二级高可用:
在传输过程中做分流处理,第二级中设置两个或多个agent,实现第二级的高可用。