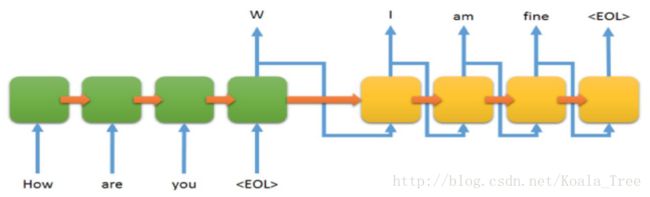
循环神经网络RNN
循环神经网络RNN
1. 循环神经网络RNN原理
工作过程
- 文本处理(训练)
- 一个神经元,不同时刻
- 每个时刻都有输出
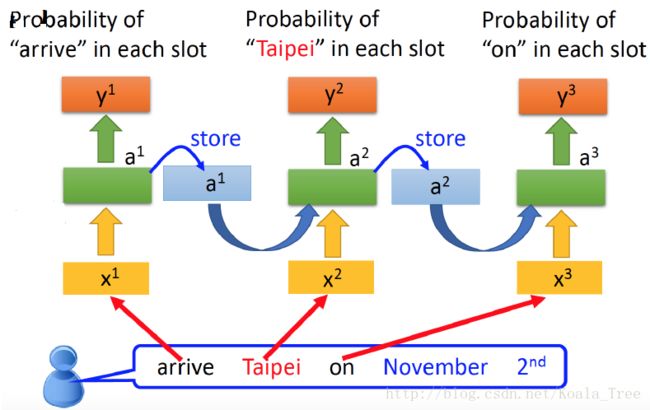
表达式
1.正向传播

其中,b 和c分别表示偏置向量,权重矩阵U、V 和W分别对应于输入到隐藏、隐藏到输出和隐藏到隐藏的连接 。
2.损失函数

3.反向计算
- 参数优化方法:同传统神经网络一样,梯度下降;
- 计算损失函数对参数的导数;
- 每个输出都对参数有影响;
对参数的导数为各个输出 ∂E∂W=∑t∂Et∂W 对参数导数之和。
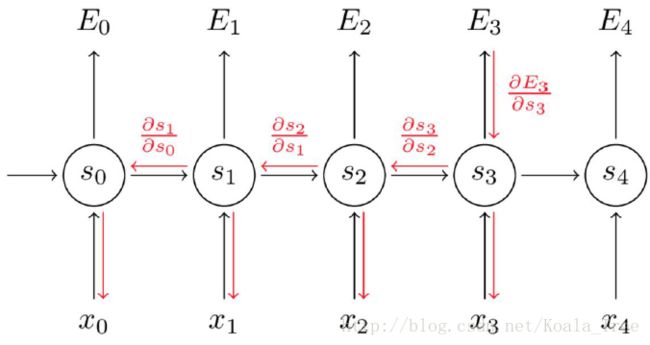
以 E3 为例: E3 由 t0−t3 时刻 x,W 共同确定。
∂E3∂w=∑k=03∂s3∂sk⋅∂sk∂w⋅Δs3
结构
1.多层网络
类比传统神经网络单层到多层的结构变化,额外添加上层前一状态。
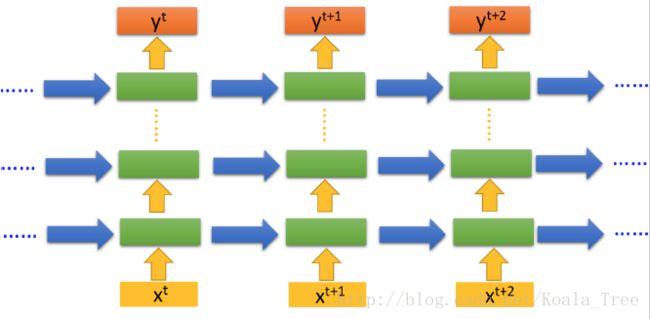
2. 双向网络
输入信息正向、反向来输入RNN。这是由于信息的依赖关系顺序不是一定的。

Vanishing Gradient 问题
注意到 ∂s3∂sk 也需要使用链式法则,例如 ∂s3∂s1=∂s3∂s2⋅∂s2∂s1 。注意到因为我们是用向量函数对向量求导数,结果是一个矩阵(称为Jacobian Matrix),矩阵元素是每个点的导数。我们可以把上面的梯度重写成:
可以证明上面的Jacobian矩阵的二范数(可以认为是一个绝对值)的上界是1。这很直观,因为激活函数tanh把所有制映射到-1和1之间,导数值得界限也是1:
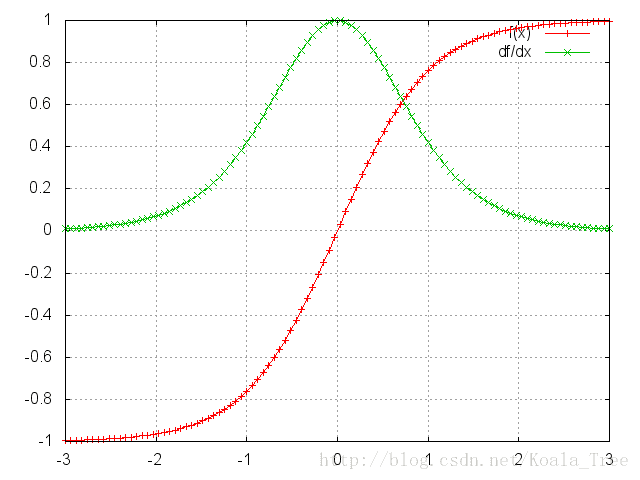
看到tanh和sigmoid函数在两端的梯度值都为0,接近于平行线。当这种情况出现时,我们就认为相应的神经元饱和了。它们的梯度为0使得前面层的梯度也为0。
矩阵中存在比较小的值,多个矩阵相乘会使梯度值以指数级速度下降,最终在几步后完全消失。比较远的时刻的梯度值为0,这些时刻的状态对学习过程没有帮助,导致你无法学习到长距离依赖。
消失梯度问题不仅出现在RNN中,同样也出现在深度前向神经网中。只是RNN通常比较深(例子中深度和句子长度一致),使得这个问题更加普遍。
很容易想到,依赖于我们的激活函数和网络参数,如果Jacobian矩阵中的值太大,会产生梯度爆炸而不是梯度消失问题。
梯度消失比梯度爆炸受到了更多的关注有两方面的原因。其一,梯度爆炸容易发现,梯度值会变成NaN,导致程序崩溃。其二,用预定义的阈值裁剪梯度可以简单有效的解决梯度爆炸问题。梯度消失出现的时候不那么明显而且不好处理。
影响:较长的记忆无法产生作用。
解决方式:
- 非线性激励更换;
- LSTM长短记忆单元。
2. 升级版RNN:LSTM
RNN局限
1. 前后依赖
I am from China, I speak Chinese.
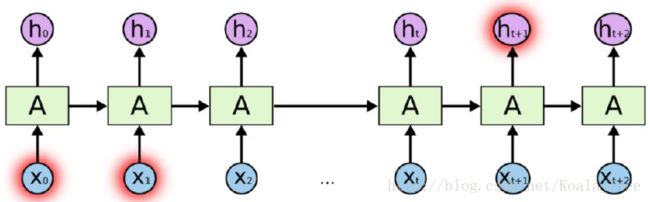
这里,China -> Chinese,起到决定性作用,但是距离太远难以产生关联。
2. 解决方案
设计Gate, 保存重要的记忆,使用LSTM。

LSTM形成
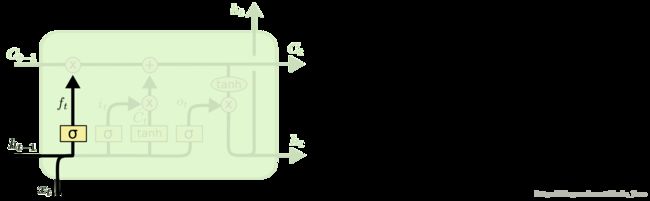
Ct 是信息流控制的关键,参数决定了 ht 传递过程中,哪些被保存或者舍弃。该参数被Gate影响。
LSTM 的关键就是细胞状态,水平线在图上方贯穿运行。
细胞状态类似于传送带。直接在整个链上运行,只有一些少量的线性交互。信息在上面流传保持不变会很容易。

LSTM 有通过精心设计的称作为“门”的结构来去除或者增加信息到细胞状态的能力。门是一种让信息选择式通过的方法。他们包含一个 sigmoid 神经网络层和一个 pointwise 乘法操作。
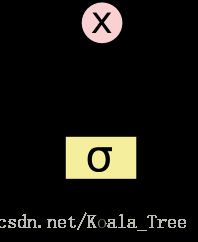
Sigmoid 层输出 0 到 1 之间的数值,描述每个部分有多少量可以通过。0 代表“不许任何量通过”,1 就指“允许任意量通过”!
LSTM 拥有三个门,来保护和控制细胞状态。
逐步理解LSTM
1. 第一步:对旧的信息进行去除
- 新输入 xt 的前一状态 ht−1 决定C的哪些信息可以舍弃;
- ft 与 Ct−1 运算,对部分信息进行去除。
这个决定通过一个称为忘记门层完成。该门会读取 ht−1 和 xt ,输出一个在 0 到 1 之间的数值给每个在细胞状态 Ct−1 中的数字。1 表示“完全保留”,0 表示“完全舍弃”。
在语言模型的例子中来基于已经看到的预测下一个词。在这个问题中,细胞状态可能包含当前主语的性别,因此正确的代词可以被选择出来。当我们看到新的主语,我们希望忘记旧的主语。
2. 第二步:确定什么样的新信息被保存
- 新输入 xt 前一状态 ht−1 告诉C哪些信息想要保存;
- it :新信息添加时的系数或叫控制参数(对比 ft );
- C~t 为产生的新的候选信息向量,结合 it 系数,用于对 Ct 进行更新。
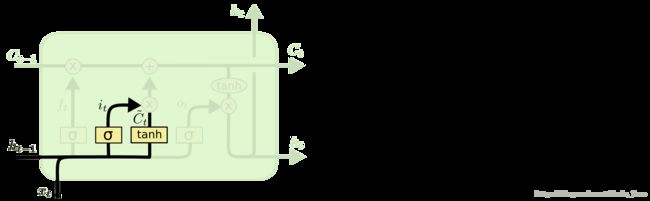
在语言模型的例子中,我们希望增加新的主语的性别到细胞状态中,来替代旧的需要忘记的主语。
3. 第三步:更新旧信息状态
- 把旧状态 Ct−1 与 ft 相乘,丢弃掉我们确定需要丢弃的信息;
- 接着加上 it∗C~t 这就是新的信息候选值,根据我们决定更新每个状态的程度进行变化。
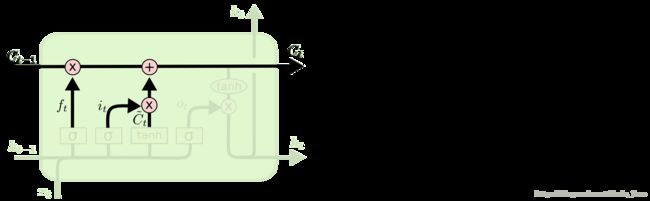
在语言模型的例子中,这就是我们实际根据前面确定的目标,丢弃旧代词的性别信息并添加新的信息的地方。
4. 第四步:确定输出的信息
- 首先,运行一个 sigmoid 层来确定细胞状态的哪个部分将输出出去;
- 接着,把细胞状态通过 tanh 进行处理(得到一个在 -1 到 1 之间的值)并将它和 sigmoid 门的输出相乘;
- 最终仅仅会输出我们确定输出的那部分。
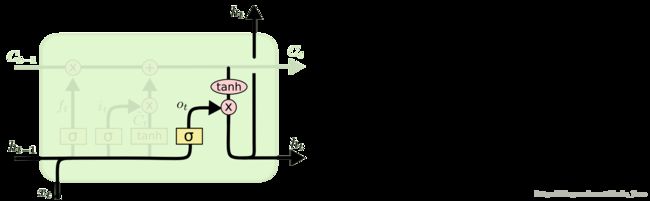
在语言模型的例子中,因为他就看到了一个 代词,可能需要输出与一个 动词 相关的信息。例如,可能输出是否代词是单数还是负数,这样如果是动词的话,我们也知道动词需要进行的词形变化。
问题: Gate的作用在哪里?有用的信息如何保存?
Answer:
- Gate 输出 it,ft,ot ,用来引导 Ct 的生成;
- 训练后, Ct 的相关参数为,这样便可以保存有用的信息。
LSTM的变种
1. Peephole connection
让”门层”也会接受细胞状态的输入,即 Ct−1 会影响 ft,it,ot 。

上面的图例中,增加了 peephole 到每个门上,但是一些实现中会加入部分的 peephole 而非所有都加。
2. Gate忘记/更新不再独立
通过使用 coupled 忘记和输入门。不同于之前是分开确定什么忘记和需要添加什么新的信息,这里是一同做出决定。
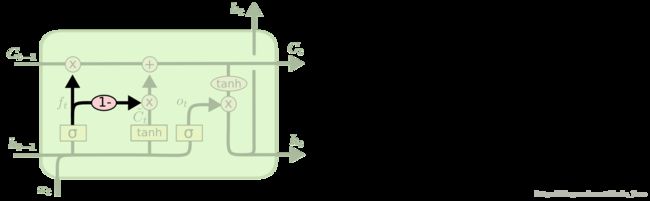
遗忘和更新部分互为补充。
3. Gated Recurrent Unit (GRU)
- 遗忘、更新Gate做结合(既不是独立,又不是互补)
- 控制参数 Ct 与输出 ht 结合,直接产生带有长短记忆能力的输出。

其中, zt 用于更新, rt 用于遗忘, h~t 则为临时控制参数的变形。
3. 语言处理特征提取:Word2Vec
- 语言文本信息:其表达形式为字符串形式,对于计算机来说是难以直接理解的;
- 机器学习处理信息:输入输出数据的形式一般为向量、多维数组。
Word2Vec
1. 建立字典
每个词生成one-hot向量。
如:Word个数为n,产生n维向量,第i个Word的向量为(0,0,…,1,0,0,0,…),1处于第i个位置。
2. 训练数据集构建
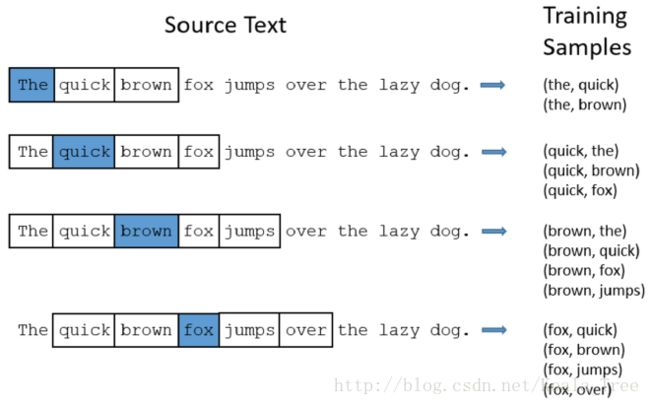
通过原文本,建立一些词与词之间的词对,这些词对作为候命要继续训练的样本。
3. 简单神经网络
简易三层神经网络,各层神经元个数:N-m-N;
学习的是词语到临近词的映射。
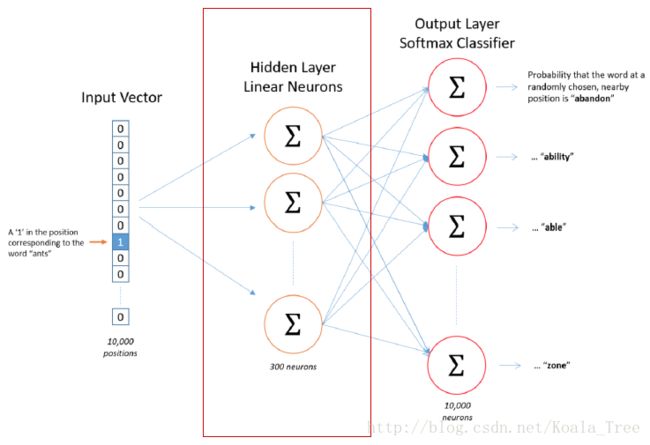
4. 生成最终的Vec
训练model进行特征提取;
每个one-hot对应一个300-d的向量;
生成最终的look up word table。
Word2Vec 特点
- 利用上下文(context)进行学习,两个词上下文类似,生成的vector会接近;
- 具有类比特性,king-queen+female = male;
- 字符->数据,方便使用机器学习算法进行处理。
LSTM语言的生成:
- word形式:Word2Vec;
- 训练过程:words->word;
- LSTM网络只有最后输出有用。