python行程风险测评系统
目录
任务需求
解决思路
具体实现
环境配置
识别算法
正则匹配
结果写入
总代码
main.py
ocr.py
search.py
结果示意
程序使用说明及风险
打包虚拟环境
全部依赖包
原创的概念:只要把查到的资源充分吸收理解,产出新的内容,就是原创
链接:https://pan.baidu.com/s/18sEKO8dac5AlejyJMFGKZA
提取码:0505
--来自百度网盘超级会员V4的分享
任务需求
以大型培训班、教育为背景,来自五湖四海的学生教师通常需要进行来往地区的风险测评。我们需要每天对人员进行风险筛查,判断是否有学员、教师来自中高风险地区;筛查后还要有专门人员对风险地区名单进行复查,防止误判。此外,风险筛查情况需要实时更新,防止疫情风险情况更新而没有及时采取有效措施。
例:10.1日风险地区有:A省B市,A省C市
成员1 来自A省B市,成员2 来自F省G市,…… 成员1来自中高风险地区
10.2日风险地区有:A省B市,A省C市,F省G市
成员1 来自A省B市,成员2 来自F省G市,…… 成员1、2来自中高风险地区
10.3日风险地区有:A省C市,F省G市
成员1 来自A省B市,成员2 来自F省G市,…… 成员2来自中高风险地区
解决思路
-
收集每个成员的行程码,使用百度API对图像进行文字提取;再用正则表达式提取出其中的行程。由于行程码需要每天上交,所以似乎不需要将结果进行存储。
-
将每个人的行程在官方下发的Word文档中查找,记录每个人的结果(是否途径风险地区)
-
结果写入Excel,并保证每日更新
注:这次要求做一个简单的小程序,不涉及Web、服务器等复杂内容,这反而让我和我的电脑有点点不适应,因为很多conda环境是在服务器上的
具体实现
环境配置
这次的核心识别使用的是百度飞桨,因为之前用过的easyocr是以本机深度学习环境为基础的,所以如果长期使用CPU运行势必遭到“反噬”,因此这次使用百度飞桨paddlepaddle、paddleocr两个库作为核心算法。
在本机配置好anaconda的环境后,开始创建虚拟环境搭建运行依赖(python3.8)。
conda create -n paddle38 python=3.8接下来,安装paddlepaddle、paddleocr,推荐使用阿里源:
pip install paddleocr -i http://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com
pip install paddlepaddle -i http://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com下载项目和权重(版本号确定,但是链接不一定有效):
git clone https://github.com/PaddlePaddle/PaddleOCR.git
官网来源:https://www.paddlepaddle.org.cn/modelsDetail?modelId=17
检测权重
https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_PP-OCRv3_det_slim_infer.tar
方向分类权重
https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_slim_infer.tar
识别权重
https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_PP-OCRv3_rec_slim_infer.tar识别图片结果如下,可以看到效果非常好
 图1 识别效果
图1 识别效果
conda paddle38虚拟环境的所有配置如下:
(paddle38) D:\OneDrive\桌面\python_Lab\E42014039_杨浩然_实验6\PaddleOCR>conda list # packages in environment at D:\anaconda3\envs\paddle38: # # Name Version Build Channel astor 0.8.1 pypi_0 pypi attrdict 2.0.1 pypi_0 pypi babel 2.11.0 pypi_0 pypi bce-python-sdk 0.8.74 pypi_0 pypi beautifulsoup4 4.11.1 pypi_0 pypi ca-certificates 2022.10.11 haa95532_0 cachetools 5.2.0 pypi_0 pypi certifi 2022.9.24 py38haa95532_0 charset-normalizer 2.1.1 pypi_0 pypi click 8.1.3 pypi_0 pypi colorama 0.4.6 pypi_0 pypi contourpy 1.0.6 pypi_0 pypi cssselect 1.2.0 pypi_0 pypi cssutils 2.6.0 pypi_0 pypi cycler 0.11.0 pypi_0 pypi cython 0.29.32 pypi_0 pypi decorator 5.1.1 pypi_0 pypi dill 0.3.6 pypi_0 pypi et-xmlfile 1.1.0 pypi_0 pypi fire 0.4.0 pypi_0 pypi flask 2.2.2 pypi_0 pypi flask-babel 2.0.0 pypi_0 pypi fonttools 4.38.0 pypi_0 pypi future 0.18.2 pypi_0 pypi idna 3.4 pypi_0 pypi imageio 2.22.4 pypi_0 pypi imgaug 0.4.0 pypi_0 pypi importlib-metadata 5.1.0 pypi_0 pypi itsdangerous 2.1.2 pypi_0 pypi jinja2 3.1.2 pypi_0 pypi kiwisolver 1.4.4 pypi_0 pypi lanms-neo 1.0.2 pypi_0 pypi libffi 3.4.2 hd77b12b_6 lmdb 1.3.0 pypi_0 pypi lxml 4.9.1 pypi_0 pypi markupsafe 2.1.1 pypi_0 pypi matplotlib 3.6.2 pypi_0 pypi multiprocess 0.70.14 pypi_0 pypi networkx 2.8.8 pypi_0 pypi numpy 1.23.5 pypi_0 pypi opencv-contrib-python 4.6.0.66 pypi_0 pypi opencv-python 4.6.0.66 pypi_0 pypi openpyxl 3.0.10 pypi_0 pypi openssl 1.1.1s h2bbff1b_0 opt-einsum 3.3.0 pypi_0 pypi packaging 21.3 pypi_0 pypi paddle-bfloat 0.1.7 pypi_0 pypi paddleocr 2.6.1.1 pypi_0 pypi paddlepaddle 2.4.0 pypi_0 pypi pandas 1.5.2 pypi_0 pypi pdf2docx 0.5.6 pypi_0 pypi pillow 9.3.0 pypi_0 pypi pip 22.2.2 py38haa95532_0 polygon3 3.0.9.1 pypi_0 pypi premailer 3.10.0 pypi_0 pypi protobuf 3.20.0 pypi_0 pypi pyclipper 1.3.0.post4 pypi_0 pypi pycryptodome 3.16.0 pypi_0 pypi pymupdf 1.20.2 pypi_0 pypi pyparsing 3.0.9 pypi_0 pypi pypiwin32 223 pypi_0 pypi python 3.8.15 h6244533_2 python-dateutil 2.8.2 pypi_0 pypi python-docx 0.8.11 pypi_0 pypi pytz 2022.6 pypi_0 pypi pywavelets 1.4.1 pypi_0 pypi pywin32 305 pypi_0 pypi rapidfuzz 2.13.2 pypi_0 pypi requests 2.28.1 pypi_0 pypi scikit-image 0.19.3 pypi_0 pypi scipy 1.9.3 pypi_0 pypi setuptools 65.5.0 py38haa95532_0 shapely 1.8.5.post1 pypi_0 pypi six 1.16.0 pypi_0 pypi soupsieve 2.3.2.post1 pypi_0 pypi sqlite 3.40.0 h2bbff1b_0 termcolor 2.1.1 pypi_0 pypi tifffile 2022.10.10 pypi_0 pypi tqdm 4.64.1 pypi_0 pypi urllib3 1.26.13 pypi_0 pypi vc 14.2 h21ff451_1 visualdl 2.4.1 pypi_0 pypi vs2015_runtime 14.27.29016 h5e58377_2 werkzeug 2.2.2 pypi_0 pypi wheel 0.37.1 pyhd3eb1b0_0 wincertstore 0.2 py38haa95532_2 zipp 3.11.0 pypi_0 pypi
识别算法
识别部分的代码如下:
from paddleocr import PaddleOCR, draw_ocr
ocr = PaddleOCR(use_angle_cls=True, det_model_dir="./inference/ch_PP-OCRv3_det_slim_infer/",
cls_model_dir="./inference/ch_ppocr_mobile_v2.0_cls_slim_infer/",
rec_model_dir="./inference/ch_PP-OCRv3_rec_slim_infer/",
use_gpu=False)
img_path = r"D:\OneDrive\桌面\python_Lab\E42014039_杨浩然_实验6\PaddleOCR\images\test.jpg"
result = ocr.ocr(img_path, cls=True)
# 显示结果
# from PIL import Image
# image = Image.open(img_path).convert('RGB')
# boxes = [line[0] for line in result]
# txts = [line[1][0] for line in result]
# scores = [line[1][1] for line in result]
# im_show = draw_ocr(image, boxes, txts, scores)
# im_show = Image.fromarray(im_show)
# im_show.save('result.jpg') 前半段代码需要文件目录,内容如下。其中的训练包经过很多次的迭代更换,最终成功。
inference: │ ch_PP-OCRv3_det_slim_infer.tar │ ch_PP-OCRv3_rec_slim_infer.tar │ ch_ppocr_mobile_v2.0_cls_slim_infer.tar │ ├─ch_PP-OCRv3_det_slim_infer │ inference.pdiparams │ inference.pdiparams.info │ inference.pdmodel │ ├─ch_PP-OCRv3_rec_slim_infer │ inference.pdiparams │ inference.pdiparams.info │ inference.pdmodel │ └─ch_ppocr_mobile_v2.0_cls_slim_infer ._inference.pdiparams ._inference.pdiparams.info ._inference.pdmodel ._paddle_infer.log inference.pdiparams inference.pdiparams.info inference.pdmodel paddle_infer.log
后半部分即可做出图1的效果,但这显然不是我们需要的,其中boxes,txts,scores三个变量也没有提取出文字信息,所以我直接将result结果转换为str,再正则筛选出中文和标点,代码如下:
import re
def find_chinese(file):
chinese = re.findall('[\u3002\uff1b\uff0c\uff1a\u201c\u201d\uff08\uff09\u3001\uff1f\u300a\u300b\u4e00-\u9fa5]',file)
return ''.join(chinese)
# ...
result = str(result)
result = find_chinese(result)下面我们需要把代码封装一下,之后将整个文件夹的图片送入识别并写入txt,看看结果如何。这里解释一下,我没有找到相关的测试集,所以可靠性有待验证(例如省市地区生僻字)。
2022-12-04 22:12:03:安徽省合肥市 2022-12-04 22:12:09:安徽省合肥市 2022-12-04 22:12:14:广东省深圳市,西藏自治区拉萨市,河北省石家庄市,湖北省十堰市
结果中有多点值得夸奖,也很让人惊喜,百度飞桨名不虚传!
-
识别算法中,支持中文路径,而
easyocr是不允许的! -
速度快的惊人,10张图片在一个正常笔记本算力的运行环境下,只需要61s!
-
识别很精准,目前来看百度飞桨的性价比非常高!
正则匹配
下面,需要将每次的结果爬出来,存入一个“数据库”。可以观察到:
“到达或途经安徽省合肥市结果包含”
我们需要的结果被夹在几个非常确定的字段,这个正则可以作为期末考试的一个小题。
...
re1 = r'到达或途经(.*?)结果包含'
reResult = re.findall(re1, str1)
print(reResult)匹配出中间的结果,理论上可以直接取word文档中查找,但是如果经过多个地区,行程显示为:xxx、xxx。
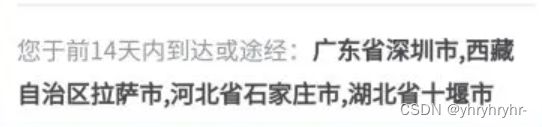
这样的字段在word文档中肯定是找不到的,所以我们必须将他当成列表处理。将读取的字符串按照中文逗号分割成列表,在word文档中逐个地区进行查找(实际上是将word整个文本拖到txt中再查找),如果找到则标为疑似途径风险地区,反之则视为安全。代码如下:
result_list = ocr.paddleocr(path)
for item in result_list:
area_list = str(item).split(",") # 中文逗号!
index += 1
for i in range(len(area_list)):
flag = search.find_risk(area_list[i])
if flag != 0:
ocr.sheet.cell(index, 5, "有风险")
break
ocr.sheet.cell(index, 5, "无风险")
ocr.bg.save(r"result.xlsx")
# 输出
检索内容: 广东省深圳市 无风险
检索内容: 西藏自治区拉萨市 无风险
检索内容: 河北省石家庄市 无风险
检索内容: 湖北省十堰市 无风险
检索内容: 安徽省合肥市 无风险
检索内容: 安徽省合肥市 无风险结果写入
我们假设大家都能按照 学号_姓名 来进行文件命名(当然这是不可能的),将学号、姓名、检测时间、途径地区、检测结果写入excel,这里也考虑了基于一个.xlsx名单进行操作,但考虑到可能造成不方便,所以直接写入一张新的表格,再人工进行筛选(段老师:人工总要做点事情的)
try:
img_path = img_root_path + r"\\" + file
index += 1
filename = file.split("_")
sheet.cell(index, 1, filename[0])
sheet.cell(index, 2, filename[1].split(".")[0])
result = ocr.ocr(img_path, cls=True)
result = str(result)
result = find_chinese(result)
re1 = r'到达或途经(.*?)结果包含'
except:
sheet.cell(index, 1, "文件名异常")
sheet.cell(index, 2, "文件名异常")
try:
result = str(re.findall(re1, result)[0]).replace(":", '')
timenow = datetime.fromtimestamp(int(time.time()),
pytz.timezone('Asia/Shanghai')).strftime('%Y-%m-%d %H:%M:%S')
sheet.cell(index, 3, timenow)
sheet.cell(index, 4, result)
bg.save(r"result.xlsx")
result_list.append(result)
with open("result.txt", "a") as f: # 打开文件
f.write(timenow + result + "\n")
except:
sheet.cell(index, 3, "无法读取行程")
sheet.cell(index, 4, "无法读取行程")
result_list.append("无法读取行程")总代码
代码封装成3个文件:
main.py:组织调配,负责整体逻辑
ocr.py:提取图片文字,并写入结果
search.py:搜索文档,判断是否经过危险地区
main.py
import ocr
import search
with open("result.txt", 'r+') as file: # 清空文件历史信息
file.truncate(0)
path = r"D:\OneDrive\桌面\python_Lab\E42014039_杨浩然_实验6\PaddleOCR\images" # 图片目录
filepath = r"D:\OneDrive\桌面\python_Lab\E42014039_杨浩然_实验6\疫情风险地区提示单.docx" # 官方文件
flag = 0
index = 0
ocr.path = path
search.file_path = filepath
result_list = ocr.paddleocr(path)
for item in result_list:
area_list = str(item).split(",") # 中文逗号!
index += 1
for i in range(len(area_list)):
flag = search.find_risk(area_list[i])
if flag != 0:
ocr.sheet.cell(index, 5, "有风险")
break
ocr.sheet.cell(index, 5, "无风险")
ocr.bg.save(r"result.xlsx")ocr.py
from paddleocr import PaddleOCR
import re
import os
import time
from datetime import datetime
import pytz
import openpyxl as op
path = r""
result_list = []
bg = op.load_workbook(r"result.xlsx")
bg.remove(bg["Sheet1"])
bg.create_sheet("Sheet1", index=0)
sheet = bg["Sheet1"]
sheet.cell(1, 1, "学号"), sheet.cell(1, 2, "姓名"), sheet.cell(1, 3, "检测时间"), sheet.cell(1, 4, "途径地区")
sheet.cell(1, 5, "检测结果")
def find_chinese(file):
chinese = re.findall('[\u3002\uff1b\uff0c\uff1a\u201c\u201d\uff08\uff09\u3001\uff1f\u300a\u300b\u4e00-\u9fa5]',
file)
return ''.join(chinese)
def paddleocr(img_root_path):
# 模型路径下必须含有model和params文件
global re1, result
ocr = PaddleOCR(use_angle_cls=True, det_model_dir="./inference/ch_PP-OCRv3_det_slim_infer/",
cls_model_dir="./inference/ch_ppocr_mobile_v2.0_cls_slim_infer/",
rec_model_dir="./inference/ch_PP-OCRv3_rec_slim_infer/",
use_gpu=False)
dirlist = os.listdir(img_root_path)
index = 0
for file in dirlist:
try:
img_path = img_root_path + r"\\" + file
index += 1
filename = file.split("_")
sheet.cell(index, 1, filename[0])
sheet.cell(index, 2, filename[1].split(".")[0])
result = ocr.ocr(img_path, cls=True)
result = str(result)
result = find_chinese(result)
re1 = r'到达或途经(.*?)结果包含'
except:
sheet.cell(index, 1, "文件名异常")
sheet.cell(index, 2, "文件名异常")
try:
result = str(re.findall(re1, result)[0]).replace(":", '')
timenow = datetime.fromtimestamp(int(time.time()),
pytz.timezone('Asia/Shanghai')).strftime('%Y-%m-%d %H:%M:%S')
sheet.cell(index, 3, timenow)
sheet.cell(index, 4, result)
bg.save(r"result.xlsx")
result_list.append(result)
with open("result.txt", "a") as f: # 打开文件
f.write(timenow + result + "\n")
except:
sheet.cell(index, 3, "无法读取行程")
sheet.cell(index, 4, "无法读取行程")
result_list.append("无法读取行程")
return result_listsearch.py
import docx
file_path = r"D:\OneDrive\桌面\python_Lab\E42014039_杨浩然_实验6\疫情风险地区提示单.docx"
def getText(fileName):
doc = docx.Document(fileName)
TextList = []
for paragraph in doc.paragraphs:
TextList.append(paragraph.text)
return '\n'.join(TextList)
txt = getText(file_path)
with open("covid.txt", "w") as f:
f.write(str(txt))
def find_risk(text):
# print("检索内容:", text)
if str(text) in txt:
return 1
else:
return 0结果示意

现在从合肥到烟台,行程码也发生了变化,正好可以用来做测试。
真是万万没想到啊,中国的大数据行程码是用英文逗号进行分割,这样的话程序的正则匹配需要大改。由于防止再次发生变化,我准备了两套正则匹配表达式。
def find_chinese(file):
chinese = file.translate(str.maketrans("", "", "[].1234567890''*%()")).replace(", , , , , , , , , ,", "").replace(
" ", "").replace(",", ",")
# chinese = re.findall('[\u3002\uff1b\uff0c\uff1a\u201c\u201d\uff08\uff09\u3001\uff1f\u300a\u300b\u4e00-\u9fa5]',
# file)
# return ''.join(chinese)
return chinese没有被注释掉的是当下使用的(中间分割为英文逗号),注释掉的是中文逗号,可以随时切换。
测试如下,非常成功。
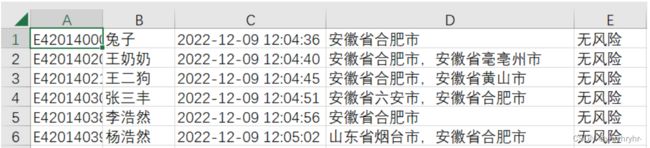
程序使用说明及风险
用户将main.py中word文档和images的路径更改,结果会自动写入result.xlsx并且每次运行会更新。result.txt、covid.txt是中间文件,可以忽略和删除。
存在的风险:
-
官方文档发生变化,搜索省+市的名字不能达到预期目标
-
学生不按照正常的方式命名
-
行程码发生变化,导致正则表达式失效
打包虚拟环境
conda install -c conda-forge conda-pack
conda pack -n paddle38 -o env.zip
// 生成相应依赖
pipreqs ./ --encoding=utf8
conda list -e > requirements.txt
使用者只需要解压环境,即可使用。
全部依赖包
安装命令:
pip install -r requirements.txt -i http://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com
apted==1.0.3
beautifulsoup4==4.11.1
Cython==0.29.32
docx==0.2.4
editdistance==0.6.1
fasttext==0.9.2
fitz==0.0.1.dev2
imgaug==0.4.0
lanms==1.0.2
lanms_neo==1.0.2
lmdb==1.3.0
lxml==4.9.1
numpy==1.21.5
onnxruntime==1.13.1
opencv_python==4.6.0.66
openpyxl==3.0.10
paddle_serving_app==0.9.0
paddle_serving_client==0.9.0
paddle_serving_server==0.9.0
paddle_serving_server_gpu==0.9.0.post1028
paddleclas==2.5.1
paddlehub==2.3.1
paddlenlp==2.4.4
paddleslim==2.4.0
pandas==1.4.4
pdf2docx==0.5.6
Pillow==9.3.0
Polygon==1.1.0
premailer==3.10.0
pyclipper==1.3.0.post4
PyMuPDF==1.20.2
PyQt4==4.11.4
PyQt5==5.15.7
python_docx==0.8.11
pytz==2022.1
pywin32==302
PyYAML==6.0
QtPy==2.2.0
rapidfuzz==2.13.2
requests==2.28.1
scikit_image==0.19.2
scipy==1.9.1
seqeval==1.2.2
setuptools==63.4.1
Shapely==1.8.5.post1
sip==6.7.5
six==1.16.0
skimage==0.0
tqdm==4.64.1
visualdl==2.4.1
wandb==0.13.5
xlrd==2.0.1