MySQL哈希索引以及InnoDB自适应哈希索引
文章目录
-
- 一、哈希索引
- 二、InnoDB自适应哈希索引
一、哈希索引
哈希索引是基于内存的支持,底层结构就是链式哈希表,增删改查的时间复杂度都是O(1),一断电就没了,因为内存搜索,哈希表是最快的
而平衡树的增删改查的时间复杂度是 O ( l o n g 2 n ) O(long_2n) O(long2n),此外B+树索引是把磁盘上的存储的索引加载到内存上构建的数据结构。
看起来哈希表比B+树好,那为什么MyISAM和InnoDB存储引擎用的是B+树索引?
我们主要看
- 搜索的效率
- 磁盘I/O的花费
我们改用创建哈希索引来看看:

查看索引的底层实现,应使用如下语句:
show indexes from student;
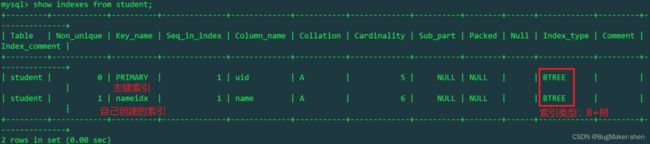
假设我们给name字段创建哈希索引
构建链式哈希表:根据选定的哈希函数,把每一行记录的name字段作为参数来求一个哈希值,哈希值对桶的长度取模得到桶的序号(会产生哈希冲突),然后进行存储。索引值和数据存储在一起,类似于InnoDB
解决哈希冲突的方式:在桶里面用链表串起来(链地址法)
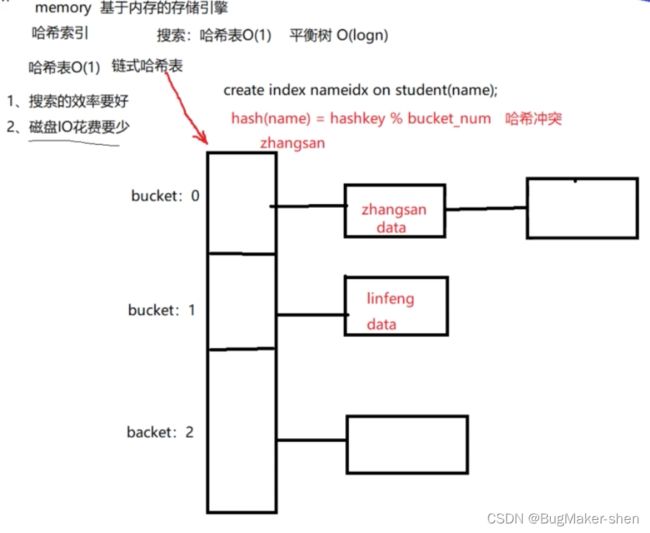
注意:虽然链式哈希表的桶看起来有顺序,实际上存储的索引值是没有任何顺序的,不仅是桶之间没有顺序,桶内元素也没有任何顺序。因为我们用哈希函数进行了计算,然后还进行了取模的操作,不可能说我输入的索引值的字典序小,就一定在需要小的桶里面
链式哈希表快仅仅只是在等值查找的时候快,比如:
select * from student name="zhangsan";
一旦我们进行范围查找、模糊查找等一系列操作时,链式哈希表就无能为力了,比如:
select * from student name like "zhang%";
此时搜索引擎完全不知道前缀是zhang的数据在哪,也不知道给哈希函数输入什么,这个时候只能做整表搜索,也就是 O ( n ) O(n) O(n)
此外假设age也有哈希索引,如下的查找方式,哈希表就需要计算18~30所有的哈希值,然后查找数据
select * from student where age between 18 and 30;
在哈希表中,不同元素,哪怕是15和16,通过求哈希值,模上桶的个数,最后存储的位置可能会相隔很远。如果用链式哈希表构建索引,一个桶里面的节点代表1次磁盘I/O,由于桶内元素也是没有顺序的,我们进行查找的时候都会遍历完所有的桶内节点,就会导致更多的磁盘I/O。
哈希索引只适用于小数据量的,在内存上的等值查询,处理不在磁盘的数据,并不能为我们减少磁盘I/O的次数!!!
总结:
- 由于我们绝大部分的数据都是存放在磁盘的,哈希索引没办法减少磁盘I/O的次数,从磁盘上加载数据到内存的次数太多
- 由于不同的索引值经过哈希函数计算以及取模后,最后存储的位置非常不确定,没有任何的顺序,故不适用于多数的应用场景,比如范围、模糊、排序等等
- 此外一旦哈希表扩容,就会导致所有的索引值重新计算存储位置,效率很低
二、InnoDB自适应哈希索引
假如name是有索引的,我们不断使用如下的方式查询,那就得先访问name的二级索引树,从二级索引树上取出主键uid,然后回表,用这个uid去主键索引树上取得对应的数据
select * from student where name = "zhangsan";
select * from student where name = "gaoyang";
select * from student where name = "linfeng";
...
The hash index is always built based on an existing B-tree index on the table. InnoDB can build a hash index on a prefix of any length if the key defined for the B-tree
InnoDB存储引擎会做如下优化:如果检测到某个二级索引不断被使用,二级索引成为热数据,那么InnoDB会根据在二级索引树上的索引值在构建一个哈希索引来加速搜索(只适用于等值比较)
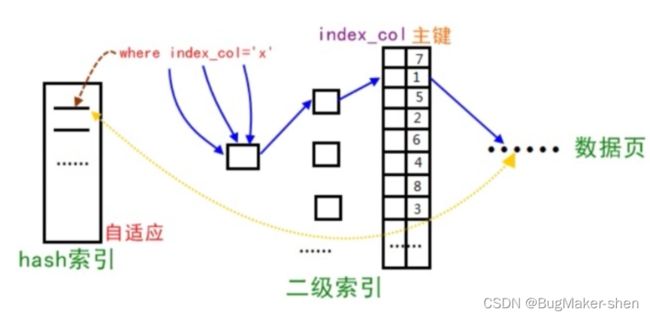
图中蓝色的箭头表示不建立哈希索引,搜索二级索引树然后回表的过程
黄色箭头就是直接等值比较搜索哈希表,直接拿到数据地址的过程。使用哈希索引 O ( 1 ) O(1) O(1)的时间复杂度就访问到哈希索引name,然后取出data即可(对于InnoDB来说应该是直接取得数据,而不是拿到数据地址后再访问)
注意:hash索引的生成和维护也是耗费性能的,并不能绝对的在任何场景下提高对二级索引的搜索效率,我们可以查看相关参数指标,如果自适应哈希索引可以提高效率,那我们使用它,否则我们就关闭它
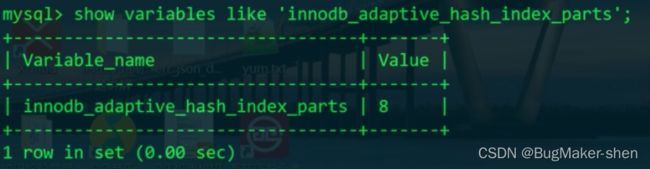
自适应哈希索引是默认开启的:

在MySQL5.7以前,操作哈希表是只有一把锁的,锁的粒度太大,效率很低。在MySQL5.7以后,每个分区都会有自己的锁,锁的粒度减小,要是各个线程在同一个分区(一个分区可以包含一个或多个桶)进行并发操作,就需要加锁。要是在不同的分区操作,就不用加锁。
You can monitor the use of the adaptive hash index and the contention for its use in the SEMAPHORES section of the output of the SHOW ENGINE INNODB STATUS command. If you see many threads waiting on an RW-latch created in btrOsea.c, then it might be useful to disable adaptive hash indexing.
在并发环境中,如果同一个分区等待的线程过多,这个时候需要考虑关闭自适应哈希索引
我们通过以下命令查看两个关键信息:
show engine innodb status\G
- RW-latch等待线程的数量,自适应哈希索引默认分配了8个分区,若某个分区等待的线程数量过多,则需要考虑关闭自适应哈希索引
- 使用AHI搜索的频率低于不使用AHI搜索的频率,也需要考虑关闭自适应哈希索引
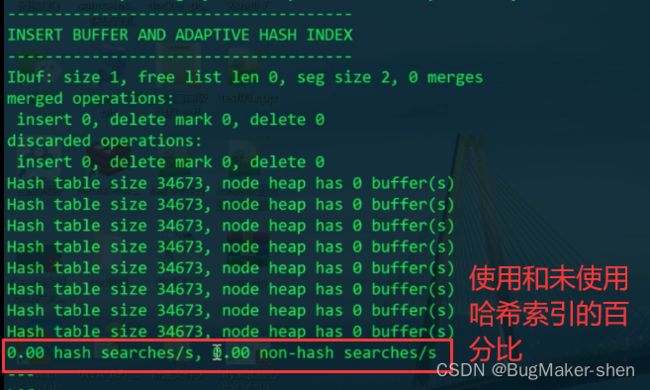
项目中如果遇到并发量很大,服务器处理请求慢时,可以使用show engine innodb status\G查看是否需要关闭AHI,也是提高数据库性能的一种方式