一篇关于利用numba加速python运行效率的笔记
一篇关于加速python代码运行效率的笔记
-
-
-
- 一、原始代码(部分)分析
- 二、变量预分配内存实现加速
- 三、numba装饰器实现加速
-
- 3.1 为什么numba可以对python代码加速?
- 3.2 修改代码匹配numba的类型支持
- 四、其它尝试
-
- 4.1 多线程的思考
- 4.2 数据结构的其它尝试
- 参考文章
-
-
- 问题描述: 最近在跑一段python代码,代码的主要功能是对fastq格式的基因数据通过2阶Markov过程构建一个频率表,频率表的格式大概是{(34,45): [23,2, 35,6, 23,1], (23,35): [33,1]}这种形式,可以简化为(34,45,23,2),最后一位为(34,45,23)三元组在数据集中出现的次数。在计算过程中涉及到大量的for循环操作,在数据集为200M时,耗时将近3小时(单线程。硬件:),导师说numba对于for循环可以有很好的加速效果,试试用numba把程序降到30分钟。
- 最终加速效果: 程序由最开始的2.5小时下降到2分钟
- 主要加速路线:
- 变量预分配内存实现加速:2.5小时 to 25分钟;
- numba装饰器实现加速:25分钟 to 2分钟。
一、原始代码(部分)分析
total_entropy = 0
freq_dict = {}
row_mean_q = []
for k in range(row_size):
row_mean[k] = quan_normal(row_mean[k])
row_mean_q.append(quan_quan4(row_mean[k],row_mean))
for j in range(4,matrix.shape[1]):
for i in range(2,matrix.shape[0]):
context_list = (max(matrix[i,j-2],matrix[i,j-1]),row_mean_q[i])
if context_list not in freq_dict.keys():
freq_dict[context_list] = {matrix[i,j]:1}
total_entropy += 8
else:
if matrix[i,j] not in freq_dict[context_list].keys():
freq_dict[context_list].update({matrix[i,j]:1})
total_entropy += 8
else:
total_entropy += -np.log(freq_dict[context_list][matrix[i,j]]/np.sum(list(freq_dict[context_list].values())))
freq_dict[context_list][matrix[i,j]] += 1
说明:
-
利用第三方包line_profiler对程序进行程序运行时间分析,发现
row_mean_q和for循环中最后一个total_entropy的计算花费了主要的程序运行时间;
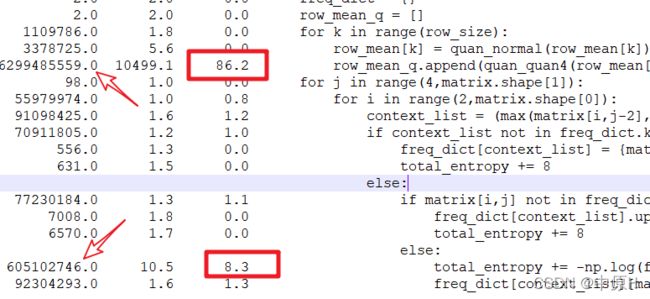
-
考虑应该是
row_mean_q在最开始在定义时是一个空list类型,通过for循环不断地向list中追加数据,并且由于调用的函数quan_quan4()是一个比较简单的分段判断函数计算量很小不会花费太多时间,所以猜测在开辟内存过程中花费了大量的时间,并且通过list.append()方法生成最终的list本身就很不高效。
二、变量预分配内存实现加速
基于上面的猜测,尝试修改变量
row_mean_q的赋值方式,在预定义时直接赋值,然后后面逐项修改,具体地如代码所示:
#row_mean_q = []
row_mean_q = row_mean #row_mean是一个已计算好且与row_mean_q数组长度、每个元素都较为接近的list
for k in range(row_size):
row_mean[k] = quan_normal(row_mean[k])
#row_mean_q.append(quan_quan4(row_mean[k],row_mean))
row_mean_q[k] = quan_quan4(row_mean[k])
说明:
-
这里为了更好地利用预分配的内存,直接令
row_mean_q = row_mean,row_mean是一个在程序前面部分已计算好的,且与row_mean_q数组长度、每个元素都较为接近的list。这样赋值后,在后续进行元素值替换时,内存几乎不发生变化(这里需要验证:python中list元素替换时如何实现的,新分配内存还是在原地址进行扩展?)- 经验证,python中变量每次初始化时会开辟新的内存空间,并将内容地址赋值给变量。
- 数据内部结构改变时(增删改),内存地址不发生变化(可通过
id(a)查看变量a的内存地址),但占用内存空间大小可能发生变化(可通过sys.getsizeof(a)来查看内存大小)。如果对变量重新初始化赋值,就会将新的地址赋值给变量。
-
另一个需要验证的是:如果使用
row_mean_q = [None]*length的形式进行赋值,两者最终的运行时间是否有差别,差别有多大?- 经验证,两种不同的赋值,后者占用的运行时间稍多,但差距不大。一方面,前者直接将
row_mean的内容地址赋值给row_mean_q,后者则需要在内存中开辟新的内存;另一方面,由于None占用内存较小,在后续元素重新赋值过程中需要扩张内存。 - 但需要注意的是,通过
row_mean_q = row_mean两者指向同一个列表内存地址,而当对列表内容进行操作时,列表本身的地址没有发生变化,也就说修改row_mean_q和row_mean中任何一个的元素值,都会导致另一个同样发生变化。
- 经验证,两种不同的赋值,后者占用的运行时间稍多,但差距不大。一方面,前者直接将
三、numba装饰器实现加速
3.1 为什么numba可以对python代码加速?
参考博客:Python程序提速神器–[Numba快速上手指南] (https://blog.csdn.net/june_young_fan/article/details/103671449)
计算机只能执行二进制的机器码,C,C++等编译型语言依靠编译器将源代码转化为可执行文件后运行;Python,Java等解释型语言使用解释器将源码翻译后在虚拟机上执行。对于python,由于解释器的存在,其执行效率比C语言慢几倍甚至几十倍。
Python是一门解释语言,Python为我们提供了基于硬件和操作系统的一个虚拟机,并使用解释器将源代码转化为虚拟机可执行的字节码。字节码在虚拟机上执行,得到结果。
解决python执行效率低问题的解决方案:
- 用C或C++ 重写Python函数。要求对C和C++语言熟悉;
- 用JIT(just in time) 技术。
Numba是一个针对Python的开源JIT编译器,由Anaconda公司主导开发,可以对原生代码进行cpu和gpu加速。
下图是一张由python解释器进行程序运行的过程与JIT编译器运行python程序过程的比较:

具体地,我们使用 python example.py 来执行一份源代码时, Python 解释器会在后台启动一个字节码编译器( Bytecode Compiler ),将源代码转换为字节码。字节码是一种只能运行在虚拟机上的文件, Python 的字节码默认后缀为 .pyc , Python 生成 .pyc 后一般放在内存中继续使用,并不是每次都将 .pyc 文件保存到磁盘上。有时候我们会看到自己 Python 代码文件夹里有很多 .pyc 文件与 .py 文件同名,但也有很多时候看不到 .pyc 文件。pyc 字节码通过 Python 虚拟机与硬件交互,关于.pyc文件的作用和更新机制请移步Python程序的执行过程(解释型语言和编译型语言)。虚拟机的出现导致程序和硬件之间增加了中间层,运行效率大打折扣。相信使用过虚拟机软件的朋友深有体会,在原生的系统上安装一个虚拟机软件,在虚拟机上再运行一个其他系统,经常感觉速度下降,体验变差,这与 Python 虚拟机导致程序运行慢是一个原理。
Just-In-Time(JIT) 技术为解释语言提供了一种优化,它能克服上述效率问题,极大提升代码执行速度,同时保留 Python 语言的易用性。使用 JIT 技术时,JIT 编译器将 Python 源代码编译成机器直接可以执行的机器语言,并可以直接在 CPU 等硬件上运行。这样就跳过了原来的虚拟机,执行速度几乎与用 C 语言编程速度并无二致。
延伸阅读:[How Numba and Cython speed up Python code] (https://rushter.com/blog/numba-cython-python-optimization/)文中提到Cython对python语言加速与numba的区别及适用场景。
3.2 修改代码匹配numba的类型支持
使用numba对程序进行加速的主要问题是:目前Numba只支持python原生函数和部分Numpy函数。
通过实际编写程序,过程中遇到的主要问题:
- 通过jit进行装饰的函数,如果函数中嵌套有其它函数同样需要进行jit装饰;
- numba不支持动态变量,在函数内部使用变量必须预先定义,也可以在函数外部定义,但必须通过形参传输到函数内部,不然会外部变量作为常值的全局变量;
- list的数据类型必须转换为numpy.array类型;
- dict类型变量在使用前必须以numba支持的数据类型格式进行声明,python中一般形式的dict在被jit装饰的函数中无法使用;
- 貌似对tuple的数据类型支持较好,不需要提前声明
基于以上几点对程序进行修改,修改结果如下:
freq_dict = numba.typed.Dict.empty(
key_type = numba.types.UniTuple(numba.types.int32,2),
value_type = numba.types.int32[:],)
row_mean_q = row_mean
for k in range(row_size):
row_mean[k] = quan_normal(row_mean[k])
row_mean_q[k] = quan_quan4(row_mean[k])
row_mean_q = np.array(row_mean_q,dtype=np.int32)
@numba.njit
def caculate_directory(freq_dict,total_entropy,row_mean_q):
for j in range(4,matrix.shape[1]):
for i in range(2,matrix.shape[0]):
context_list = (max(matrix[i,j-2],matrix[i,j-1]),row_mean_q[i])
if context_list not in freq_dict:
freq_dict[context_list] = np.array([matrix[i,j],1],dtype=np.int32)
total_entropy += 8
else:
if matrix[i,j] not in list(freq_dict[context_list])[::2]:
freq_dict[context_list] = np.array(list(freq_dict[context_list])+[matrix[i,j],1],dtype=np.int32)
total_entropy += 8
else:
_= (list(freq_dict[context_list])[::2].index(matrix[i,j]))*2
total_entropy += -np.log(freq_dict[context_list][_+1]/(freq_dict[context_list][1::2]).sum())
freq_dict[context_list][_+1] += 1
return total_entropy
说明:
- 这里代码之所以可以修改为最终上述版本,和程序要解决的问题有很大关系。原代码中freq_dict是字典类型的,具体如{(34,45):{23:2,35:6,23:1},(23,35):{33,1}}也即字典嵌套字典的形式,很可惜,就目前的了解来看,numba似乎不支持这种复杂的数据类型,尝试将其修改为另外一种字典形式{(34,45):[23,2, 35,6, 23,1],(23,35):[33,1]}也即字典套list的形式。原来字典套字典的freq_dice中对于每一个键值对,值同样采用dict的形式,并且值中的键值对由于key的值是相异的,所以我们当按照元素出现顺序将原来的值中dict{key1:value1,key2:value2,…}修改为[key1,value1,key2,value2,…]list的形式,虽然在进行查询时虽然不能继续运用key-value的形式查询,但可以用奇偶位置的元素进行查询,并且由于奇数位的元素是各异的,所以可以利用
list.index('x')返回元素x位于list中的位置,方便后续进一步的元素操作。
四、其它尝试
4.1 多线程的思考
4.2 数据结构的其它尝试
参考文章
[1] Python程序提速神器–Numba快速上手指南
[2] How Numba and Cython speed up Python code