第4章【综合练习题】文件bankpep.csv存放着银行储户的基本信息,数据格式如下表所示,请通过绘图对这些客户数据进行探索性分析。客户年龄分布的直方图和密度图
本书中所有的数据文件保存在data文件夹中,链接如下:
https://pan.baidu.com/s/1Tu__B-YfXDz_yXzbzNKB4A?pwd=sfw2
提取码:sfw2
P86综合练习题
1.文件bankpep.csv存放着银行储户的基本信息,数据格式如下表所示:
| id |
age |
sex |
region |
income |
married |
children |
car |
save_act |
current_act |
mortgage |
pep |
| 编号 |
年龄 |
性别 |
区域 |
收入 |
婚否 |
孩子数 |
有车否 |
存款账户 |
现金账户 |
是否抵押 |
接受新业务 |
请通过绘图对这些客户数据进行探索性分析。
1)客户年龄分布的直方图和密度图,如下图:

import matplotlib.pyplot as plt
import pandas as pd
data = pd.read_csv('data/bankpep.csv')
#1)
data['age'].plot(kind = 'hist',bins = 10,normed = True,title = 'Customer Age')
data['age'].plot(kind = 'kde',style = 'k-')
plt.xlabel('Age')
plt.ylabel('Density')
plt.show()2)客户年龄和收入关系的散点图,如下图:
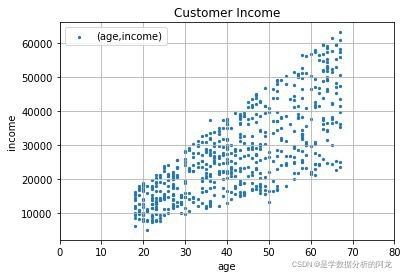
列举以下两种方法:
【方法一】:采用DataFrame.plot(kind = 'scatter',x,y,title,label,grid,xlim,marker,s)绘图。
【方法二】:采用散点图plt.scatter(x,y,marker,s)函数绘图
#2)
#方法一
data[['age','income']].plot(kind = 'Scatter',x = 'age',y = 'income',marker = 's',s = 8,title = 'Customer Income',label = '(age,income)',grid = True,
xlim = [0,80]) #s设置点大小
plt.xlabel('Age')
plt.ylabel('Income')
plt.show()
#方法二:采用scatter函数绘图
plt.figure(figsize = (10,6)) #更改图片大小与背景
plt.scatter(data['age'],data['income'],marker = 's',s = 10) #s设置点大小
plt.grid()
plt.title('Customer Income')
plt.xlabel('Age')
plt.ylabel('Income')
plt.xlim([0,80])
plt.legend(('(age,income)',)) #加“,”使图例显示完整
plt.show()3)绘制散点图观察账户(年龄,收入,孩子数)之间的关系,对角线显示直方图,如下图:

#3)
pd.plotting.scatter_matrix(data[['age','income','children']],c = 'm') #c用来设置颜色:m为红紫色
plt.show()4)按区域展示平均收入的柱状图,并显示标准差,如下图:
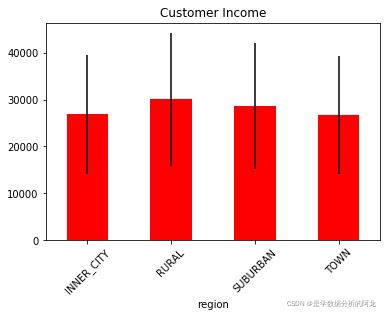
列举以下两种方法:
【方法一】:采用DataFrame.plot(kind = 'bar',yerr = std,rot,title,color)绘制垂直柱状图(yerr = std标y轴的轴向误差线)
【方法二】:采用柱状图plt.bar(x,height,width,yerr = std,color)函数绘图。注:bar函数中的x值、height值、yerr为Series或列表。
#4)
#方法一
import numpy as np
mean = data.groupby(['region']).agg({'income':np.mean})
std = data.groupby(['region']).agg({'income':np.std})
mean.plot(kind = 'bar',yerr = std ,rot = 45,title = 'Customer Income',legend = False,color = 'r')
plt.xlabel('Region')
plt.show()
#方法二:bar函数
import numpy as np
mean = data.groupby(['region']).agg({'income':np.mean})
std = data.groupby(['region']).agg({'income':np.std})
plt.bar(mean.index,mean.income,color = 'r',width = 0.5,yerr = std.income.tolist()) # bar函数中的x值、height值、yerr为Series或列表。
plt.xlabel('Region')
plt.xticks(rotation = 45)
plt.title('Customer Income')
plt.show()5)多子图绘制:账户中性别占比饼图,有车的性别占比饼图,按孩子数的账户占比饼图,如下图:
【方法一】:figure.add_subplot()函数,Series.plot函数绘图。Series类型的可不加ax=ax1,ax2,ax3
【方法二】:figure.add_subplot()函数,plt.pie(x,labels,startangle,autopct')函数绘图
【方法三】与【方法四】均采用plt.subplot()函数绘图。用法同figure.add_subplot()
#5)
#方法一:Series.plot绘图,fig.add_subplot()函数,Series类型的可不加ax=ax1,ax2,ax3
sex_data = data.groupby(['sex'])['sex'].count()
car_data = data[data['car'] =='YES'].groupby(['sex'])['sex'].count()
children_data = data.groupby(['children'])['children'].count()
fig = plt.figure(figsize = (7,6))
fig.add_subplot(2,2,1)
sex_data.plot(kind = 'pie',title ='Customer Sex',startangle = 60,autopct = '%1.1f%%')
fig.add_subplot(2,2,2)
car_data.plot(kind = 'pie',title = 'Customer Car Sex',startangle = 60,autopct = '%1.1f%%')
fig.add_subplot(2,2,3)
children_data.plot(kind = 'pie',title = 'Customer Children',startangle = 60,autopct = '%1.1f%%')
plt.savefig('饼图.jpg',dpi = 400,bbox_inches = 'tight')
plt.show()
#方法二:采用pie函数,fig.add_subplot()函数
sex_data = data.groupby(['sex'])['sex'].count()
car_data = data[data['car'] =='YES'].groupby(['sex'])['sex'].count()
children_data = data.groupby(['children'])['children'].count()
fig = plt.figure(figsize = (7,6))
fig.add_subplot(221) #221可加可不加逗号
plt.pie(x = sex_data,labels = sex_data.index,startangle = 60,autopct = '%1.1f%%')
plt.title('Customer Sex')
plt.ylabel('sex')
fig.add_subplot(222)
plt.pie(x = car_data,labels = sex_data.index,startangle = 60,autopct = '%1.1f%%')
plt.title('Customer Car Sex')
plt.ylabel('sex')
fig.add_subplot(223)
plt.pie(x = children_data,labels = children_data.index,startangle = 60,autopct = '%1.1f%%')
plt.title('Customer Children')
plt.ylabel('Children')
plt.show()6)按客户的性别、收入绘制的箱形图,如下图:
列举以下三种方法:
【方法一】:采用DataFrame.boxplot(by,figsize)画图。(by为用于分组的列名)
【方法二】:采用DataFrame.plot(kind = 'box',title,...)画图。
【方法三】:采用plt.box(x,labels,boxprops,medianprops,whiskerprops...)画图。
#6)
#方法一
data[['income','sex']].boxplot(by = 'sex',figsize = (6,6))
plt.show()
#方法二
import pandas as pd
MALE_data = data[data['sex']=='MALE']['income']
FEMALE_data = data[data['sex']=='FEMALE']['income']
sex_data1 = pd.concat([FEMALE_data,MALE_data],axis = 1) #使用pd.concat函数合并两个series组成DataFrame
sex_data1.plot(kind = 'box',title = 'Boxplot grouped by sex income',grid = True,figsize = (6,6)) #df.plot中可设置画布大小
plt.xticks(range(1,3),['FEMALE','MALE'])
plt.xlabel('[sex]')
plt.show()
#方法三
plt.figure(figsize = (6,6))
MALE_data = data[data['sex']=='MALE']['income']
FEMALE_data = data[data['sex']=='FEMALE']['income']
labels = 'FEMALE','MALE'
#括号可加可不加,或者在下面加plt.boxplot([FEMALE_data,MALE_data],labels =( 'FEMALE','MALE'))
#或者单独加plt.xticks(range(1,3),['FEMALE','MALE'])
plt.boxplot([FEMALE_data,MALE_data],labels = labels,boxprops = {'color':'#1F77B4'},medianprops = {'color':'green'},whiskerprops={'color':'#1F77B4'}) #画多个箱线图要加[]
plt.grid()
plt.title('Boxplot grouped by sex income')
plt.xlabel('[sex]')
plt.show()