OpenAI GPT成全了最强BERT:无监督自然语言模型技术总结
Google提出的BERT(Bidirectional Encoder Representations from Transformers)是现在自然语言处理领域里当之无愧的王者,但是在阅读这篇文献的时候,总有一种和传统自然语言技术断层的感觉。通过研究OpenAI GPT后才恍然大悟,原来这才是其中的桥梁:BERT的思想启发自OpenAI GPT,并应用了transformer的强大处理能力,结合了更多的训练数据、更巧妙的训练手段,才取得了现在这样好的效果。这里就对OpenAI GPT和BERT共同依赖的无监督自然语言模型技术进行全面总结,同时对他们各自的特点进行阐述。
1、无监督自然语言模型背景
对于训练大型的深度学习网络来说,有标注的训练数据是最大的限制瓶颈。因此在NLP领域可以通过学习大量的无监督数据来减少对监督数据的依赖。同时即使监督数据充足,使用更大量级的无监督预训练可以让模型获得更好的特征表示,从而在提升下游fine-tuning任务的效果(例如word embeddings)。但是想要在字粒度学习好的无监督特征表示并不容易,主要是因为
- 无监督优化目标不明确:常见的优化目标包括language modeling、machine translation、discourse coherence,但是没有定论说明哪一种目标会对下游任务的迁移效果最好。往往无监督数据和有监督数据根本不在同一个domain,无监督优化目标需要具有通用性
- 无监督特征表示迁移到后续任务的方法不清楚:下游任务非常多样,包括文本分类、文本相似度、序列标注和问答系统等等,它们的输入和输出差异较大,传统的做法是通过设计多个任务相关的模型结构、使用复杂的学习策略或者增加辅助训练目标等,但是会引入大量下游额外的参数,不利于无监督的优化效果
针对上述问题,OpenAI GPT开创性的提出了统一的模型架构,使用通用的特征表示和最少的模型修改,即可无缝支持无监督预训练和有监督微调:
1)将多样的输入数据结构组合在一起,构成统一的连续token序列输入;
2)预训练和微调的模型统一采用transformer,并在最后一层特征输出之前都保持一致,区别仅在于后面的线性层和优化目标。
BERT也完全采用了上述方法。
2、OpenAI GPT vs BERT
OpenAI GPT最大的特点是在无监督预训练过程中选择了经典的LM(Language Modeling)作为优化目标,也就是说通过最大化由前面一段语句去预测后面一个词的似然概率来实现模型的学习,也就是对一条语料 U = { u 1 , u 2 , ⋯ , u n } \mathcal{U}=\{u_1,u_2,\cdots,u_n\} U={u1,u2,⋯,un}的似然概率用公式表示为
L 1 ( U ) = ∑ i l o g P ( u i ∣ u i − k , ⋯ , u i − 1 ) L_1(\mathcal{U}) = \sum_i logP(u_i|u_{i-k},\cdots,u_{i-1}) L1(U)=i∑logP(ui∣ui−k,⋯,ui−1)
其中 k k k表示上下文窗口大小,由此可见OpenAI GPT只能由左向右的执行训练,也因此是一个单向的预训练模型,这也限制着它的网络架构只能使用transformer的decoder部分。而在有监督微调过程中,一条语料包含token序列 X = { x 1 , x 2 , ⋯ , x m } \mathcal{X}=\{x_1,x_2,\cdots,x_m\} X={x1,x2,⋯,xm}和对应的标签 y y y,将 X \mathcal{X} X输入到相同的预训练网络中得到transformer的特征表示,并将输出层替换为任务相关的输出层来微调整个网络。目标用公式表示为
L 2 ( X , y ) = ∑ x , y l o g P ( y ∣ x 1 , ⋯ , x m ) L_2(\mathcal{X},y) = \sum_{x,y} logP(y|x_1,\cdots,x_m) L2(X,y)=x,y∑logP(y∣x1,⋯,xm)
同时论文表示在微调的 L 2 L_2 L2目标中辅助以 L 1 L_1 L1目标能够增强模型的泛化性并加快收敛,因此最后的目标为
L ( X , y ) = L 2 ( X , y ) + λ L 1 ( X ) L(\mathcal{X},y) = L_2(\mathcal{X},y) + \lambda L_1(\mathcal{X}) L(X,y)=L2(X,y)+λL1(X)
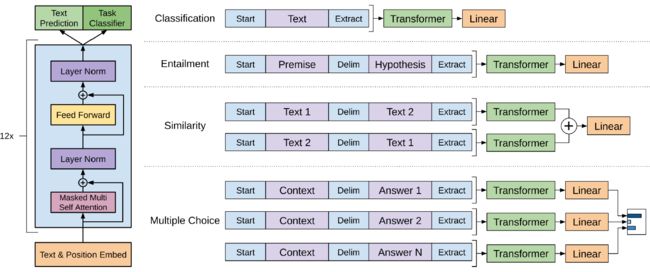
这里还有一个重要的细节,在微调之前需要将多样的输入token序列合并为统一有序的token序列,这其中引入了一些在预训练过程中不存在的分隔token(start、delim、extract),而它们的特征表示只能在微调过程中进行学习。对于多样输入的转化如下图所示,需要注意的是
1)transformer的输出特征表示只取extract对应的即可,因为它已经attend到序列中的每个token表示了;
2)在相似度任务中,由于text1和text2没有先后顺序,因此将二者不同先后顺序的token序列输入同一个transformer,并将特征表示逐元素相加后接入输出层;
3)对于问答系统任务,将多个回答分别与context合并构成多条token序列,再输入同一个transformer和输出层,最后使用softmax归一化得到概率分布。
我们再回头看见BERT的核心工作也就一目了然了,这里总结为以下5个方面:
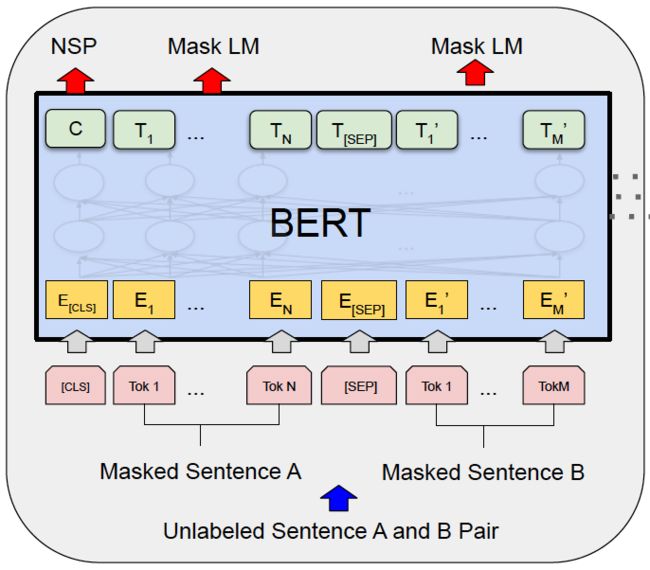
- 双向预训练模型,也就是使用了transformer的encoder部分,模型架构与OpenAI GPT的对比见下图1
- 两个预训练任务为MLM(Masked Language Modeling)和NSP(Next Sentence Prediction)。对于双向模型如果还使用从左向右的language modeling作为目标的话,其预测的下一个token已经提前泄露给了模型,从而几乎不用训练就可以将损失降低为0。因此BERT使用了MLM作为目标,也就是“完形填空”来学习字粒度的上下文表征;为了进一步提升对句粒度的表征学习,又引入了NSP目标。最终的目标是MLM目标与NSP目标相加。详细介绍见下一节
- 统一了预训练和微调两个阶段的输入分隔token的表征学习,即起始[CLS]和中间分隔[SEP]在两个阶段都会学习
- 除了position embeddings还额外添加了segment embeddings,二者都是可学习的,默认最大token序列长度
max_position_embeddings=512,最大segment分段数token_type_vocab_size=16 - 除了GPT使用的BooksCorpus(800M words)作为预训练语料,还使用了更大的Wikipedia(2,500M words)
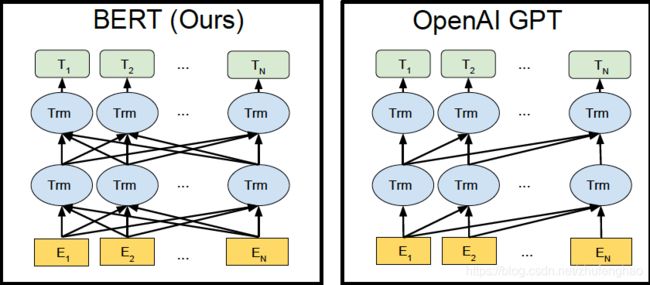 图1 模型架构对比 图1 模型架构对比
|
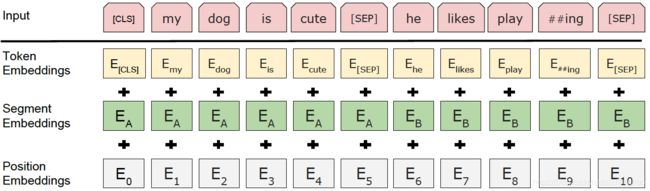 图2 输入额外的segment embeddings 图2 输入额外的segment embeddings
|
3、深入分析BERT
不深入了解BERT的预训练则不知道它的强大。BERT的预训练需要MLM和NSP结合,这里分别对二者进行介绍。
预训练目标一:MLM(Masked Language Modeling)
传统的LM(Language Modeling)只适合例如RNN/LSTM这样单向的模型架构,而transformer天然就是一种双向架构,像OpenAI GPT这样强制transformer学习单向信息的模型,势必会影响模型最终的效果。BERT最大的贡献便是用MLM代替了LM从而使得预训练双向transformer成为了可能。
具体来说,BERT将输入token序列中的15%随机替换为[mask]token,利用这些[mask]在最后输出的特征表示,来预测其原本是哪些词来训练网络,图示如下。但是这样做会在预训练中引入[mask]而微调和最终推理过程中却不会出现,造成了上下游不一致的情况。同时,MLM训练出来的网络只会利用“上下文”来得到当前token的特征表示,即便在微调和推理过程中当前token是知道的,但当前token也不会对其自身的特征表示有任何贡献,这又是另一种上下游不一致。
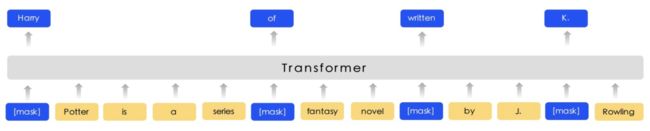
综上所述,为了消除上述两种上下游不一致情况,BERT在实现过程中又使用了一种trick,在选中的15%的被加上mask的token中,采取如下处理:
- 80%的概率确实替换成[MASK],比如my dog is hairy → my dog is [MASK],因此真实替换成[MASK]的token数量只有12%
- 10%的概率替换成它本身,比如my dog is hairy → my dog is hairy(目的是让当前token也参与其语义表示的计算)
- 10%的概率替换成随机的一个词,比如my dog is hairy → my dog is apple(目的是如果当前词非mask,模型也不能完全相信当前词的语义,因为当前词可能是错误的,而是强制让模型通过上下文来学习其真实语义)
最后这15%的token依然全部被预测来完成模型的学习。不难看出来上述的2、3步骤是相互制衡的关系,因而二者的比例保持相等,既让当前token有所贡献,又通过设置了一些噪声来抑制它贡献太多。MLM仅在一个batch中预测15%的token,而传统的LM会预测全部token,这就导致了MLM需要更多的训练步数(1,000,000步),但这种巧妙的方法经过实验后超越了LM达到了最佳效果。
假设一条语料中被mask的token下标集合为 M \mathcal{M} M,transformer最后一层第 i i i个token的特征表示为 h i ∈ R d h_i\in \mathbb{R}^d hi∈Rd,其对应的真实词表onehot向量为 y i ∈ R l y_i\in \mathbb{R}^l yi∈Rl,输出线性层的权重为 W m ∈ R d × l W_m\in \mathbb{R}^{d\times l} Wm∈Rd×l, l l l为词表大小。那么MLM的交叉熵损失用公式表示为
L M L M = ∑ i ∈ M y i log ( s o f t m a x ( h i W m ) ) L_{MLM}=\sum_{i\in\mathcal{M}}y_i\log(softmax(h_iW_m)) LMLM=i∈M∑yilog(softmax(hiWm))
预训练目标二:NSP(Next Sentence Prediction)
MLM的训练是在字粒度上的,而为了更好的适用于问答系统和语言推理等需要预测句粒度的关系,BERT添加了NSP目标,从而和MLM构成了多任务学习(Multi-Task Learing)。具体来说,NSP就是一个简单的二分类任务,其训练语料可以通过任何语料集通过下述处理获取:
- 语句A以50%的概率抽取真实的下一句作为语句B
- 语句A以50%的概率随机抽取语料集的某句作为语句B
需要注意的是这里的”语句“不一定是自然的语句,而是有可能包含多个自然语句的token序列。将抽取的语句以[CLS,A,SEP,B,SEP]的token序列输入模型中,最终取[CLS]的特征表示连接输出层。假设一条语料在transformer最后一层中[CLS]token的特征表示为 h C ∈ R d h_C\in \mathbb{R}^d hC∈Rd,label向量为 y ∈ R 2 y\in \mathbb{R}^2 y∈R2,输出线性层的权重为 W n ∈ R d × 2 W_n\in \mathbb{R}^{d\times 2} Wn∈Rd×2。那么NSP的交叉熵损失用公式表示为
L N S P = ∑ y log ( s o f t m a x ( h C W n ) ) L_{NSP}=\sum y\log(softmax(h_CW_n)) LNSP=∑ylog(softmax(hCWn))
后续研究对NSP实际效果还有深入研究,我们下一节再展开。最终BERT的预训练过程可以参考下图:输入格式[CLS,A,SEP,B,SEP],其中A和B按上述方式随机mask,特殊[CLS]和[SEP]token不参与mask。最终损失函数表示为 L = L M L M + L N S P L=L_{MLM}+L_{NSP} L=LMLM+LNSP
微调阶段
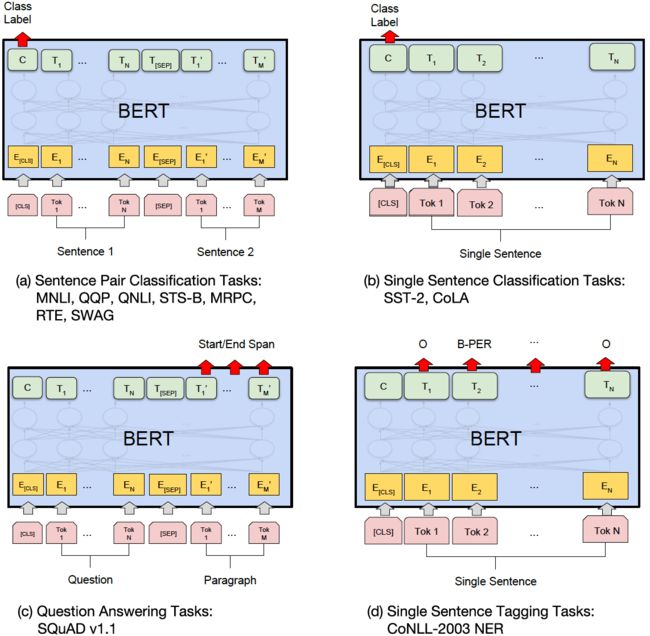
BERT和OpenAI GPT一样,都可以对多样的输入进行简单的合并,就可以完成端到端的微调了。关于多种目标任务的处理方式如下:
- 文本pair分类任务(a):输入格式[CLS,A,SEP,B,SEP],两个序列的token对应不同的segment(id=0/1),最后取最后一层的[CLS]特征表示接上线性层+softmax进行分类
- 单文本分类任务(b):输入格式[CLS,A,SEP],序列的token对应的segment全部一致(id=0),最后取最后一层的[CLS]特征表示接上线性层+softmax进行分类
- 问答任务(c):输入格式[CLS,A,SEP,B,SEP],其中A为question,B为passage,两个序列的token对应不同的segment(id=0/1),将这个问题理解为在passage中寻找answer的开始位置和结束位置的问题:引入起始向量 S ∈ R H S\in \mathbb{R}^H S∈RH和终止向量 E ∈ R H E\in \mathbb{R}^H E∈RH。在训练时,一个token是answer起始位置的概率是token的特征表示与 S S S的点积后通过softmax归一化,即 P i = e x p ( S ⋅ T i ) ∑ j e x p ( S ⋅ T j ) P_i=\frac{exp(S\cdot T_i)}{\sum_j exp(S\cdot T_j)} Pi=∑jexp(S⋅Tj)exp(S⋅Ti),同理可得结束位置概率 Q i Q_i Qi,而真实起始和终止位置的onehot向量分别为 P ^ \hat{P} P^和 Q ^ \hat{Q} Q^,损失函数 L = − 1 2 ( 1 N ∑ i N P ^ log ( P ) + 1 N ∑ i N Q ^ log ( Q ) ) L=-\frac{1}{2}\left(\frac{1}{N}\sum_i^N\hat{P}\log(P)+\frac{1}{N}\sum_i^N\hat{Q}\log(Q)\right) L=−21(N1∑iNP^log(P)+N1∑iNQ^log(Q));在预测时,取 max i ≤ j S ⋅ T i + E ⋅ T j \max_{i\le j} S\cdot T_i + E\cdot T_j maxi≤jS⋅Ti+E⋅Tj的 i , j i,j i,j之间的span作为answer
- 单文本序列标注任务(d):输入格式[CLS,A,SEP],序列的token对应的segment全部一致(id=0),最后取最后一层的所有token特征表示接上共享的线性层+softmax进行标注分类
4、BERT后续改进
深度学习本就是半理论半实践的科学,经过大量的实验还是能发现BERT的一些问题的,这里总结为如下几个方面
1)预训练优化
RoBERTa: A Robustly Optimized BERT Pretraining Approach
这篇论文发现BERT预训练里有一些方案选择和细节处理的不太好,导致模型没有被充分的训练,而当充分训练后,RoBERTa可以达到比BERT更优异的效果,甚至超过了BERT的后续改进版本,具体有
- MLM任务中使用动态mask:BERT采用的mask是在预处理阶段就处理好的,在训练的40个epoch中不变,因此称为静态mask。RoBERTa首先尝试改进静态mask,将每条语料以10种不同的mask方式进行处理,因此每条语料的1种mask方式会在整个训练中出现4次,这样增加了mask的多样性;同时RoBERTa还直接使用了动态mask,即每条语料每次输入时mask方式随机生成。最终动态mask方式略有优势被采纳,这也是RoBERTa在更大训练集和更多训练步中取得优势的关键
- 预训练中去掉了NSP任务:BERT在预训练中证明添加NSP任务后效果较好,但是这篇论文作者认为这可能是BERT在实验中仅仅去除了NSP的loss,而依然保持了语句pair的输入格式,这会影响模型训练。同时BERT为了加快训练,在90%的训练步里序列长度只有128,而在剩余的10%里才使用了512长度的序列,而其目的主要为了学习positional embeddings。RoBERTa则证明了使用长度达到512的连续的段落语句直接作为输入,并去除NSP任务效果最好。
- 使用更大的batch:BERT的BASE模型使用batch size为256,并训练了1M steps;而RoBERTa使用batch size为2K,并训练了125K steps效果最佳
- 使用了更大的BPE词汇表:BPE(Byte-Pair Encoding)是Sennrich在2016年提出的文本编码方法,BPE将字词统一成子词单元(subword units),通过在训练语料上的统计分析抽取得到。Radford在GPT2里提出了一种更巧妙的BPE实现版本,该方法使用bytes(字节)作为基础的子词单元,它可以在不需要引入任何未知字符前提下对任意文本进行编码。BERT使用了一个大小为30K的字级(character-level)的BPE词汇表,RoBERTa则使用了50K的BPE词汇表
- 增加新的预训练数据集CC-NEWS,语料从16G增加到160G大小的无压缩文本;修改了超参数,将adam的 β 2 \beta_2 β2参数从0.999改为0.98以增强在更大batch size下的稳定性
2)模型压缩
ALBERT: A Lite BERT for Self-Supervised Learning of Language Representations
越大的模型在语言模型中效果越好,即便BERT-base已经有110M参数,而BERT-large达到了340M参数,但仍然没有看到有饱和的迹象,唯一的限制就是GPU/TPU的内存限制和训练时长。那么能不能控制模型的规模而达到BERT一样好的性能?ALBERT就是一种很好的选择,它通过embedding矩阵分解和跨层参数共享,在略微牺牲效果的前提下,极大程度的减少了模型规模;重新探讨了NSP的不足,并提出使用SOP(sentence-order prediction)任务来进一步提升效果并超越了BERT。
和BERT一样,ALBERT同样使用了transformer的encoder部分,并使用了GELU激活,设置隐层维度为 H H H,那么feed-forward的中间层维度也为 4 H 4H 4H,attention的head数量为 H / 64 H/64 H/64,这里仅额外多了一个词表的embedding大小 E E E。ALBERT的3点主要贡献如下
- embedding矩阵分解:在BERT以及RoBERTa等后续改进中,总是有 E ≡ H E≡H E≡H,这在模型角度和实际应用中都不是最优的。在模型角度,词表的embedding学习的是上下文独立的表征,而隐层的embedding学习的是上下文依赖的表征,而这上下文表征能力正是BERT这类模型的强大之处。因此解耦 E E E和 H H H这两个embedding参数,尤其是让 E ≪ H E\ll H E≪H会让模型更高效;从实际应用角度,一般词表大小 V V V特别庞大,如果 E ≡ H E≡H E≡H,那么 H H H的微小增长就会让词表embedding矩阵参数大小 V × E V\times E V×E急剧增长,而这些参数的更新是非常稀疏的,因此是冗余的。通过使用两个小矩阵参与映射(即 E ≪ H E\ll H E≪H)就可以将原始词表embedding矩阵 V × H V\times H V×H的参数量减少到 V × E + E × H V\times E+E\times H V×E+E×H,从而减少整体模型的参数量。通过实验表明 E = 128 E=128 E=128可以达到最优效果。
- 跨层参数共享:通过观察发现,BERT的不同层虽然有不同的参数,但是它们之间非常相似,导致一些层的输入和输出距离分布相近,由此推断这些层可能存在冗余。ALBERT则让每层的所有参数都共享,意思是将BERT的 f n ( ⋯ f 2 ( f 1 ( x ) ) ) f_n(\cdots f_2(f_1(x))) fn(⋯f2(f1(x)))结构变成 f ( ⋯ f ( f ( x ) ) ) f(\cdots f(f(x))) f(⋯f(f(x))),原本有 L L L层的transformer结构,实际上参数量只相当于1层,极大的减少了参数量到原来的 1 / L 1/L 1/L,见图1。从最终的效果来看,这种参数共享起到了正则化的作用,增强了模型的泛化能力。ALBERT的Lite也就体现在这里:参数量减少使得保存下来的模型权重体积很小,同时也使得模型训练所需的时间和内存也会相应变小。但是需要注意,参数量减少到原来的 1 / L 1/L 1/L并不意味着训练/预测速度能提升 L L L倍,因为ALBERT仍然是一个多层结构,共享层参数需要更新 L L L次,因此总参数量大幅减少的ALBERT和BERT相比,base配置下仅加速了1.2倍,large配置下加速了1.7倍;预测速度则与BERT持平。同时可以看到,同配置下的ALBERT由于参数量急剧减少,效果也会明显差于BERT。不过ALBERT使训练xxlarge配置下的模型成为可能,也由此超越了BERT-large的效果。
- 新的语句连贯性任务SOP(sentence-order prediction):BERT使用的NSP任务存在问题,它混合了语句的主题预测和连贯性预测,而主题预测相对来说比较简单,且和MLM任务重合度高,因此对模型预训练效果没有明显提升。ALBERT提出使用更难的语序预测SOP,正例和NSP一样取连续的语句序列A和B,负例则颠倒语句顺序为B和A,这样既可直接学习连贯性而避免过多学习主题。
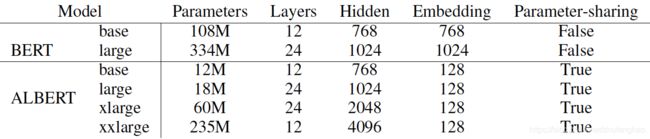 图1 参数量对比 图1 参数量对比
|
 图2 模型效果与速度对比 图2 模型效果与速度对比
|
除了上述贡献外,ALBERT的训练过程还包括了很多后BERT模型的很多trick:
1)输入序列90%长度为512,10%小于512,这是根据RoBERTa的实验,越长的输入序列上下文信息越完整,模型学习效果越好
2)词表大小和BERT同为30K
3)在MLM任务中使用n-gram masking,即添加mask的方式不再互相独立了,而是选取n-gram后一起添加mask,语义信息更完整
4)优化器使用 L A M B L_{AMB} LAMB
5)batch size为4096,训练125000步。
另外,模型使用更大的训练集还会有提升;由于ALBERT共享权重具有天然的正则化效果,在大型数据集上仍然未过拟合,去掉transformer中的dropout效果会略微提升。通过实验还发现,增加ALBERT的嵌套层数并不能一直提升效果,例如ALBERT-large到达24层效果最好,而ALBERT-xxlarge到达12层效果最好。