风格迁移 I2I 论文阅读笔记——AnimeGAN,动漫风格生成
AnimeGAN: A Novel Lightweight GAN for Photo Animation
github代码:https://github.com/TachibanaYoshino/AnimeGAN
介绍
动画制作需要考虑线条、纹理、颜色和阴影,十分耗时。因此,能够自动转化real-world photos to high-quality animation style image的技术是很有价值的。
现有的技术存在以下问题:
1)生成图像没有显著的动画风格的纹理
2)生成图像丢失了原有图像的内容
3)参数模型太大
我们提出的轻量模型AnimeGAN的主要特点:
1)使用Gram矩阵来获取更加鲜明的风格图片
2)基于非监督学习
3)提出了三个提高动画视觉效果的loss:grayscale style loss,color reconstruction loss,grayscale adversarial loss。前两个在生成过程中保留照片的颜色并使生成图片的动画风格更加明显,最后一个在discriminator里使生成图片具有更加鲜明的颜色。同时,我们也使用了CartoonGAN提出的edge-promoting adversarial loss来保留清晰的边缘。
4)我们使用在预训练的VGG19来作为感知网络,以获得生成图片和原始图片的深层感知特征的L1损失,从而使两张图片的内容匹配。
5)在AnimeGAN开始训练前,我们先对generator进行了初始训练,保障AnimeGAN的训练更加稳定。
相关工作
Neural Style Transfer(NST):Gatys提出使用Gram矩阵匹配内容图像和风格图像中提取的深层特征来合成。AdaIN将内容图像特征与风格图像特征的均值和方差对齐,没有使用复杂的Gram矩阵。Universal Style Transfer (UST),使用Whitening and Coloring transform (WCT)来直接衡量内容图片对风格图像特征的协方差。
Image-to-Image Translations with GAN:pix2pix使用conditional GAN和U-Net结构。
CartoonGAN在照片动画化上效果很好,Comixify: transform video into a comics.这篇论文将一个视频转化为连环漫画:他们提出了从视频中提取那些可以完整描述视频内容的关键帧的算法。
模型
AnimeGAN由两个卷积神经网络构成:一个是generator G,将照片转化为动画图片;一个是discriminator D,判断输入的图片是real或者fake。

generator方框上的数字代表channel数,SUM表示element-wise sum,K代表卷积核大小, C是feature map数,S是stride,Inst_Norm表示instance normalization。
generator可以被视为一个对称的encoder-decoder网络,它由标准卷积,depthwise separable convolution深度可分离卷积,inverted residual block,上采样和下采样模块组成。最后一个1x1卷积使用tanh非线性激活函数而不是归一化层。
以下是各个block的详细结构。

⊕代表element-wise的加法。
在discriminator里,为了保证每个卷积层的权重,我们使用了spectral normalization谱归一化。
Loss
目标:建立从photo domain P到animation domain A的映射。
训练数据是不匹配的样本Sdata§ = {pi | i=1,…, N} ,Sdata(a) = {ai | i=1,…, N}。N和M分别是照片和动画训练集中的样本数量。
我们使用grayscale Gram矩阵来使得生成图片拥有和动画片相似的纹理(而不是颜色)。因此,我们需要将动画图片ai转化为灰度图xi来消除颜色干扰。
像CartoonGAN一样,我们移除了动画图片ai中的edge得到新的图片ei,在将其转化为灰度图y。
为了生成高质量的图片,并且稳定训练,我们采用了LSGAN的最小二乘损失函数(least squares loss)作为对抗损失Ladv(G, D)。
![]()
Ladv(G, D)影响generator中的转化过程,Lcon(G, D)是content loss,它帮助保留输入图片的内容。Lgra(G, D)代表灰度风格损失(grayscale style loss),使得生成图片具有明显的动画风格的纹理和线条,Lcol(G, D)是color reconstruction损失,帮助生成图片与
输入图片颜色相似。
在我们的实验中,ωadv=300,ωcon=1.5,ωgra=3,ωcol=10。
对于generator:

Lcon(G, D)和Lgra(G, D),使用预训练的VGG19作为感知网络来提取高质量的图片的语义特征。VGGl()代表VGG的第l层的特征图,在我们的实验中,第l层为’conv4-4’。Gram()代表特征的Gram矩阵。计算时使用了l1 sparse regularization。
为了重塑图片颜色的效果能够更好,我们将图片从RGB格式转为YUV格式。在Y channel使用了L1损失,U 和V channel使用了Huber损失。

因此,generator的损失函数定义如下:

对于discriminator:
新增了一个edge-promoting adversarial loss保证AnimeGAN再生成的图片具有清晰的边缘,和一个grayscale对抗损失保证生成图片不会变成灰度图。
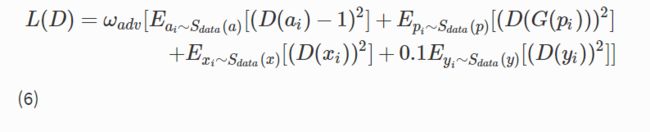
Eyi是edge-promoting对抗损失,Exi是grayscale对抗损失。将edge-promoting损失缩小0.1倍防止生成的边缘过于清晰。
训练
为了防止局部最优,generator首先只使用content loss进行预训练1个epoch,learning rate=0.0001。
之后,对于generator的learning rate为0.0008,discriminator的learning rate为0.00016。训练epoch=100,batch size=4。使用Adam optimizer优化。
实验
数据集
所有训练图片的分辨率为256x256。
从CycleGAN的数据集中使用了6656张照片作为content image。
style image:‘起风了’电影里的1792张动画图片——Miyazaki Hayao风格,‘你的名字’1650张动画图片——Makoto Shinkai风格,‘Paprika’1553张动画图片——Kon Satoshi风格。
实验结果
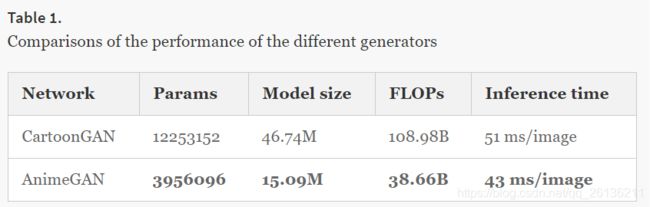
与CartoonGAN和ComixGAN进行了比较。