Python去除csv文件停用词、标点符号、单个数字等
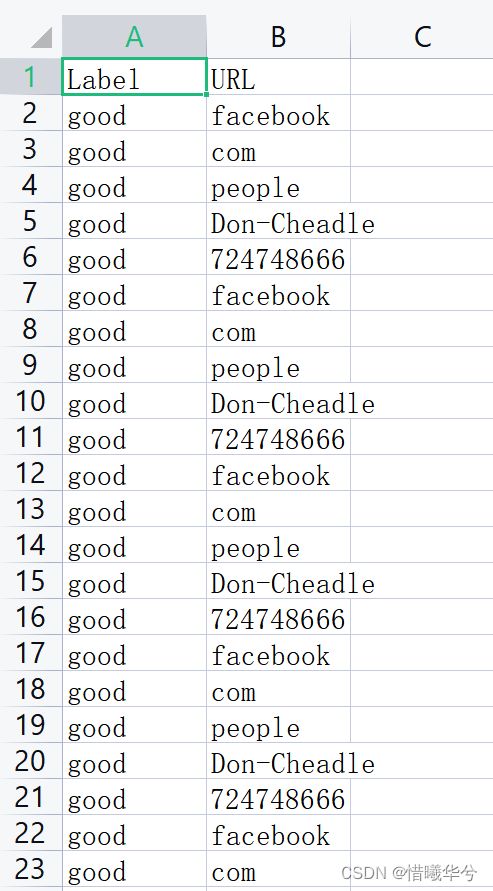
原始数据
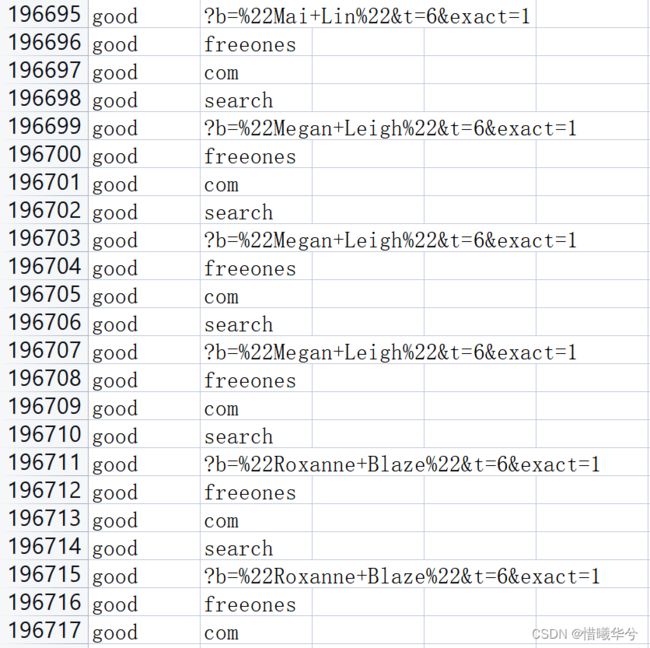

目标
删除第二列中含有com、net、org等词语、数字,含有标点符号的行。
由于csv文件过大(188万行),甚至超出了WPS和Excel的显示范围(也因此知道了WPS和Excel的显示范围是104万行哈哈哈),考虑用python对文件处理。
解决步骤
1、创建停用词表
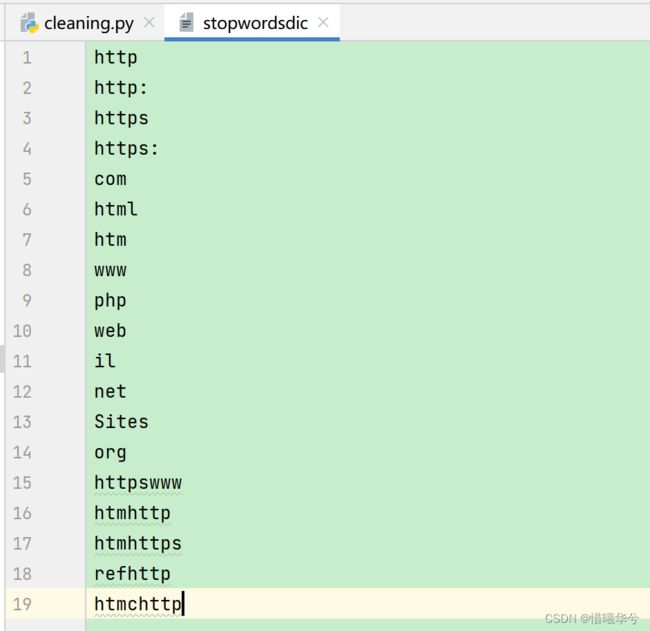
这个是自己写的,因为在我的任务中停用词比较特殊,和一般说的中英文停用词不同。
编译器是PyCharm。
在项目文件里创建名为stopwords的文件夹,在文件夹下创建一个stopwordsdic的文件(文件类型就是文件),在这个文件里面写自己的停用词。
2、数据处理
# 用于记录运行时间
import time
import re
import pandas as pd
# 加载停用词表,目录就是停用词表所在的目录
stopwords = [line.strip() for line in open('./stopwords/stopwordsdic', encoding='UTF-8')]
# 定义一个函数,使用正则表达式对字符串清洗
def textParse(str_doc):
# 目的是将文本中特殊符号、标点等过滤
r1 = '[’!"#$%&\'()*+,-./::;;|<=>?@,—。?★、…【】《》?“”‘’![\\]^_`{|}~]+'
str_doc = re.sub(r1, '', str_doc)
return str_doc
start = time.time()
# 读取文件中所有数据
data = pd.read_csv("./kaggle/input/phishing-site-urls/phishing_site_urls_01.csv", encoding='latin-1')
# 单独对URL这一列处理
data_url = data['URL']
for i in range(len(data_url)):
# 正则表达式对字符串清洗
data_url[i] = textParse(data_url[i])
# 去除数字
if data_url[i].isdigit():
data_url[i] = data_url[i].replace(data_url[i], '')
# 去除单个字符
if len(data_url[i]) == 1:
data_url[i] = data_url[i].replace(data_url[i], '')
# 去除字母+数字的组合,例如 c3 s9 这些
if len(data_url[i]) == 2:
if data_url[i].isalnum():
data_url[i] = data_url[i].replace(data_url[i], '')
else:
data_url[i] = data_url[i]
# 去除停用词
if data_url[i] in stopwords:
data_url[i] = data_url[i].replace(data_url[i], '')
else:
data_url[i] = data_url[i]
# 打印一下,看看处理到第几行了
# print(i)
# 重命名
data_url = data_url.rename('URL')
# 用处理好后的替换掉原来的URL列,和原始数据合并
data = data.drop(['URL'], axis=1).join(data_url)
# 写入csv文件
data.to_csv(r'./kaggle/input/phishing-site-urls/phishing_site_urls_02.csv', sep=",", index=False)
data = pd.read_csv("./kaggle/input/phishing-site-urls/phishing_site_urls_02.csv", encoding='latin-1')
# 去除其中空值的数据
data.dropna(how='any', inplace=True, axis=0, subset=['URL'])
data.to_csv(r'./kaggle/input/phishing-site-urls/phishing_site_urls.csv_02', sep=",", index=False)
end = time.time()
runTime = end - start
print("running time:", runTime)因为超出WPS和Excel的显示范围,我也不知道到底有多少行,第一次运行的时候跑了好久还没出结果。后来在运行过程中打印了行数, 原来它有188多万行,哈哈哈,跑了几个小时。