【NLP】14 ERNIE应用在语义匹配NLP任务——Paddlehub安装、BERT推广的使用、与Simnet_bow与Word2Vec效果比较
Ernie语义匹配
- 1. ERNIE 基于paddlehub的语义匹配0-1预测
-
- 1.1 数据
- 1.2 paddlehub
- 1.3 三种BERT模型结果
- 2. 中文STS(semantic text similarity)语料处理
- 3. ERNIE 预训练+微调
-
- 3.1 过程与结果
- 3.2 全部代码
- 4. Simnet_bow与Word2Vec 效果
-
- 4.1 ERNIE 和 simnet_bow 简单服务器调用
- 4.2 Word2Vec 求和取平均
- 4.3 全部代码
- 5. STS-B 数据集
- 6. 其它
- 小结
1. ERNIE 基于paddlehub的语义匹配0-1预测
可参考此官方教程:PaddleHub实战——使用ERNIE优化医疗场景文本语义匹配任务,利用paddlehub进行模型搭建,并且这样可以轻松的选择不同的模型
1.1 数据
利用天池“公益AI之星”挑战赛-新冠疫情相似句对判定大赛提供的数据集,这是COVID9疫情相关的呼吸领域的真实数据积累,数据粒度更加细化,判定难度相比多科室文本相似度匹配更高,同时问答数据也更具时效性
数据集给出了文本对(text_a、text_b,text_a为query,text_b为title)以及类别(label)。其中label为1,表示text_a、text_b的文本语义相似,否则表示不相似
pointwise,每一个样本通常由两个文本组成(query,title)。类别形式为0或1,0表示query与title不匹配; 1表示匹配
1.2 paddlehub
输入以下代码安装paddlehub 1.8 及以上版本,注意:不能安装最新即2.0版本!
pip install paddlehub==1.8.1 -i https://pypi.tuna.tsinghua.edu.cn/simple
其中最大序列长度max_seq_len是可以调整的参数,建议值128,根据任务文本长度不同可以调整该值,但不要超过512。
num_slots: 文本匹配任务输入文本的数据量。pointwise文本匹配任务num_slots应为2,表示query和title
关于numpy求最大值:
import numpy as np
x = [[0.08017547, 0.9198245 ],
[0.21695773, 0.78304225],
[0.9055544 , 0.0944456 ]]
print(np.argmax(x))
> 1
print(np.argmax(x[0]))
> 1
print(np.argmax(x, axis=1))
> [1 1 0]
print(np.argmax(x, axis=0))
> [2 0]
这里修改了BaseTask的self._compatible_mode,以便模型能够返回置信度,三句话如下:
[["小孩吃了百令胶囊能打预防针吗", "小孩吃了百令胶囊能不能打预防针"],
["请问呕血与咯血有什么区别?", "请问呕血与咯血异同?" ],
['新冠疫情相似句对判定大赛', '疫情相关的呼吸领域的真实数据']]
1.3 三种BERT模型结果
ERNIE三句话判断的标签与置信度如下:
[2021-04-03 11:59:32,171] [ INFO] - PaddleHub model checkpoint loaded. current_epoch=4, global_step=204, best_score=0.90833
...
['1', '1', '1']
[0.08017547 0.21695773 0.0944456 ]
[0.9198245 0.78304225 0.9055544 ]
将模型换成BERT base Chinese,结果如下:
[2021-04-03 11:56:23,166] [ EVAL] - [dev dataset evaluation result] loss=0.25818 acc=0.89466 f1=0.87201 precision=0.85167 recall=0.89335 [step/sec: 11.73]
...
['1', '1', '1']
[0.06025315 0.4611525 0.4954325 ]
[0.93974686 0.5388475 0.50456756]
再将模型换成chinese-bert-wwm,这是哈工大讯飞联合实验室(HFL)发布的模型,官方链接,wwm意思是全词遮罩(Whole Word Masking)
问题:服务器上下载很慢,可以在Windows上用paddlehub 2.0下载好后发送到服务器上,注意,Windos上不能是paddlehub 1.8 版本,否则会报错,也不行
再将模型换成chinese-electra-base,谷歌与斯坦福大学共同研发的最新预训练模型ELECTRA因其小巧的模型体积以及良好的模型性能受到了广泛关注。为了进一步促进中文预训练模型技术的研究与发展,哈工大讯飞联合实验室基纡官方ELECTRA训练代码以及大规模的中文数据训练出中文ELECTRA预训练模型供大家下载使用。其中ELECTRA-small模型可与BERT-base甚至其他同等规模的模型相媲美,参数数量仅为BERT-base的1/10,谷歌&斯坦福大学官方的ELECTRA,中文ELECTRA可见此
再将模型换成chinese-roberta-wwm-ext,主要是在BERT基础上做了几点调整,其它可见:
- 动态Masking,相比于静态,动态Masking是每次输入到序列的Masking都不一样
- 移除next predict loss,相比于BERT,采用了连续的full-sentences和doc-sentences作为输入(长度最多为512)
- 更大batch size,batch size更大,training step减少,实验效果相当或者更好些
- text encoding,基于bytes的编码可以有效防止unknown问题。另外,预训练数据集从16G增加到了160G,训练轮数比BERT有所增加
[2021-04-03 18:16:58,015] [ EVAL] - [dev dataset evaluation result] loss=0.22186 acc=0.90978 f1=0.89119 precision=0.86439 recall=0.91970 [step/sec: 11.72]
...
['1', '1', '1']
[0.02443924 0.22384807 0.24285851]
[0.9755608 0.7761519 0.7571415]
2. 中文STS(semantic text similarity)语料处理
数据来自 ChineseSTS、CCKS2018、XNLI、Chinese SNLI MultiNLI,未使用:LCQMC、OCNLI
数据处理代码如下:
# path_CCKS2018 = '... your path/中文STS/CCKS2018/task3_train.txt'
# path_output = '... your path/中文STS/CCKS2018/train.txt'
# with open(path_CCKS2018, 'r', encoding='utf-8') as file:
# for line in file.readlines():
# print(line.strip().split('\t'))
# path_ChineseSTS_master = '... your path/中文STS/ChineseSTS-master/simtrain_to05sts_same.txt'
# path_ChineseSTS_master2 = '... your path/中文STS/ChineseSTS-master/train2.txt'
# list = []
# f = open(path_ChineseSTS_master2, 'w', encoding='utf-8')
# with open(path_ChineseSTS_master, 'r', encoding='utf-8') as file:
# for line in file.readlines():
# # print(line.strip().split('\t'))
# tmp = line.strip().split('\t')
# if eval(tmp[4]) >= 3:tmp[4]=1
# elif eval(tmp[4]) < 3:tmp[4]=0
# f.write(tmp[1] + '\t' +tmp[3] + '\t' + str(tmp[4]) + '\n')
# path = '... your path/中文STS/Chinese SNLI MultiNli/train.txt'
# output = '... your path/中文STS/Chinese SNLI MultiNli/processing.txt'
# f = open(output, 'w', encoding='utf-8')
# with open(path, 'r',encoding='utf-8') as file:
# for line in file.readlines():
# tmp = line.strip().split('\t')
# try:
# if tmp[2] == 'neutral':continue
# elif tmp[2] == 'contradiction':
# tmp[2] = '0'
# elif tmp[2] == 'entailment':
# tmp[2] = '1'
# f.write(tmp[0] + '\t' + tmp[1] + '\t' + tmp[2] + '\n')
# except:
# print(tmp)
# path = '... your path/中文STS/XNLI/XNLI-1.0/xnli.test.tsv'
# path_out = '... your path/中文STS/XNLI/XNLI-1.0/train2.txt'
# f = open(path_out, 'w', encoding='utf-8')
# with open(path, 'r', encoding='utf-8') as file:
# for line in file.readlines():
# tmp = line.strip().split('\t')
# if tmp[0] != 'zh':continue
# if tmp[1] == 'neutral':continue
# if tmp[1] == 'entailment':
# tmp[1] = '1'
# elif tmp[1] == 'contradiction':
# tmp[1] = '0'
# f.write(tmp[6] + '\t' + tmp[7] + '\t' + tmp[1] + '\n')
由以上代码,将CCKS2018、Chinese SNLI MultiNli、ChineseSTS-master、XNLI四个数据集进行格式处理与合并,得到以下格式的数据集,用’\t’进行分隔:
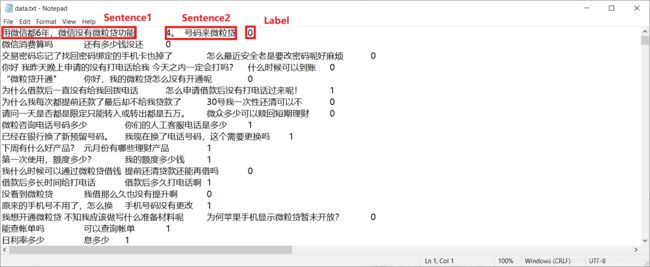
总句子对数量:412101,文件大小:44.2MB
随机打乱数据,95%的数据作为训练集,5%的数据作为测试集:
path = '... your path/Chinese STS/data.txt'
path_train = '... your path/Chinese STS/train.txt'
path_dev = '... your path/Chinese STS/dev.txt'
f1 = open(path_train, 'w', encoding='utf-8')
f2 = open(path_dev, 'w', encoding='utf-8')
import random
list = []
with open(path, 'r', encoding='utf-8') as file:
for line in file.readlines():
list.append(line)
print(len(list))
L = random.sample(range(0, len(list)), len(list))
for i in range(len(list)):
if random.randint(1, 100) > 5: # 训练集
f1.write(list[L[i]])
else: # 测试集
f2.write(list[L[i]])
训练集句子长度:391374,测试集句子长度:20727
3. ERNIE 预训练+微调
3.1 过程与结果
训练的超参数设为迭代一次,训练过程如下:
[2021-04-03 19:09:58,762] [ TRAIN] - step 300 / 3057: loss=0.43742 acc=0.79688
[2021-04-03 19:10:31,878] [ EVAL] - [dev dataset evaluation result] loss=0.42460 acc=0.80115
[2021-04-03 19:15:25,458] [ TRAIN] - step 600 / 3057: loss=0.35716 acc=0.84219 f1=0.84650 precision=0.83634 recall=0.85692 [step/sec: 1.05]
[2021-04-03 19:15:52,798] [ EVAL] - [dev dataset evaluation result] loss=0.33696 acc=0.85229 f1=0.85776 precision=0.84240 recall=0.87368 [step/sec: 5.92]
[2021-04-03 19:20:47,694] [ TRAIN] - step 900 / 3057: loss=0.31624 acc=0.85938 f1=0.86547 precision=0.87068 recall=0.86033 [step/sec: 1.02]
[2021-04-03 19:21:15,012] [ EVAL] - [dev dataset evaluation result] loss=0.31917 acc=0.86447 f1=0.86435 precision=0.88239 recall=0.84703 [step/sec: 5.93]
[2021-04-03 19:26:08,743] [ TRAIN] - step 1200 / 3057: loss=0.33277 acc=0.85547 f1=0.85995 precision=0.85801 recall=0.86191 [step/sec: 1.04]
[2021-04-03 19:26:36,122] [ EVAL] - [dev dataset evaluation result] loss=0.29532 acc=0.87655 f1=0.87966 precision=0.87428 recall=0.88510 [step/sec: 5.91]
[2021-04-03 19:31:30,448] [ TRAIN] - step 1500 / 3057: loss=0.29113 acc=0.87734 f1=0.88240 precision=0.88174 recall=0.88306 [step/sec: 1.01]
[2021-04-03 19:31:57,800] [ EVAL] - [dev dataset evaluation result] loss=0.28233 acc=0.88301 f1=0.88647 precision=0.87710 recall=0.89605 [step/sec: 5.92]
[2021-04-03 19:36:50,822] [ TRAIN] - step 1800 / 3057: loss=0.28595 acc=0.88281 f1=0.88987 precision=0.88081 recall=0.89911 [step/sec: 1.06]
[2021-04-03 19:37:18,143] [ EVAL] - [dev dataset evaluation result] loss=0.27718 acc=0.88310 f1=0.88768 precision=0.86995 recall=0.90614 [step/sec: 5.93]
[2021-04-03 19:42:14,001] [ TRAIN] - step 2100 / 3057: loss=0.28871 acc=0.86719 f1=0.86593 precision=0.86050 recall=0.87143 [step/sec: 1.03]
[2021-04-03 19:42:41,323] [ EVAL] - [dev dataset evaluation result] loss=0.26953 acc=0.88922 f1=0.89035 precision=0.89851 recall=0.88234 [step/sec: 5.93]
[2021-04-03 19:47:36,276] [ TRAIN] - step 2400 / 3057: loss=0.27113 acc=0.88281 f1=0.88372 precision=0.85202 recall=0.91787 [step/sec: 1.02]
[2021-04-03 19:48:03,595] [ EVAL] - [dev dataset evaluation result] loss=0.26500 acc=0.89150 f1=0.89265 precision=0.90044 recall=0.88501 [step/sec: 5.93]
[2021-04-03 19:52:56,993] [ TRAIN] - step 2700 / 3057: loss=0.25304 acc=0.89844 f1=0.90441 precision=0.90708 recall=0.90176 [step/sec: 1.00]
[2021-04-03 19:53:24,280] [ EVAL] - [dev dataset evaluation result] loss=0.25736 acc=0.89451 f1=0.89667 precision=0.89540 recall=0.89795 [step/sec: 5.93]
[2021-04-03 19:58:19,393] [ TRAIN] - step 3000 / 3057: loss=0.25258 acc=0.89141 f1=0.89681 precision=0.88433 recall=0.90964 [step/sec: 1.00]
[2021-04-03 19:58:46,698] [ EVAL] - [dev dataset evaluation result] loss=0.25527 acc=0.89533 f1=0.89708 precision=0.89927 recall=0.89491 [step/sec: 5.93]
[2021-04-03 19:59:38,235] [ TRAIN] - step 3050 / 3057: loss=0.25146 acc=0.89531 f1=0.89612 precision=0.89752 recall=0.89474 [step/sec: 1.01]
[2021-04-03 20:00:12,357] [ EVAL] - [dev dataset evaluation result] loss=0.25513 acc=0.89509 f1=0.89688 precision=0.89877 recall=0.89500 [step/sec: 5.93]
['1', '1', '1']
[0.00513761 0.03052873 0.42773667]
[0.9948624 0.9694713 0.57226336]
可见最后能达到89.5%的精确度
3.2 全部代码
import numpy as np
from paddlehub.dataset.base_nlp_dataset import TextMatchingDataset
class COVID19Competition(TextMatchingDataset):
def __init__(self, tokenizer=None, max_seq_len=None):
# base_path = '/mnt/Data1/ysc/COVID19_sim_competition/'
base_path = '/mnt/Data1/ysc/STS/'
super(COVID19Competition, self).__init__(
is_pair_wise=False, # 文本匹配类型,是否为pairwise
base_path=base_path,
train_file="train.txt", # 相对于base_path的文件路径 # 2021.04.03
dev_file="dev.txt", # 相对于base_path的文件路径 # 2021.04.03
train_file_with_header=False, # 2021.04.03
dev_file_with_header=False, # 2021.04.03
label_list=["0", "1"],
tokenizer=tokenizer,
max_seq_len=max_seq_len)
import paddle
paddle.enable_static()
import paddlehub as hub
# module = hub.Module(name='chinese-bert-wwm-ext') # download, /home/ysc/anaconda3/lib/python3.8/site-packages/paddlehub/module/manager.py
module = hub.Module(directory='/mnt/Data1/ysc/.paddlehub/modules/ernie')
# module = hub.Module(directory='/mnt/Data1/ysc/.paddlehub/modules/bert_chinese_L_12_H_768_A_12') # please decrease the batch size of your model.
# module = hub.Module(directory='/mnt/Data1/ysc/.paddlehub/modules/chinese_roberta_wwm_ext')
inputs, outputs, program = module.context(trainable=True, max_seq_len=128, num_slots=2)
tokenizer = hub.BertTokenizer(vocab_file=module.get_vocab_path(), tokenize_chinese_chars=True)
dataset = COVID19Competition(tokenizer=tokenizer, max_seq_len=128)
strategy = hub.AdamWeightDecayStrategy(weight_decay=0.01, warmup_proportion=0.1, learning_rate=5e-5)
config = hub.RunConfig(
eval_interval=300,
use_cuda=True,
num_epoch=1, # 3
batch_size=32, # 32 for ERNIE, 16 for bert, 16 for chinese_roberta_wwm_ext
checkpoint_dir='/mnt/Data1/ysc/.paddlehub/Check_Point/ernie',
strategy=strategy)
query = outputs["sequence_output"]
title = outputs['sequence_output_2']
# 创建pointwise文本匹配任务
pointwise_matching_task = hub.PointwiseTextMatchingTask(
dataset=dataset,
query_feature=query,
title_feature=title,
tokenizer=tokenizer,
config=config)
run_states=pointwise_matching_task.finetune_and_eval()
# pointwise_matching_task.load_parameters('ernie.pth')
text_pairs = [
[
"小孩吃了百令胶囊能打预防针吗", # query
"小孩吃了百令胶囊能不能打预防针" # title
],
[
"请问呕血与咯血有什么区别?", # query
"请问呕血与咯血异同?" # title
]
]
label_list=['0', '1']
# The source code of predict function is modified here 2021.04.03
# paddlehub.finetune.task.base_task.RunState
run_states = pointwise_matching_task.predict([["小孩吃了百令胶囊能打预防针吗", "小孩吃了百令胶囊能不能打预防针"],
["请问呕血与咯血有什么区别?", "请问呕血与咯血异同?" ],
['新冠疫情相似句对判定大赛', '疫情相关的呼吸领域的真实数据']], max_seq_len=128, label_list=label_list, return_result=False, accelerate_mode=True)
result =[]
for batch_states in run_states:
batch_results = batch_states.run_results
batch_infer = np.argmax(batch_results[0], axis=1)
result +=[label_list[sample_infer] for sample_infer in batch_infer]
label_0 = np.array(batch_results[0])[:,0]
label_1 = np.array(batch_results[0])[:, 1]
print(result)
print(label_0)
print(label_1)
# results = pointwise_matching_task.predict(
# data=text_pairs,
# max_seq_len=128,
# label_list=dataset.get_labels(),
# return_result=True,
# accelerate_mode=True) # False is None!
#
# print(results)
#
# for index, text in enumerate(text_pairs):
# print("data: %s, prediction_label: %s" % (text, results[index]))
4. Simnet_bow与Word2Vec 效果
4.1 ERNIE 和 simnet_bow 简单服务器调用
- 可参考此文章,代码在此,和语音识别和文本识别一样,利用API,没有什么难度,感觉不太会用,可能是版本问题,服务器使用见此,不好用
- 文本相似度计算可用paddle的短文本相似度的框架,SimNet是一个计算短文本相似度的模型,可以根据用户输入的两个文本,计算出相似度得分。该PaddleHub Module基于百度海量搜索数据进行训练,支持命令行和Python接口进行预测。同时支持用该Module的预训练embedding Fine-tune下游任务。词袋模型,不考虑语法和语序,用一组无序单词来表达一段文本
SimNet (Similarity Net) 是一个计算短文本相似度的框架,主要包括 BOW、CNN、RNN、MMDNN 等核心网络结构形式。SimNet 框架在百度各产品上广泛应用,提供语义相似度计算训练和预测框架,适用于信息检索、新闻推荐、智能客服等多个应用场景,帮助企业解决语义匹配问题
4.2 Word2Vec 求和取平均
句向量为空:
她傲慢地环视了一下会场。 自比乐毅。
一艘载着两个人的小船在水中移动。 船在动。
微拉贷 开通微米贷
一对跳舞的夫妇正在表演一场俯卧在地板上的戏。 有些人在动。
我想贷 借贷
下載 我从哪下载呀
使用simnet_bow(0.633)和word2vec(0.6188)时余弦相似度阈值设为0.7的时候,与原标签的预测精确度都为0.6左右,仅仅比瞎蒙(0.5)好一点点,比较simnet_bow和word2vec预测的标签,精确度也只有0.7左右,分类错误的句子例如:
两个小女孩穿着白色空手道制服。 两个女孩穿着拳击服。 0 1 0
两个人正在梯子上一起工作。 一个人在梯子上 0 1 0
一个戴着帽子和围裙的人在自行车上工作。 男人在摩托车上工作 0 1 0
地下储罐 地下狗屋。 0 1 0
她不合作 她在合作。 1 0 0
更换银行卡 我想重新绑定银行卡 1 0 0
两个孩子正在试验昆虫。 两个孩子在玩国旗足球。 1 0 0
没有借钱这个地方 微信借钱在哪里啊 1 0 0
刚才没接到电话,请重新打过来,谢谢 没有接到银行电话 1 0 1
具体的网址是 网站 1 0 1
一男一女站在路标前。 两个人站着。 1 0 1
开通颗粒贷 开通,微贷款 1 0 1
整体直径接近8英尺。 它的直径约为80英尺。 1 0 0
电子账单 5000分10期的账单 1 0 1
我微信流水账你们看不到吗 没看见我的流水? 1 0 1
1000元1天多少息 18000日息多少一天 1 0 1
更换电话 手机换号,怎么更改 1 0 1
在篮球场上滑板的人 在户外的人。 0 1 1
两个穿着蓝色潜水衣的孩子冲浪。 两个孩子冲浪。 0 1 1
这些戴着头盔的人正在户外攀岩。 人们正在攀岩 0 1 1
这个女孩正用绳子在一个小池塘上摇摆。 一个女孩在摇摆。 0 1 1
4.3 全部代码
import paddlehub as hub
simnet_bow = hub.Module(name="simnet_bow")
base_path = '/mnt/Data1/ysc/STS/dev.txt'
text1 = []
text2 = []
label = []
with open(base_path, 'r', encoding='utf-8')as file:
for line in file.readlines():
tmp = line.strip().split('\t')
text1.append(tmp[0])
text2.append(tmp[1])
label.append(eval(tmp[2]))
test_text = [text1, text2]
results = simnet_bow.similarity(texts=test_text, use_gpu=False)
predict = []
max_score = 0.7 # 0.8--0.6000 0.75--0.6244 0.7--0.6333 0.75--0.6261 0.6--0.6152 0.5--0.5749
for result in results:
if result['similarity'] > max_score:
predict.append(1)
else:
predict.append(0)
cnt = 0
for i in range(len(label)):
if label[i]==predict[i]:
cnt += 1
print(cnt/len(label))
from gensim.models import KeyedVectors
import jieba
import numpy as np
import re
from scipy.spatial.distance import cosine
word_vectors = KeyedVectors.load('vectors.kv')
def get_sentence_vec(sentence):
sentence = ''.join(re.findall('[\u4e00-\u9fa5|\n]',sentence))
sentence_list = ' '.join(jieba.cut(sentence)).split(' ')
vecsum = np.zeros(word_vectors.vector_size)
cnt = 0
for word in sentence_list:
try:
vecsum = vecsum + word_vectors[word]
cnt += 1
except:
continue
if cnt == 0:
# print('Not exist!')
return vecsum
return vecsum/cnt
score = 0.7 # 0.8--0.5909 0.75--0.6103 0.7--0.6188 0.65--0.621 0.6--0.6176
predict2 = []
for i in range(len(label)):
vec1 = get_sentence_vec(text1[i])
vec2 = get_sentence_vec(text2[i])
if vec1.all() == 0 or vec2.all() == 0:
# print(text1[i] + '\t' + text2[i])
predict2.append(-1)
else:
if 1 - cosine(vec1, vec2) > score:
predict2.append(1)
else:
predict2.append(0)
cnt2 = 0
length = 0
for i in range(len(label)):
if predict2[i] == -1:
continue
length += 1
if predict2[i] == label[i]:
cnt2 += 1
print(cnt2/length)
cnt3 = 0
length2 = 0
for i in range(len(label)):
if predict2[i] == -1:
continue
length2 += 1
if predict[i] == predict2[i]:
cnt3 += 1
else:
print(text1[i],text2[i],predict[i], predict2[i], label[i])
print(cnt3/length2) # 0.7108
5. STS-B 数据集
Semantic Textual Similarity Benchmark: 这是一个类似回归的问题——给出一对句子, 使用1~5(0-5?)的评分评价两者在语义上的相似程度,来自比赛的Task 1: Semantic Textual Similarity Multilingual and Crosslingual Focused Evaluation,介绍,参考文献引用:
Cer D M, Diab M T, Agirre E, et al. SemEval-2017 Task 1: Semantic Textual Similarity Multilingual and Crosslingual Focused Evaluation[J]. meeting of the association for computational linguistics, 2017: 1-14.
不同模型在Semantic Textual Similarity on STS Benchmark数据集上的表现与排名
6. 其它
官方给了一个语义匹配的示例脚本,但是看不懂
ERNIE的论文代码复现过程在此,ERNIE的简介见–ERNIE: Enhanced Language Representation with Informative Entities,语义匹配,不同数据集有不同的表现最好的模型
wget https://dumps.wikimedia.org/enwiki/latest/enwiki-latest-pages-articles.xml.bz2 # Download Wikidump
wget -c https://cloud.tsinghua.edu.cn/f/a519318708df4dc8a853/?dl=1 -O alias_entity.txt # Download alise
python3 pretrain_data/WikiExtractor.py enwiki-latest-pages-articles.xml.bz2 -o pretrain_data/output -l --min_text_length 100 --filter_disambig_pages -it abbr,b,big --processes 4 # WikiExtractor
python3 pretrain_data/extract.py 4 # Modify anchors with 4 processes
python3 pretrain_data/create_ids.py 4 # Preprocess with 4 processes
...
Preprocess with 4 processes这一步需要安装tensorflow:
pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple/ --upgrade tensorflow-gpu
INFO: Finished 4-process extraction of 6132409 articles in 4192.1s (1462.9 art/s)
INFO: total of page: 11143091, total of articl page: 6274306; total of used articl page: 6132409
...
还是放弃了,他们使用8个NVIDIA-2080Ti对我们的模型进行预训练,每个GPU中有32个实例。完成训练需要将近一天的时间(一个epoch就足够了),我觉得并不能很好的复现他们的结果
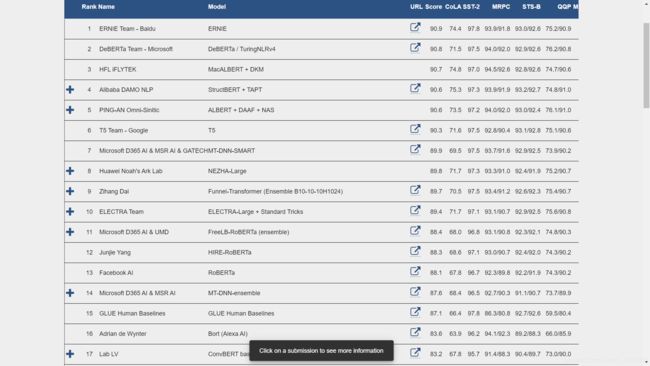
另:glue排名,ERNIE的综合表现是相当好的:
小结
- Paddlehub是个好东西,但是对2.0的支持不太行,只能1.8的版本,这样的话只能有3个BERT模型可以使用,主要还是套ERNIE的语义匹配的代码
- 中文STS语料还是东找找西找找拼起来的一个数据集,感觉什么微粒贷的数据集其实可以不需要,这里只迭代了一次,精度就可以达到90%左右了,总体来说还可以
- Simnet_bow其实原来是什么不太清楚,是不是就是BOW,应该就是的呢,效果一般,Word2Vec效果也一般,但是感觉仅考虑语义的话是不是又不太行?这里之后可以考虑加权求和或者D-S融合处理一下
- 英语模型应该不用复现吧,直接查论文或者官网的Rank呗,英文其实原理都是一样的,就是WordEmbedding不一样,就不管了吧
- 总之文本处理到这里真结束了,明天开始语音的学习!!!