文献笔记02 网络入侵检测技术综述(信息安全学报)
文章目录
- 网络入侵检测技术综述
-
- 大纲
- 一、入侵检测系统分类
-
- 1.基于数据来源划分
- 2.基于检测技术划分
- 二、基于传统机器学习的入侵检测
-
- 1.入侵数据处理
- 2.监督机器学习技术
- 3.无监督机器学习技术
- 4.小结
- 三、基于深度学习的入侵检测
-
- 1.生成方法
- 2.判别方法
- 3.生成对抗网络
- 4.小结
- 四、基于强化学习的入侵检测
- 五、基于可视化分析的入侵检测
- 六、总结
网络入侵检测技术综述
链接:百度网盘链接
提取码:tktt
大纲
1:入侵检测系统的详细分类
2:传统机器学习技术在入侵检测领域的应用现状
3:深度学习方法在入侵检测领域的应用情况
4:强化学习方法
5:对可视化分析技术在入侵检测的应用进行阐述
6:总结
一、入侵检测系统分类
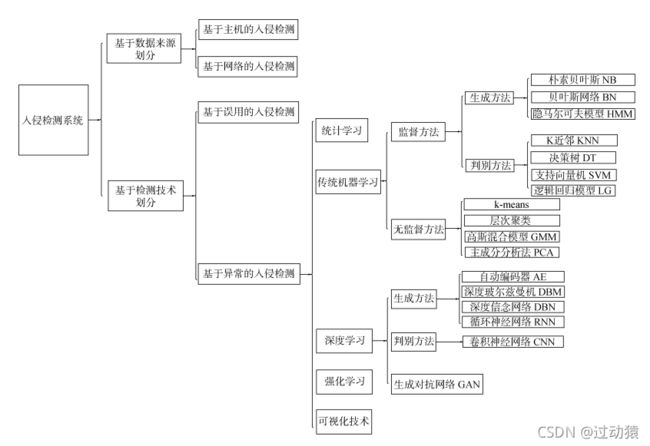
1.基于数据来源划分
-
基于主机的IDS(HIDS)
位于被监视系统上的软件组件。主要检测系统事件,分析与操作系统信息相关的事件,通过浏览日志,系统调用,文件系统修改及其他状态和活动来检测入侵
优点:能够在发送和接收数据前通过扫描流量活动来检测内部威胁
缺点:只监视主机,需要安装在每个主机上,且无法观测网络流量,无法分析与网络相关的行为信息 -
基于网络的IDS(NIDS)
观察并分析实时网络流量和监视多个主机。旨在手机数据包信息,并查看其中内容,以检测网络中的入侵行为。
优点:只有一个系统监视网络,不必在每个主机上安装,节省成本和时间
缺点:难以获取所监视系统的内部状态信息,导致检测更加困难基于网络的数据:
基于流:只包含网络连接相关的元信息
基于包:还包含有效载荷数据集:
DARPA1998、DARPA1999、KDD1999、NSL-KDD、Gure-KDD、CIDDS-001、
CICIDS2017、ISCX2012、Kyoto2006、UNSW-NB15
2.基于检测技术划分
-
基于误用的IDS(MIDS):黑名单
也称为基于签名的IDS,是将传入的网络流量与已知签名进行匹配,一旦命中则报警
三种方法:状态建模、字符串匹配、专家系统
缺点:无法检测未知攻击,所以基于异常的IDS是目前研究和开发的重点
-
基于异常的IDS(AIDS):白名单
对系统异常的行为进行检测,当检测行为与正常行为偏离较大时,发出告警信息
二、基于传统机器学习的入侵检测
入侵数据处理、监督机器学习技术、非监督机器学习技术
1.入侵数据处理
-
大规模入侵检测数据集中包含了基本特征、内容特征、流量特征
基本特征:TCP连接的特征
持续时间、协议类型、源字节数目、目的字节数目等
内容特征:从数据包提取的特征
登陆失败次数、创建的文件数目、获取的文件数目等
流量特征:与流量传输相关的特征
源主机数目、目的主机数目等
不同的入侵检测数据集包含的特征也存在差异,要具体分析
-
数据集预处理
符号特征数据化
使用独热编码等编码方式对数据进行映射处理
数据特征归一化
使用min-max、Z-score等归一化方法将数据数值缩小至同一量纲
-
特征工程
对数据集进行特征选择 / 提取能够去除冗余数据、降低特征维度、减小计算开销, 提升分类器的泛化能力和检测性能。
特征选择:
过滤式方法
信息增益、相关系数等
封装式方法
遗传算法等
嵌入式方法
正则化方法,如LASSO回归
特征提取:
线性变换方法
主成分分析、线性鉴别方法等
非线性变换方法
基于核方法的PCA等
对大量论文进行综合分析后发现,决定入侵检测性能的重要特征通常是基本特征和流量特征
2.监督机器学习技术
优点:能够充分利用先验知识,明确地对未知样本数据进行分类
缺点:训练数据的选取评估标注需要花费大量的人力和时间
-
生成方法(概率方法):
生成方法反应的是同类流量数据的相似度
朴素贝叶斯、贝叶斯网络、隐马尔可夫模型
优点:
(1)在数据不完整的情况下,仍能检测异常
(2)可以学习存在因变量的模型
(3)收敛速度快缺点:
(1)需要更多的计算资源
(2)仅用于分类任务时,存在较多冗余信息,且学习和计算的过程较复杂 -
判别方法(非概率方法):
判别方法反映的是正常流量和异常流量数据之间的差异
K-近邻、决策树、支持向量机、逻辑回归
优点:
(1)直接面对预测问题,准确率更高
(2)可以对输入数据进行各种程度的抽象,从而简化学习问题
(3)对于分类任务,冗余信息少,节省计算资源缺点:
(1)难以反应数据本身的特性
(2)数据缺失和异常值对预测结果影响较大
目前已有研究将两种方法结合,从而获得更大的优越性
3.无监督机器学习技术
-
常用的无监督机器学习技术
k-means、层次聚类、高斯混合模型、主成分分析
-
无监督机器学习技术优缺点
优点:不需要人为标注数据,减少了人为误差;降低计算开销,提升检测准确性
缺点:需要对无监督处理结果进行大量分析;对于噪声和异常值敏感
4.小结
-
传统机器学习构建入侵检测系统的思路是:
数据预处理 -> 特征工程 -> 选择用于分类的传统机器学习算法 -> 训练模型 -> 预测
二分类:正常数据 / 异常数据
多分类:攻击类型 -
对引用论文的分析得出的推论
一般规律:
(1)贝叶斯网络检测能力 > 朴素贝叶斯检测能力
(2)基于树的方法的检测能力 > 基于概率的方法的检测能力,因为树方法计算复杂度低,能够处理不相关特征的数据
(3)集成学习方法的检测能力 > 单个分类器的能检测能力,因为集成学习方法能捕获到更多信息目前基于传统机器学习方法的IDS需要解决的问题有:
(1)误报率高、检测率低
(2)数据特征维度高,数据量大导致检测困难、存在冗余无关数据,需要耗费大量时间
(3)算法模型自身存在的问题,对算法进行改善
(4)数据不平衡问题,正常数据数量远大于异常数据数量 (需要重点解决) -
文献总结
(1)使用的方法和性能
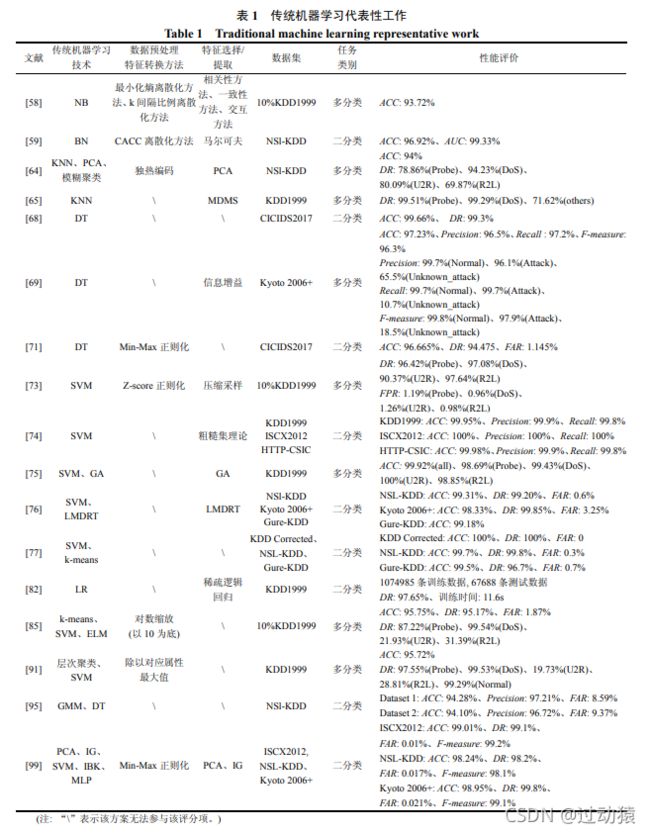
(2)解决的问题

三、基于深度学习的入侵检测
生成方法、判别方法、生成对抗网络
1.生成方法
-
自动编码器(AE)
输入层 —> 编码层 —> 解码层
被广泛应用于入侵检测领域中的降维任务 ,可以对非线性信息进行降维
-
深度玻尔兹曼机(RBM)
受限玻尔兹曼机:是一种通过输入数据集学习概率分布的随机生成神经网络,包含一层可视层和 一层隐藏层。
深度玻尔兹曼机:由多层受限玻尔兹曼机叠加,是一个完全无向的模型。能够从大量无标签数据中学习出高阶特征,鲁棒性较好
-
深度信念网络(DBN)
深度信念网络:是一种由若干层RBM和一层BP(反向传播)组成的有向深层神经网络。
通过隐层提取特征使得后面层次的训练数据更具有代表性,还可以解决复杂高纬数据的检测问题
-
循环神经网络(RNN)
循环神经网络:以序列数据为输入,在序列演进方向进行递归的神经网络。
具有挖掘数据中的时序信息和语义信息的 深度表达能力。
因为RNN存在梯度消失和梯度爆炸的问题,所以LSTM(长短期记忆网络)通过设计“门”结构实现信息的保留和选择的功能。GRU(门控循环单元)是LSTM的一种变体,与LSTM相比,GRU结构更简单,效果也很好。
2.判别方法
-
卷积神经网络(CNN)
卷积神经网络:是一种包含了卷积计算且具有深度结构的前馈神经网络。
能够更准确且高效地提取特征。
3.生成对抗网络
生成对抗网络(GAN):无监督学习方法,通过生成模型和判别模型的相互博弈学习产生高质量输出。
GAN能够处理数据类别不平衡问题。
4.小结
-
基于深度学习的IDS解决的问题
(1)数据集不平衡问题
(2)网络数据量较大、特征维度增加、浅层机器学习技术难以对海量高纬数据进行检测、难以提取数据中非线性特征信息
(3)对算法模型本身进行改善 -
已有工作对上述问题的解决方案
(1)算法级别上(成本函数)和数据级别上(欠采样和过采样等)和GAN
(2)大部分深度学习算法如AE、DBM、DBN、LSTM、CNN等都已经用于解决这一问题
(3)例如使用SVM替换softmax函数提升GRU模型的检测能力;使用遗传算法来优化DBN结构等 -
基于深度学习的IDS面临的问题:
(1)训练速度,计算存储问题。通常需要多个GPU来处理数据
(2)模型调参问题。
(3)模型优化问题。会遇到梯度消失,梯度爆炸,局部最优的问题
(4)实时检测问题。 -
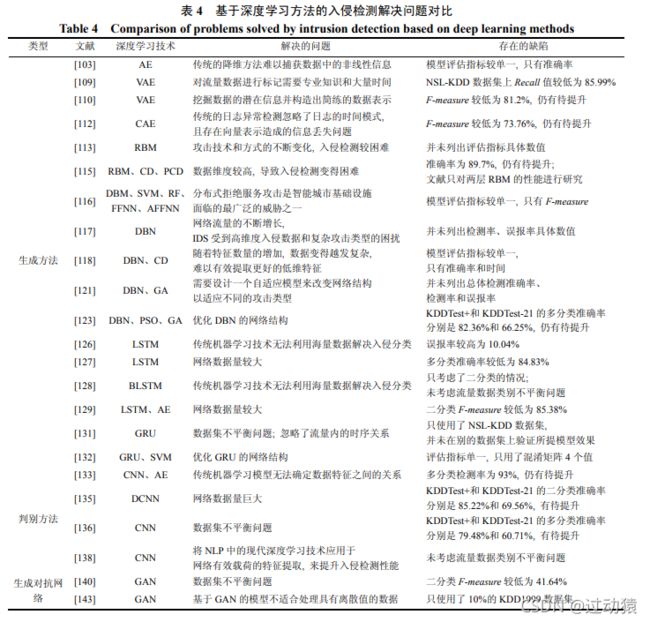
文献总结
(1)使用的方法和任务

(2)解决的问题
四、基于强化学习的入侵检测
强化学习(RL):是用于描述和解决代理在动态环境的交互过程中通过对策略的学习,达到回报最大化或者 达到特定目标的问题。
可以为复杂的随机任务自动构建顺序最优策略。
深度强化学习(DRL):

优点:能够具有类似高度非线性模型预测性能。预测耗费时间更少,且能够处理高度不平衡的数据。
缺点:采样效率较低、奖励函数的设置困难、目标局部最优问题。

五、基于可视化分析的入侵检测
产生的背景:人工遍历警报日志需要耗费大量人力和时间。
网络安全可视化技术:通过将各种网络安全数据、警报信息等进行可视化,将抽象的信息转换为便于直观理解的图像信息,能够帮助安全管理人员快速识别潜在的异常事件和攻击行为。
基于可视化分析的入侵检测领域中常用的网络数据源包含:网络流量数据 和 日志数据

面临的问题:
(1)如何实时显示并处理海量数据
(2)如何搭建入侵检测可视化协同工作环境
(3)如何提升入侵检测可视化系统的易用性、交互性、扩展性
(4)如何建立一套规范统一的可视化评估体系
六、总结
-
入侵检测数据的选择
使用最广泛的公开数据集:KDD1999、DAPRA1998、DARPA1999。但是这些数据集年代久远
新数据集:UNSW-NB15、CICIDS2017、CIDDS-001等,包含了一些新攻击类型,更有说服力
-
入侵检测面临的挑战
海量高维数据、数据集不平衡、实时监测等
(1)海量高维数据
传统机器学习方法:聚类和降维,对数据的处理不深入
深度学习方法:特征工程,训练过程复杂(2)数据不平衡
成本函数
欠采样:缩小了样本的整体数量
过采样:容易发生过拟合问题
GAN:生成异常数据来解决该问题(3)实时检测
目前大部分的IDS都是使用公开数据集,研究离线的入侵检测。随着网络中数据规模的扩大,攻击种类和数量的增加,对攻击行为进行实时检测变得越发重要,实时的攻击检测是亟需解决的问题。
-
检测技术的发展
深度学习方法、强化学习方法、可视化方法会应用的越来越广泛。这些方法进行组合也可以提升IDS的检测性能。
-
检测性能的评估
通常准确率、检测率、精确率、F-measure值越高,误报率越低,IDS性能越好。
在未来的研究中, 统一使用常用的评估指标对测试数据集的检测结果进行详细展示, 将有利于增加说服力, 能够较好地体现所提方法的泛化性能。
文章目录
- 网络入侵检测技术综述
-
- 大纲
- 一、入侵检测系统分类
-
- 1.基于数据来源划分
- 2.基于检测技术划分
- 二、基于传统机器学习的入侵检测
-
- 1.入侵数据处理
- 2.监督机器学习技术
- 3.无监督机器学习技术
- 4.小结
- 三、基于深度学习的入侵检测
-
- 1.生成方法
- 2.判别方法
- 3.生成对抗网络
- 4.小结
- 四、基于强化学习的入侵检测
- 五、基于可视化分析的入侵检测
- 六、总结
网络入侵检测技术综述
链接:百度网盘链接
提取码:tktt
大纲
1:入侵检测系统的详细分类
2:传统机器学习技术在入侵检测领域的应用现状
3:深度学习方法在入侵检测领域的应用情况
4:强化学习方法
5:对可视化分析技术在入侵检测的应用进行阐述
6:总结
一、入侵检测系统分类
1.基于数据来源划分
-
基于主机的IDS(HIDS)
位于被监视系统上的软件组件。主要检测系统事件,分析与操作系统信息相关的事件,通过浏览日志,系统调用,文件系统修改及其他状态和活动来检测入侵
优点:能够在发送和接收数据前通过扫描流量活动来检测内部威胁
缺点:只监视主机,需要安装在每个主机上,且无法观测网络流量,无法分析与网络相关的行为信息 -
基于网络的IDS(NIDS)
观察并分析实时网络流量和监视多个主机。旨在手机数据包信息,并查看其中内容,以检测网络中的入侵行为。
优点:只有一个系统监视网络,不必在每个主机上安装,节省成本和时间
缺点:难以获取所监视系统的内部状态信息,导致检测更加困难基于网络的数据:
基于流:只包含网络连接相关的元信息
基于包:还包含有效载荷数据集:
DARPA1998、DARPA1999、KDD1999、NSL-KDD、Gure-KDD、CIDDS-001、
CICIDS2017、ISCX2012、Kyoto2006、UNSW-NB15
2.基于检测技术划分
-
基于误用的IDS(MIDS):黑名单
也称为基于签名的IDS,是将传入的网络流量与已知签名进行匹配,一旦命中则报警
三种方法:状态建模、字符串匹配、专家系统
缺点:无法检测未知攻击,所以基于异常的IDS是目前研究和开发的重点
-
基于异常的IDS(AIDS):白名单
对系统异常的行为进行检测,当检测行为与正常行为偏离较大时,发出告警信息
二、基于传统机器学习的入侵检测
入侵数据处理、监督机器学习技术、非监督机器学习技术
1.入侵数据处理
-
大规模入侵检测数据集中包含了基本特征、内容特征、流量特征
基本特征:TCP连接的特征
持续时间、协议类型、源字节数目、目的字节数目等
内容特征:从数据包提取的特征
登陆失败次数、创建的文件数目、获取的文件数目等
流量特征:与流量传输相关的特征
源主机数目、目的主机数目等
不同的入侵检测数据集包含的特征也存在差异,要具体分析
-
数据集预处理
符号特征数据化
使用独热编码等编码方式对数据进行映射处理
数据特征归一化
使用min-max、Z-score等归一化方法将数据数值缩小至同一量纲
-
特征工程
对数据集进行特征选择 / 提取能够去除冗余数据、降低特征维度、减小计算开销, 提升分类器的泛化能力和检测性能。
特征选择:
过滤式方法
信息增益、相关系数等
封装式方法
遗传算法等
嵌入式方法
正则化方法,如LASSO回归
特征提取:
线性变换方法
主成分分析、线性鉴别方法等
非线性变换方法
基于核方法的PCA等
对大量论文进行综合分析后发现,决定入侵检测性能的重要特征通常是基本特征和流量特征
2.监督机器学习技术
优点:能够充分利用先验知识,明确地对未知样本数据进行分类
缺点:训练数据的选取评估标注需要花费大量的人力和时间
-
生成方法(概率方法):
生成方法反应的是同类流量数据的相似度
朴素贝叶斯、贝叶斯网络、隐马尔可夫模型
优点:
(1)在数据不完整的情况下,仍能检测异常
(2)可以学习存在因变量的模型
(3)收敛速度快缺点:
(1)需要更多的计算资源
(2)仅用于分类任务时,存在较多冗余信息,且学习和计算的过程较复杂 -
判别方法(非概率方法):
判别方法反映的是正常流量和异常流量数据之间的差异
K-近邻、决策树、支持向量机、逻辑回归
优点:
(1)直接面对预测问题,准确率更高
(2)可以对输入数据进行各种程度的抽象,从而简化学习问题
(3)对于分类任务,冗余信息少,节省计算资源缺点:
(1)难以反应数据本身的特性
(2)数据缺失和异常值对预测结果影响较大
目前已有研究将两种方法结合,从而获得更大的优越性
3.无监督机器学习技术
-
常用的无监督机器学习技术
k-means、层次聚类、高斯混合模型、主成分分析
-
无监督机器学习技术优缺点
优点:不需要人为标注数据,减少了人为误差;降低计算开销,提升检测准确性
缺点:需要对无监督处理结果进行大量分析;对于噪声和异常值敏感
4.小结
-
传统机器学习构建入侵检测系统的思路是:
数据预处理 -> 特征工程 -> 选择用于分类的传统机器学习算法 -> 训练模型 -> 预测
二分类:正常数据 / 异常数据
多分类:攻击类型 -
对引用论文的分析得出的推论
一般规律:
(1)贝叶斯网络检测能力 > 朴素贝叶斯检测能力
(2)基于树的方法的检测能力 > 基于概率的方法的检测能力,因为树方法计算复杂度低,能够处理不相关特征的数据
(3)集成学习方法的检测能力 > 单个分类器的能检测能力,因为集成学习方法能捕获到更多信息目前基于传统机器学习方法的IDS需要解决的问题有:
(1)误报率高、检测率低
(2)数据特征维度高,数据量大导致检测困难、存在冗余无关数据,需要耗费大量时间
(3)算法模型自身存在的问题,对算法进行改善
(4)数据不平衡问题,正常数据数量远大于异常数据数量 (需要重点解决) -
文献总结
(1)使用的方法和性能
(2)解决的问题
三、基于深度学习的入侵检测
生成方法、判别方法、生成对抗网络
1.生成方法
-
自动编码器(AE)
输入层 —> 编码层 —> 解码层
被广泛应用于入侵检测领域中的降维任务 ,可以对非线性信息进行降维
-
深度玻尔兹曼机(RBM)
受限玻尔兹曼机:是一种通过输入数据集学习概率分布的随机生成神经网络,包含一层可视层和 一层隐藏层。
深度玻尔兹曼机:由多层受限玻尔兹曼机叠加,是一个完全无向的模型。能够从大量无标签数据中学习出高阶特征,鲁棒性较好
-
深度信念网络(DBN)
深度信念网络:是一种由若干层RBM和一层BP(反向传播)组成的有向深层神经网络。
通过隐层提取特征使得后面层次的训练数据更具有代表性,还可以解决复杂高纬数据的检测问题
-
循环神经网络(RNN)
循环神经网络:以序列数据为输入,在序列演进方向进行递归的神经网络。
具有挖掘数据中的时序信息和语义信息的 深度表达能力。
因为RNN存在梯度消失和梯度爆炸的问题,所以LSTM(长短期记忆网络)通过设计“门”结构实现信息的保留和选择的功能。GRU(门控循环单元)是LSTM的一种变体,与LSTM相比,GRU结构更简单,效果也很好。
2.判别方法
-
卷积神经网络(CNN)
卷积神经网络:是一种包含了卷积计算且具有深度结构的前馈神经网络。
能够更准确且高效地提取特征。
3.生成对抗网络
生成对抗网络(GAN):无监督学习方法,通过生成模型和判别模型的相互博弈学习产生高质量输出。
GAN能够处理数据类别不平衡问题。
4.小结
-
基于深度学习的IDS解决的问题
(1)数据集不平衡问题
(2)网络数据量较大、特征维度增加、浅层机器学习技术难以对海量高纬数据进行检测、难以提取数据中非线性特征信息
(3)对算法模型本身进行改善 -
已有工作对上述问题的解决方案
(1)算法级别上(成本函数)和数据级别上(欠采样和过采样等)和GAN
(2)大部分深度学习算法如AE、DBM、DBN、LSTM、CNN等都已经用于解决这一问题
(3)例如使用SVM替换softmax函数提升GRU模型的检测能力;使用遗传算法来优化DBN结构等 -
基于深度学习的IDS面临的问题:
(1)训练速度,计算存储问题。通常需要多个GPU来处理数据
(2)模型调参问题。
(3)模型优化问题。会遇到梯度消失,梯度爆炸,局部最优的问题
(4)实时检测问题。 -
文献总结
(1)使用的方法和任务
(2)解决的问题
四、基于强化学习的入侵检测
强化学习(RL):是用于描述和解决代理在动态环境的交互过程中通过对策略的学习,达到回报最大化或者 达到特定目标的问题。
可以为复杂的随机任务自动构建顺序最优策略。
深度强化学习(DRL):
优点:能够具有类似高度非线性模型预测性能。预测耗费时间更少,且能够处理高度不平衡的数据。
缺点:采样效率较低、奖励函数的设置困难、目标局部最优问题。
五、基于可视化分析的入侵检测
产生的背景:人工遍历警报日志需要耗费大量人力和时间。
网络安全可视化技术:通过将各种网络安全数据、警报信息等进行可视化,将抽象的信息转换为便于直观理解的图像信息,能够帮助安全管理人员快速识别潜在的异常事件和攻击行为。
基于可视化分析的入侵检测领域中常用的网络数据源包含:网络流量数据 和 日志数据
面临的问题:
(1)如何实时显示并处理海量数据
(2)如何搭建入侵检测可视化协同工作环境
(3)如何提升入侵检测可视化系统的易用性、交互性、扩展性
(4)如何建立一套规范统一的可视化评估体系
六、总结
-
入侵检测数据的选择
使用最广泛的公开数据集:KDD1999、DAPRA1998、DARPA1999。但是这些数据集年代久远
新数据集:UNSW-NB15、CICIDS2017、CIDDS-001等,包含了一些新攻击类型,更有说服力
-
入侵检测面临的挑战
海量高维数据、数据集不平衡、实时监测等
(1)海量高维数据
传统机器学习方法:聚类和降维,对数据的处理不深入
深度学习方法:特征工程,训练过程复杂(2)数据不平衡
成本函数
欠采样:缩小了样本的整体数量
过采样:容易发生过拟合问题
GAN:生成异常数据来解决该问题(3)实时检测
目前大部分的IDS都是使用公开数据集,研究离线的入侵检测。随着网络中数据规模的扩大,攻击种类和数量的增加,对攻击行为进行实时检测变得越发重要,实时的攻击检测是亟需解决的问题。
-
检测技术的发展
深度学习方法、强化学习方法、可视化方法会应用的越来越广泛。这些方法进行组合也可以提升IDS的检测性能。
-
检测性能的评估
通常准确率、检测率、精确率、F-measure值越高,误报率越低,IDS性能越好。
在未来的研究中, 统一使用常用的评估指标对测试数据集的检测结果进行详细展示, 将有利于增加说服力, 能够较好地体现所提方法的泛化性能。