六.SPSS+finebi实现基于分类算法的理财产品顾客亏损及收益分析
SPSS+finebi实现基于分类算法的理财产品顾客亏损及收益分析第六部分,用数据挖掘工具IBM SPSS对finebi获取的数据实现基于决策树分析不同收益顾客特征,以下先介绍是一下常用的数据挖掘工具。
1.知识准备
数据挖掘工具介绍。
1.1 Rapid Miner
Rapid Miner,原名YALE又一个学习环境,是一个用于机器学习和数据挖掘实验的环境,用于研究和实际的数据挖掘任务。毫无疑问,这是世界领先的数据挖掘开源系统。该工具以Java编程语言编写,通过基于模板的框架提供高级分析。
它使得实验可以由大量的可任意嵌套的操作符组成,这些操作符在XML文件中是详细的,并且是由快速的Miner的图形用户界面完成的。最好的是用户不需要编写代码。它已经有许多模板和其他工具,让我们可以轻松地分析数据。
1.2 IBM SPSS Modeler
IBM SPSS Modeler工具工作台最适合处理文本分析等大型项目,其可视化界面非常有价值。 它允许您在不编程的情况下生成各种数据挖掘算法。 它也可以用于异常检测、贝叶斯网络、CARMA、Cox回归以及使用多层感知器进行反向传播学习的基本神经网络。
1.3 Oracle Data Mining
Oracle。 作为“高级分析数据库”选项的一部分,Oracle数据挖掘功能允许其用户发现洞察力,进行预测并利用其Oracle数据。您可以构建模型来发现客户行为目标客户和开发概要文件。
Oracle Data Miner GUI使数据分析师、业务分析师和数据科学家能够使用相当优雅的拖放解决方案处理数据库内的数据。 它还可以为整个企业的自动化、调度和部署创建SQL和PL / SQL脚本。
1.4 Teradata
Teradata认识到,尽管大数据是令人敬畏的,但如果您实际上并不知道如何分析和使用它,那么它是毫无价值的。 想象一下,有数百万的数据点没有查询的技能。 这就是Teradata所提供的。它们提供数据仓库,大数据和分析以及市场营销应用程序方面的端到端解决方案和服务。
Teradata还提供一系列的服务,包括实施,业务咨询,培训和支持。
1.5 Framed Data
这是一个完全管理的解决方案,这意味着你不需要做任何事情,而是坐下来等待见解。 框架数据从企业获取数据,并将其转化为可行的见解和决策。 他们在云中训练、优化和存储产品的电离模型,并通过API提供预测,消除基础架构开销。他们提供了仪表板和情景分析工具,告诉你哪些公司杠杆是驾驶你关心的指标。
1.6 Kaggle
Kaggle是全球最大的数据科学社区。 公司和研究人员张贴他们的数据,来自世界各地的统计人员和数据挖掘者竞相制作最好的模型。Kaggle是数据科学竞赛的平台。 它帮助您解决难题,招募强大的团队,并扩大您的数据科学人才的力量。
3个步骤的工作 :
上传预测问题
提交
评估和交流
1.7 Weka
WEKA是一个非常复杂的数据挖掘工具。 它向您展示了数据集、集群、预测建模、可视化等方面的各种关系。您可以应用多种分类器来深入了解数据。
1.8 Rattle
Rattle代表R分析工具轻松学习。 它提供数据的统计和可视化汇总,将数据转换为可以轻松建模的表单,从数据中构建无监督模型和监督模型,以图形方式呈现模型的性能,并对新数据集进行评分。
它是一个使用Gnome图形界面在统计语言R编写的免费的开源数据挖掘工具包。 它运行在GNU / Linux,Macintosh OS X和MS / Windows下。
1.9 KNIME
Konstanz信息采集器是一个用户友好、可理解、全面的开源数据集成、处理、分析和探索平台。它有一个图形用户界面,帮助用户方便地连接节点进行数据处理。
KNIME还通过模块化的数据流水线概念集成了机器学习和数据挖掘的各种组件,并引起了商业智能和财务数据分析的注意。
1.10 Python
作为一种免费且开放源代码的语言,Python通常与R进行比较,以方便使用。 与R不同的是,Python的学习曲线往往很短,因此成了传奇。 许多用户发现,他们可以开始构建数据集,并在几分钟内完成极其复杂的亲和力分析。 只要您熟悉变量、数据类型、函数、条件和循环等基本编程概念,最常见的业务用例数据可视化就很简单。
2.基于决策树分析不同收益顾客特征
2.1 基于决策树分析不同收益顾客特征的数据挖掘流

2.2 数据处理
2.2.1 导出字段“收益_离散”
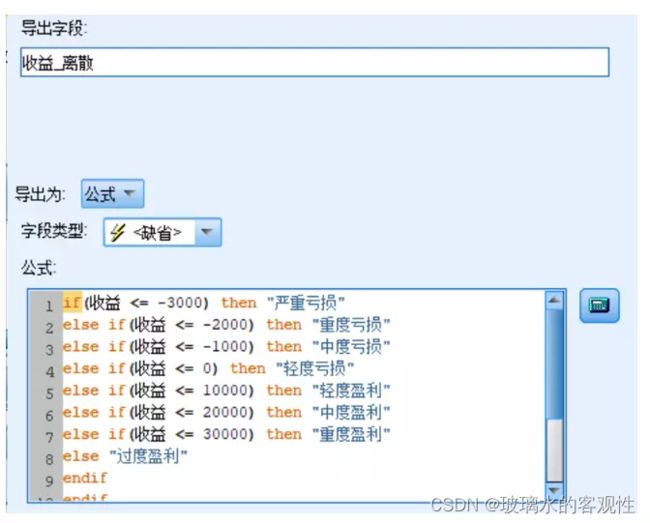
导入数据源后,在SPSS Modeler加入“导出”节点,根据收益的八个区间设置八个不同的值“严重亏损”、“重度亏损”、“中度亏损”、“轻度亏损”、“轻度盈利”、“中度盈利”、“重度盈利”、“过度盈利”
2.2.2 过滤数据并设置类型
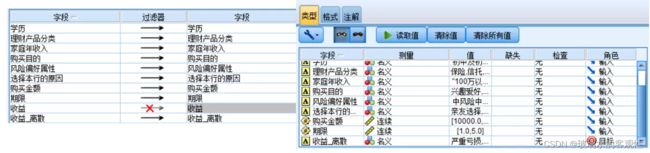
“过滤”节点的设置:由于我们的目标变量为“收益_离散”,而变量“收益”直接影响,目标变量进而影响其他变量的预测变量重要性,所以应该使用过滤器过滤掉“收益”变量。
“类型”节点的设置:将“收益_离散”设置为目标变量,其他变量设置为输入变量。
基于finebi获取资料:理财产品顾客分类数据可视化。
实现数据可视化面板制作工具:帆软finebi。
数据挖掘工具:IBM SPSS。