基于卷积神经网络的吸烟行为图像分类
(1) 基于深度学习的图像分类基本步骤
第1步.通过一定的技术采集图像,对图像进行消噪、归一化、增强等预处理,以增强图像质量;
第2步.采用二维小波变换对增强后图像进行细化处理,将低频系数作为图像分类的特征向量;
第3步.采用主成分分析对原始图像分类的特征进行处理,提取最有效的图像分类特征,组成特征向量;
第4步.将最有效的图像分类特征作为广义回归神经网络输入,通过专家对图像类别进行标记,作为广义回归神经网络输出,建立图像分类的训练样本集;
第5步.根据训练样本集,通过对广义回归神经网络进行学习,建立图像分类的分类器;
第6步.对于待分类图像,进行图像预处理、特征提取和选择等步骤,并输入图像分类器进行分类,得到图像划分的类别,并对图像划分的类别进行统计和分析。
(2) 图像分类中常见深度学习模型简介
① LeNet
LeNet神经网络由深度学习三巨头之一的Yan LeCun提出,他同时也是卷积神经网络 (CNN,Convolutional Neural Networks)之父。手写字体识别模型LeNet5诞生于1994年,是最早的卷积神经网络之一。LeNet5通过巧妙的设计,利用卷积、参数共享、池化等操作提取特征,避免了大量的计算成本,最后再使用全连接神经网络进行分类识别,这个网络也是大量神经网络架构的起点。
② AlexNet
AlexNet是在LeNet的基础上加深了网络的结构,学习更丰富更高维的图像特征。具有更深的网络结构、使用层叠的卷积层,即卷积层+卷积层+池化层来提取图像的特征、使用Dropout抑制过拟合、使用数据增强Data Augmentation抑制过拟合、使用Relu替换之前的sigmoid的作为激活函数、多GPU训练的特点。
③ VGGNet
VGGNet获得2014年ImageNet亚军,VGG是牛津大学 Visual Geometry Group(视觉几何组)的缩写,以研究机构命名。VGG在AlexNet基础上做了改进,搭建更深的卷积神经网络:使用3x3卷积核,模型达到16-19层,16层的被称为VGG16,19层的被称为VGG19。使用Single-Scale和Multi-Scale训练和评估模型。以此提高了大规模图像分类的精度。VGGNet的主要特点在于:(1)网络很深;(2)卷积层中使用的卷积核很小,且都是3*3的卷积核。
④ GoogLeNet
GoogLeNet是2014年Christian Szegedy提出的一种全新的深度学习结构,在这之前的AlexNet、VGG等结构都是通过增大网络的深度(层数)来获得更好的训练效果,但层数的增加会带来很多负作用,比如overfit、梯度消失、梯度爆炸等。inception的提出则从另一种角度来提升训练结果:能更高效的利用计算资源,在相同的计算量下能提取到更多的特征,从而提升训练结果。
⑤ ResNet
ResNet(Residual Neural Network)由微软研究院的Kaiming He等四名华人提出,通过使用ResNet Unit成功训练出了152层的神经网络,并在ILSVRC2015比赛中取得冠军,在top5上的错误率为3.57%,同时参数量比VGGNet低,效果非常突出。ResNet的结构可以极快的加速神经网络的训练,模型的准确率也有比较大的提升。同时ResNet的推广性非常好,甚至可以直接用到InceptionNet网络中。ResNet的主要思想是在网络中增加了直连通道,即Highway Network的思想。此前的网络结构是性能输入做一个非线性变换,而Highway Network则允许保留之前网络层的一定比例的输出。ResNet的思想和Highway Network的思想也非常类似,允许原始输入信息直接传到后面的层中。这样的话这一层的神经网络可以不用学习整个的输出,而是学习上一个网络输出的残差,因此ResNet又叫做残差网络。
(3) 吸烟行为图像分类的卷积神经网络结构设计
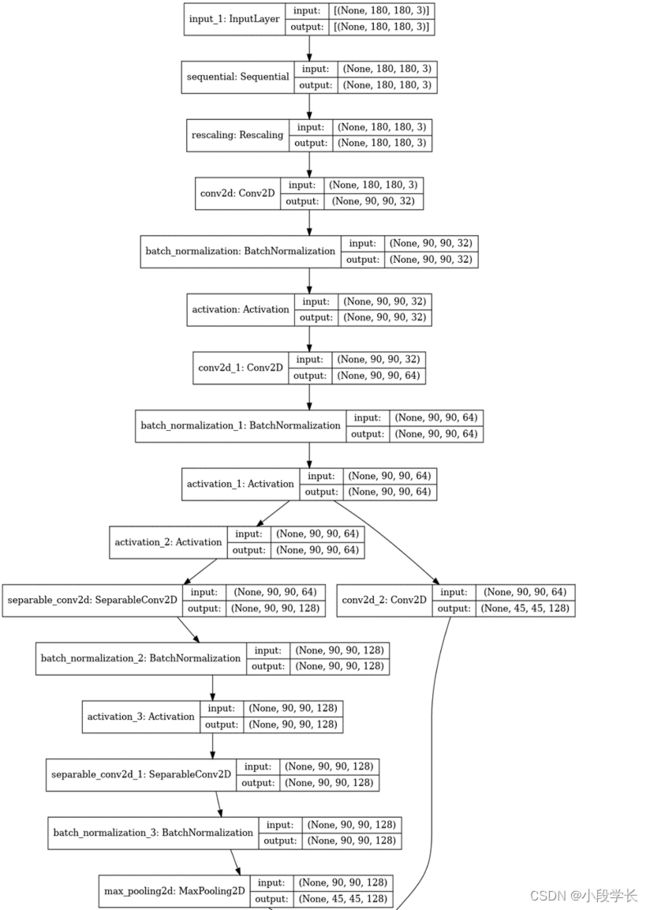

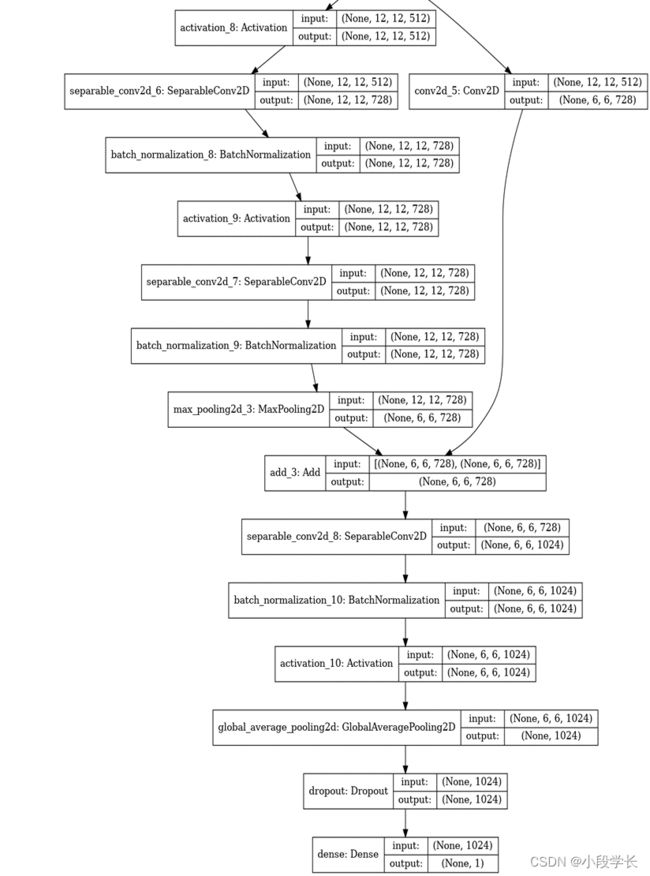
(1) 吸烟行为图像数据集的读取与预处理
import os
num_skipped = 0
# 通过字符串拼接获取每一个图像的路径
for folder_name in ("normal_images", "smoking_images"):
folder_path = os.path.join("../input/testtest/images", folder_name)
for fname in os.listdir(folder_path):
fpath = os.path.join(folder_path, fname)
# 过滤掉损坏的图像
try:
fobj = open(fpath, "rb")
is_jfif = tf.compat.as_bytes("JFIF") in fobj.peek(10)
finally:
fobj.close()
if not is_jfif:
num_skipped += 1
# Delete corrupted image
os.remove(fpath)
image_size = (180, 180)
batch_size = 32
# 使用image_dataset_from_sirectory获取数据集并转换为BatchDataset
train_ds = tf.keras.preprocessing.image_dataset_from_directory(
"../input/testtest/images",
validation_split=0.2,
subset="training",
seed=1337,
image_size=image_size,
batch_size=batch_size,
)
val_ds = tf.keras.preprocessing.image_dataset_from_directory(
"../input/testtest/images",
validation_split=0.2,
subset="validation",
seed=1337,
image_size=image_size,
batch_size=batch_size,
)
(2) 吸烟行为图像数据集上的深度学习模型实现
a)自构建模型
import matplotlib.pyplot as plt
# 将分好的数据集展示
plt.figure(figsize=(10, 10))
for images, labels in train_ds.take(1):
for i in range(9):
ax = plt.subplot(3, 3, i + 1)
plt.imshow(images[i].numpy().astype("uint8"))
plt.title(int(labels[i]))
plt.axis("off")
# 进行图像增强减缓过拟合
data_augmentation = keras.Sequential(
[
keras.layers.RandomFlip("horizontal"),
keras.layers.RandomRotation(0.1),
]
augmented_train_ds = train_ds.map(
lambda x, y: (data_augmentation(x, training=True), y))
train_ds = train_ds.prefetch(buffer_size=32)
val_ds = val_ds.prefetch(buffer_size=32)
# 构建卷积网络模型
def make_model(input_shape, num_classes):
inputs = keras.Input(shape=input_shape)
# Image augmentation block
x = data_augmentation(inputs)
# Entry block
x = layers.Rescaling(1.0 / 255)(x)
x = layers.Conv2D(32, 3, strides=2, padding="same")(x)
x = layers.BatchNormalization()(x)
x = layers.Activation("relu")(x)
x = layers.Conv2D(64, 3, padding="same")(x)
x = layers.BatchNormalization()(x)
x = layers.Activation("relu")(x)
previous_block_activation = x # Set aside residual
for size in [128, 256, 512, 728]:
x = layers.Activation("relu")(x)
x = layers.SeparableConv2D(size, 3, padding="same")(x)
x = layers.BatchNormalization()(x)
x = layers.Activation("relu")(x)
x = layers.SeparableConv2D(size, 3, padding="same")(x)
x = layers.BatchNormalization()(x)
x = layers.MaxPooling2D(3, strides=2, padding="same")(x)
# Project residual
residual = layers.Conv2D(size, 1, strides=2, padding="same")(
previous_block_activation
)
x = layers.add([x, residual]) # Add back residual
previous_block_activation = x # Set aside next residual
x = layers.SeparableConv2D(1024, 3, padding="same")(x)
x = layers.BatchNormalization()(x)
x = layers.Activation("relu")(x)
x = layers.GlobalAveragePooling2D()(x)
if num_classes == 2:
activation = "sigmoid"
units = 1
else:
activation = "softmax"
units = num_classes
x = layers.Dropout(0.5)(x)
outputs = layers.Dense(units, activation=activation)(x)
return keras.Model(inputs, outputs)
model = make_model(input_shape=image_size + (3,), num_classes=2)
keras.utils.plot_model(model, show_shapes=True)
# 训练模型
epochs = 50 #训练次数
callbacks = [
keras.callbacks.ModelCheckpoint("save_at_{epoch}.h5"),
]
model.compile(
optimizer=keras.optimizers.Adam(1e-3),
loss="binary_crossentropy",
metrics=["accuracy"],
)
model.fit(
train_ds,epochs=epochs,
callbacks=callbacks,validation_data=val_ds,
)
# 测试模型
img=keras.preprocessing.image.load_img("../input/testtest/images/smoking_images/106.jpg", target_size=image_size
)
img_array = keras.preprocessing.image.img_to_array(img)
img_array = tf.expand_dims(img_array, 0) # Create batch axis
predictions = model.predict(img_array)
score = predictions[0]
print("This image is %.2f percent not smoking and %.2f percent smoking."
% (100 * (1 - score), 100 * score)
)
b) LeNet
# coding=utf-8
from keras.models import Sequential
from keras.layers import Dense,Flatten
from keras.layers.convolutional import Conv2D,MaxPooling2D
from keras.utils.np_utils import to_categorical
import cPickle
import gzip
import numpy as np
seed = 7
np.random.seed(seed)
data = gzip.open(r'/media/wmy/document/BigData/kaggle/Digit Recognizer/mnist.pkl.gz')
train_set,valid_set,test_set = cPickle.load(data)
#train_x is [0,1]
train_x = train_set[0].reshape((-1,28,28,1))
train_y = to_categorical(train_set[1])
valid_x = valid_set[0].reshape((-1,28,28,1))
valid_y = to_categorical(valid_set[1])
test_x = test_set[0].reshape((-1,28,28,1))
test_y = to_categorical(test_set[1])
model = Sequential()
model.add(Conv2D(32,(5,5),strides=(1,1),input_shape=(28,28,1),padding='valid',activation='relu',kernel_initializer='uniform'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(64,(5,5),strides=(1,1),padding='valid',activation='relu',kernel_initializer='uniform'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Flatten())
model.add(Dense(100,activation='relu'))
model.add(Dense(10,activation='softmax'))
model.compile(optimizer='sgd',loss='categorical_crossentropy',metrics=['accuracy'])
model.summary()
model.fit(train_x,train_y,validation_data=(valid_x,valid_y),batch_size=20,epochs=20,verbose=2)
#[0.031825309940411217, 0.98979999780654904]
print model.evaluate(test_x,test_y,batch_size=20,verbose=2)
c) AlexNet
# coding=utf-8
# AlexNet
from keras.models import Sequential
from keras.layers import Dense,Flatten,Dropout
from keras.layers.convolutional import Conv2D,MaxPooling2D
from keras.utils.np_utils import to_categorical
import numpy as np
seed = 7
np.random.seed(seed)
model = Sequential()
model.add(Conv2D(96,(11,11),strides=(4,4),input_shape=(227,227,3),padding='valid',activation='relu',kernel_initializer='uniform'))
model.add(MaxPooling2D(pool_size=(3,3),strides=(2,2)))
model.add(Conv2D(256,(5,5),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(MaxPooling2D(pool_size=(3,3),strides=(2,2)))
model.add(Conv2D(384,(3,3),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(Conv2D(384,(3,3),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(Conv2D(256,(3,3),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(MaxPooling2D(pool_size=(3,3),strides=(2,2)))
model.add(Flatten())
model.add(Dense(4096,activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(4096,activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(1000,activation='softmax'))
model.compile(loss='categorical_crossentropy',optimizer='sgd',metrics=['accuracy'])
model.summary()
d) VGGNet
# coding=utf-8
# VGG
from keras.applications.vgg16 import VGG16, preprocess_input, decode_predictions
from keras.preprocessing.image import load_img, img_to_array
import numpy as np
# VGG-16 instance
model = VGG16(weights='imagenet', include_top=True)
image = load_img('D:\\desktop\\学习\\images\\normal_images\\1.jpg', target_size=(224, 224))
image_data = img_to_array(image)
# reshape it into the specific format
image_data = image_data.reshape((1,) + image_data.shape)
print(image_data.shape)
# prepare the image data for VGG
image_data = preprocess_input(image_data)
# using the pre-trained model to predict
prediction = model.predict(image_data)
# decode the prediction results
results = decode_predictions(prediction, top=3)
print(results)
e) GoogLeNet
#coding=utf-8
from keras.models import Model
from keras.layers import Input,Dense,Dropout,BatchNormalization,Conv2D,MaxPooling2D,AveragePooling2D,concatenate
from keras.layers.convolutional import Conv2D,MaxPooling2D,AveragePooling2D
import numpy as np
seed = 7
np.random.seed(seed)
def Conv2d_BN(x, nb_filter,kernel_size, padding='same',strides=(1,1),name=None):
if name is not None:
bn_name = name + '_bn'
conv_name = name + '_conv'
else:
bn_name = None
conv_name = None
x = Conv2D(nb_filter,kernel_size,padding=padding,strides=strides,activation='relu',
name=conv_name)(x)
x = BatchNormalization(axis=3,name=bn_name)(x)
return x
def Inception(x,nb_filter):
branch1x1 = Conv2d_BN(x,nb_filter,(1,1), padding='same',strides=(1,1),name=None)
branch3x3 = Conv2d_BN(x,nb_filter,(1,1), padding='same',strides=(1,1),name=None)
branch3x3 = Conv2d_BN(branch3x3,nb_filter,(3,3), padding='same',strides=(1,1),name=None)
branch5x5 = Conv2d_BN(x,nb_filter,(1,1), padding='same',strides=(1,1),name=None)
branch5x5 = Conv2d_BN(branch5x5,nb_filter,(1,1), padding='same',strides=(1,1),name=None)
branchpool = MaxPooling2D(pool_size=(3,3),strides=(1,1),padding='same')(x)
branchpool = Conv2d_BN(branchpool,nb_filter,(1,1),padding='same',strides=(1,1),name=None)
x = concatenate([branch1x1,branch3x3,branch5x5,branchpool],axis=3)
return x
inpt = Input(shape=(224,224,3))
#padding = 'same',填充为(步长-1)/2,还可以用ZeroPadding2D((3,3))
x = Conv2d_BN(inpt,64,(7,7),strides=(2,2),padding='same')
x = MaxPooling2D(pool_size=(3,3),strides=(2,2),padding='same')(x)
x = Conv2d_BN(x,192,(3,3),strides=(1,1),padding='same')
x = MaxPooling2D(pool_size=(3,3),strides=(2,2),padding='same')(x)
x = Inception(x,64)#256
x = Inception(x,120)#480
x = MaxPooling2D(pool_size=(3,3),strides=(2,2),padding='same')(x)
x = Inception(x,128)#512
x = Inception(x,128)
x = Inception(x,128)
x = Inception(x,132)#528
x = Inception(x,208)#832
x = MaxPooling2D(pool_size=(3,3),strides=(2,2),padding='same')(x)
x = Inception(x,208)
x = Inception(x,256)#1024
x = AveragePooling2D(pool_size=(7,7),strides=(7,7),padding='same')(x)
x = Dropout(0.4)(x)
x = Dense(1000,activation='relu')(x)
x = Dense(1000,activation='softmax')(x)
model = Model(inpt,x,name='inception')
model.compile(loss='categorical_crossentropy',optimizer='sgd',metrics=['accuracy'])
model.summary()
e) ResNet
#coding=utf-8
# ResNet-50
from keras.models import Model
from keras.layers import Input,Dense,BatchNormalization,Conv2D,MaxPooling2D,AveragePooling2D,
ZeroPadding2D
from keras.layers import add,Flatten
#from keras.layers.convolutional import Conv2D,MaxPooling2D,AveragePooling2D
from keras.optimizers import SGD
import numpy as np
seed = 7
np.random.seed(seed)
def Conv2d_BN(x, nb_filter,kernel_size, strides=(1,1), padding='same',name=None):
if name is not None:
bn_name = name + '_bn'
conv_name = name + '_conv'
else:
bn_name = None
conv_name = None
x = Conv2D(nb_filter,kernel_size,padding=padding,strides=strides,
activation='relu',name=conv_name)(x)
x = BatchNormalization(axis=3,name=bn_name)(x)
return x
def Conv_Block(inpt,nb_filter,kernel_size,strides=(1,1), with_conv_shortcut=False):
x = Conv2d_BN(inpt,nb_filter=nb_filter[0],kernel_size=(1,1),strides=strides,padding='same')
x = Conv2d_BN(x, nb_filter=nb_filter[1], kernel_size=(3,3), padding='same')
x = Conv2d_BN(x, nb_filter=nb_filter[2], kernel_size=(1,1), padding='same')
if with_conv_shortcut:
shortcut = Conv2d_BN(inpt,nb_filter=nb_filter[2],strides=strides,kernel_size=kernel_size)
x = add([x,short
x = add([x,shortcut])
return x
else:
x = add([x,inpt])
return x
inpt = Input(shape=(224,224,3))
x = ZeroPadding2D((3,3))(inpt)
x = Conv2d_BN(x,nb_filter=64,kernel_size=(7,7),strides=(2,2),padding='valid')
x = MaxPooling2D(pool_size=(3,3),strides=(2,2),padding='same')(x)
x = Conv_Block(x,nb_filter=[64,64,256],kernel_size=(3,3),strides=(1,1),with_conv_shortcut=True)
x = Conv_Block(x,nb_filter=[64,64,256],kernel_size=(3,3))
x = Conv_Block(x,nb_filter=[64,64,256],kernel_size=(3,3))
x = Conv_Block(x,nb_filter=[128,128,512],kernel_size=(3,3),strides=(2,2),with_conv_shortcut=True)
x = Conv_Block(x,nb_filter=[128,128,512],kernel_size=(3,3))
x = Conv_Block(x,nb_filter=[128,128,512],kernel_size=(3,3))
x = Conv_Block(x,nb_filter=[128,128,512],kernel_size=(3,3))
x = Conv_Block(x,nb_filter=[256,256,1024],kernel_size=(3,3),strides=(2,2),with_conv_shortcut=True)
x = Conv_Block(x,nb_filter=[256,256,1024],kernel_size=(3,3))
x = Conv_Block(x,nb_filter=[256,256,1024],kernel_size=(3,3))
x = Conv_Block(x,nb_filter=[256,256,1024],kernel_size=(3,3))
x = Conv_Block(x,nb_filter=[256,256,1024],kernel_size=(3,3))
x = Conv_Block(x,nb_filter=[256,256,1024],kernel_size=(3,3))
x = Conv_Block(x,nb_filter=[512,512,2048],kernel_size=(3,3),strides=(2,2),with_conv_shortcut=True)
x = Conv_Block(x,nb_filter=[512,512,2048],kernel_size=(3,3))
x = Conv_Block(x,nb_filter=[512,512,2048],kernel_size=(3,3))
x = AveragePooling2D(pool_size=(7,7))(x)
x = Flatten()(x)
结果与对比分析
最佳模型:VGGNet,从头到尾只有33卷积与22池化,简洁优美。
LetNet:LeNet网络很小,包含了深度学习的基本模块:卷积层、池化层、全连接层。LeNet共有七层,不包含输入,每层都包含可训练参数,每个层有多个Feature Map,每个Feature Map通过一种卷积滤波器提取输入的一种特征,然后每Feature Map有多个神经元;层与层之间的稀疏连接减少计算复杂度。
AlexNet:使用了Dropout,防止模型过拟合;使用最大池化替代了平均池化,避免平均池化的模糊效果;使用ReLU作为激活函数,前向计算简单,不容易发生梯度发散问题, 解决Sigmoid在网络较深时的梯度弥散问题,加快了训练速度;提出了LRN层,对局部神经元的活动创建竞争机制,使得其中响应比较大的值变得相对更大,并抑制其他反馈较小的神经元,增强了模型的泛化能力;使用CUDA加速深度卷积网络的训练,利用GPU强大的并行计算能力,处理神经网络训练时大量的矩阵运算。
VGGNet:在一定范围内,通过增加深度能有效地提升网络性能;与AlexNet对比,多个小卷积核比单个大卷积核性能好;尺度抖动scale jittering(多尺度训练,多尺度测试)有利于网络性能的提升;使用多个小卷积核33的卷积层代替大的卷积核,一方面可以减少参数,另一方面相当于进行了更多的非线性映射,增加了网络的拟合/表达能力;网络测试阶段将训练阶段的三个全连接替换为三个卷积,测试时重用训练时的参数,使得测试得到的全卷积网络因为没有全连接的限制,因而可以接受任意宽或高为输入;层数更深,VGG常用结构层数为16、19层(仅计算conv、fc层),而AlexNet为8层(5个conv,3个fc)。
GoogLeNet:GoogLeNet解决参数太多,如果训练数据集有限,很容易产生过拟合、网络越大、参数越多,计算复杂度越大,难以应用以及网络越深,容易出现梯度弥散问题(梯度越往后穿越容易消失),难以优化模型的问题。GoogLeNet采用了模块化的结构(Inception结构),方便增添和修改;采用了average pooling(平均池化)来代替全连接层,可以将准确率提高0.6%,在最后还是加了一个全连接层,主要是为了方便对输出进行灵活调整;做了模型融合,同时给网络增加了反向传播的梯度信号,也提供了额外的正则化
ResNet:ResNets解决深度神经网络的“退化”问题。ResNet具有超深的网络结构(可以突破1000层);提出risidual模块:使用了batch normalization加速训练(丢弃dropout);跨三层的ResNet先使用11的卷积降维,然后进行33的卷积之后,再用11的卷积升维,减少了参数数量,防止过拟合。ResNet网络结构的特性使得即使网络层数加深,也不会导致梯度消失或者梯度爆炸的现象(链式求导)。
出现的问题及解决方法
(1) Q:在原有python环境下安装tensorflow会出现包冲突问题
A:在anaconda新建虚拟环境
打开Anaconda Prompt,
输入:conda create --name tensorflow python=3.8,
激活环境:activate tensorflow
安装tensorflow:pip install tensorflow
在Jupyter notebook中添加虚拟环境:ipython kernel install --user --name tensorflow
(2) Q:使用Keras模块中的plot_model画出模型的结构图时,无法显示图
A:需要安装依赖包Pydot
结果分析与体会
社会和信息都在日益增长飞速发展,人们传递信息以及获取信息的重要手段就是图像的数据。近几年来,可使用各种电子设备拍照,使影像数字资源与日俱增。对于海量的图像数据,如何有效地对其进行分析和处理,并对其进行识别和分类,已成为计算机视觉领域的一个关键研究问题。自动从大数据中学习是深度学习的主要特征,而深度学习也将慢慢替代各种设计学习方法。优质的学习方法可以提高模式识别系统的性能,针对图像分类所面临的问题,采用主动学习的方法为分类模型选择有价值的样本,在保证分类精度之后再削弱使用标记样本的数量。主动且深度的学习能够有效削弱使用标记样本的数量,为图像分类提供一定的支撑。
图像分类问题的深度学习方法可以分为主动深度学习方法、多标签图像分类方法、多尺度网络图像分类方法。
标记图像的样本数量不容易获取,所以导致数量很少,没有标记的样本数量也会增多,因此深度学习可以有效提升样本的使用率。主动深度学习的方法根据采样策略来挑选合适的样本,并将这些被选中的样本增加到训练集中,通过迭代训练的方式来提升分类模型的使用效率。主动深度学习的重点在于抽样策略的设计,根据未标注样本的提供情况,可将抽样策略分为基于数据流的抽样和基于数据池的抽样。在数据流的采样中,按照所规定的标准对独立的数据进行选判。在基于数据池的抽样中,需要查询的样本数量较多,按照一定的准则对所有样本的重要性进行排序,选择最重要的样本。主动深度学习算法主要由以下几个部分组成:分类模型、抽样策略、标记训练样本集、未标记样本集等。深度学习过程分为两个过程:第一个过程是初始模型训练。对模型进行训练时使用初始标记样本集,从而获取分类模型的初始状态。第二个过程是抽样查询。在已标记样本集中,根据集合查询功能,选择信息量较大的未标记样本,根据实际类别对其进行标记。在查询抽样的整个过程里选择的未标记样本会影响分类模型的提升,因此抽样策略的设计是关键部分。
在图像分类领域较为著名的还有多标签图像分类方法。多标签图像分类方法的技术原理是基于语义空间注意力机制的LVILIC模型,建立像素块之间的关联度,以标签的方式加以分类,可简单理解为以多维度相似度为依据的分类方法。这种方法重点关注图像的特征区域,对输入图像建立标签,对比标签与特征区域典型标签的相关性,抑制或忽略与图像标签相关性弱或互斥的图像特征区域。该方法在图像数据的处理中,首先使用标签的静态统计信息构造标签相关性矩阵,为了关注标签的关联性,同步融入了标签语义之间的依赖关系,以此实现更为准确的描述标签间的相关性信息,将其作为建立的标签关性矩阵相关性信息的先验知识。以此为基础,在图卷积网络中生成标签语义词向量,将其与空间注意力机制相融合,构建以语义空间为专注点的机制模块。语义空间构成了该图像分类方法的算法核心,在语义空间中标签语义信息的引导下,对标签间相关性进行建模,实现对图像特征区域的识别与分类。在实际应用中,为了提高标签间语义词的关联度,采用同时使用训练集的标签静态统计信息配合以其他训练模型,例如基于BERT的预训练模型,共同确定图像语义空间向量,以适当的处理效率为代价实现标签间潜在关系关联的更高的准确性。
由于网络中的图像格式多种多样,像素分辨率千差万别,因此单纯的提取图像特征存在巨大的困难。在图像分类处理任务中,做到充分地提取输入图像、视频的特征是十分必要的,其程度直接影响到模型的分类效果。在深度卷积神经网络中,位于浅层的图像特征存在分辨率够高但抽象能力不强;而处于深层的图像特征则是分辨率偏低但抽象能力强。为综合两种情况的利弊,采用多尺度网络图像分类的方法进行处理。多尺度网络针对输入图像的层级,采用提升分辨率或降低分辨率的操作模式,提取图像的特征,将其作为分类的依据。降低分辨率操作是通过一系列卷积操作和池化操作实现的,与输入图像特征相比较,输出的图像特征分辨率被降低,但具有了更高的抽象能力;提升分辨率操作是通过邻近插值、双线性插值、转置卷积、上池化、亚像数卷积来实现的,与输入图像特征相比较,输出的图像特征分辨率更高。通过尺度的分辨率调整,目的是得到期望的图像分辨率和足够的抽象能力,实现图像的分类。在此方法中多次提高和降低分辨率操作,可以提高模型的性能,达到更佳的图像分类效果。
自主深度学习、多标签图像分类和多尺度图像分类方法从不同的角度提出图像分类问题的解决模型,由于其面向的主要问题和解决思路的不同,在各自领域具有独到的优势。
近年来,深度学习策略的发展在各个领域都有着长足的进步。特别是卷积神经网络在计算机图像分类问题上取得了异常显著的成就。卷积神经网络长期以来是图像识别领域的核心算法之一,并在学习数据充足时有稳定的表现。对于一般的大规模图像分类问题,卷积神经网络可用于构建阶层分类器,也可以在精细分类识别中用于提取图像的判别特征以供其它分类器进行学习。对于后者,特征提取可以人为地将图像的不同部分分别输入卷积神经网络,也可以由卷积神经网络通过非监督学习自行提取。对于字符检测和字符识别/光学字符读取,卷积神经网络被用于判断输入的图像是否包含字符,并从中剪取有效的字符片断。其中使用多个归一化指数函数直接分类的卷积神经网络被用于谷歌街景图像的门牌号识别、包含条件随机场图模型的卷积神经网络可以识别图像中的单词,卷积神经网络与循环神经网络相结合可以分别从图像中提取字符特征和进行序列标注。
卷积神经网络(CNN)是一种用于图像识别和处理的人工神经网络(ANN),专门用于处理数据(像素)。一个神经网络由几个相互连接的节点构成,称为 “神经元”。神经元分为输入层、隐藏层和输出层。输入层对应于我们的预测器/特征,输出层对应于我们的响应变量。具有输入层、一个或多个隐藏层和一个输出层的神经网络称为多层感知器 (MLP)。 MLP 是Frank Rosenblatt在 1957 年发明的。下面给出的 MLP 有 5 个输入节点、5 个带有两个隐藏层的隐藏节点和一个输出节点。神经网络是如何工作的?输入层神经元接收来自数据的传入信息,它们处理并分配给隐藏层。该信息依次经过隐藏层处理,并传递给输出神经元。该人工神经网络 (ANN) 中的信息根据一个激活函数进行处理。这个函数实际上模仿了大脑神经元。每个神经元包含一个激活函数值和一个阈值。阈值是输入必须具有的最小值才能被激活。神经元的任务是对所有输入信号进行加权求和,并对总和应用激活函数,然后再将其传递到下一个(隐藏或输出)层。还需要一些激活函数来将非线性引入网络。应用激活函数并将该输出传递到下一层。可能的函数有:Sigmoid 函数、双曲正切、ReLU函数、softmax 函数等。获得一张图片后,首先以数组的形式将图像的像素馈送到神经网络(用于对此类事物进行分类的 MLP 网络)的输入层。隐藏层通过执行各种计算和操作来进行特征提取。有多个隐藏层,如卷积、ReLU 和从图像中执行特征提取的池化层。最后,将可以看到一个全连接层,它可以识别图像中的确切对象。除此之外,卷积运算涉及矩阵算术运算,每个图像都以值(像素)数组的形式表示。在卷积运算中,数组逐个元素地相乘,乘积被分组或求和以创建一个表示ab的新数组。矩阵a的前三个元素现在乘以矩阵b的元素。乘积相加得到结果并存储在一个新的ab数组中这个过程一直持续到操作完成。在卷积之后,还有一个称为池化的操作。因此,在这个链中,卷积和池化依次应用于数据以从数据中提取一些特征。在连续的卷积层和池化层之后,数据被展平成一个前馈神经网络,也称为多层感知器。
利用卷积神经网络对吸引行为进行分类,有助于对人体健康发展起到间接促进作用。人在吸烟时香烟中的一氧化碳极易与人体血液中的血红蛋白相结合,这样就会影响血红蛋白与体内氧气的结合,从而引起人体中各个组织器官缺氧,严重影响身体机能的正常运行。如今,随着互联网行业的飞速发展,各行各业都开始研发智能化设备来为自身行业的发展提供新动力。而传统的检测方法需要人工参与进行判断分析,并且多数情况下是用于事后取证,不能实时的对公民吸烟行为进行检测并报警,所以传统的方法正逐渐被现在的技术所淘汰。而现如今的人工智能技术被人们广泛应用于生产生活的各行各业,利用智能视频监控系统对公民的行为进行实时监控逐渐成为今后公共环境的一种发展趋势。将计算机视觉技术应用到监控系统所获取的图像或者视频数据上,通过分析判断所获取的数据来实现智能监控的目的,实时的对人类行为进行检测。目前,对吸烟行为检测的方法和手段有的通过识别香烟的烟雾来进行检测,有的通过对吸烟者的吸烟手势和动作来进行检测,也有的是将两种方法结合起来进行综合判断检测。由于上述属性和特征不易获取、不易判断,导致误判率较高,算法识别的准确率难以提高。为解决上述存在的问题,也可以对吸烟行为的识别检测进行研究,就是将香烟作为目标进行识别,通过检测人类面部图像中是否有香烟这个物体来判断是否在行车过程中存在吸烟行为。
欢迎大家加我微信交流讨论(请备注csdn上添加)
