DirectX 11发布带来了很多令人兴奋的新特性,其中使用Computer Shader进行图形后处理和多线程渲染、乱序透明等功能都是以前的GPU硬件从未想过从未做过的。这些功能标识着GPU的发展结束了一位增强性能来获取更大浮点吞吐以适应增长的三角形数量和更复杂的Shader指令,而是转向使用使用先进渲染技术结合GPU通用计算来实现复杂特效。

回顾历次DirectX的更替过程,几乎都对GPU架构产生了颠覆性的影响,它们大部分要求GPU改变现有的着色器Shader单元结构,或者为着色器Shader单元追加资源,这些改进都是为了让GPU的指令数提升,寄存器数量增加,纹理规模提升,材质Texture精度提升。这样的改进难免带来晶体管数量的增长,也就说说GPU内部的每个着色器Shader单元变得更加庞大。

本次DirectX 11升级,我们看到以下特性是非常值得关注的:
● 着色器版本提升到Shader Model 5.0,采用面向对象的概念,并且完全可以支持双精度数据。
● Tessellation曲面细分技术获得微软正式支持,逐渐走向成熟;
● Multithreading多线程处理,让图形处理面对多线程编程环境不再尴尬;
● 提出微软自己的Compute Shader通用计算概念,把GPU通用计算推向新的巅峰;
● 新的Texture Compression纹理压缩方案,在画质损失极小的环境下带来了硬件资源的节约。
虽然超线程概念已经在CPU领域发展了数十年,但大多数程序员还是直到近年来多核心CPU流行之后才开始关心程序的平行化,在此之前大部分通用代码都是简单的单线程,在这些代码里寻找并挖掘多线程化带来的性能提升是非常困难的。
为了改变这一现状,DirectX 11特性还包括很重要一点:支持多线程(multi-threading)。没错,无论是DirectX 10还是DirectX 11,所有的色彩信息最终都将被光栅化并显示在电脑显示屏上(无论是通过线性的方式还是同步的),但是DirectX 11新增了对多线程技术的支持。

从DirectX 10到DirectX 11的多线程变化
得益于此,应用程序可以同步创造有用资源或者管理状态,并从所有专用线程中发送提取命令,这样做无疑效率更高。DX11的这种多线程技术可能并不能加速绘图的子系统(特别是当我们的GPU资源受限时),但是这样却可以提升线程启动游戏的效率,并且可以利用台式CPU核心数量不断提高所带来的潜力。
多线程渲染示意图1
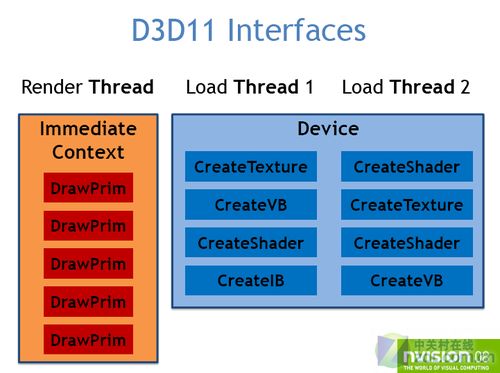
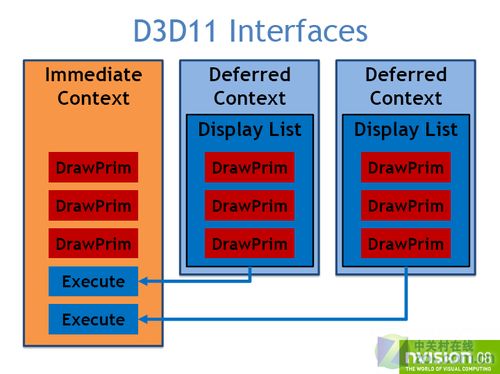
在DirectX 11中,微软通过将目前单一执行的Direct 3D设备被分为三个独立的接口:设备(Device)、立即执行范畴(immediate Context)和延迟执行范畴(Deferred Context)。
多线程渲染示意图2
这三者都被分发到各自独立的线程,而且设备和Deferred context还可以分配多个线程,负责将等待执行的任务发送给immediate Context或渲染线程。这样的设计可以将图形生成所需的资源做预先的存取。同时,CPU还可以利用显卡的多线程处理加快DirectX的处理,减少CPU的响应时间而使游戏不再受到CPU的瓶颈限制。
微软在DirectX 11引入了DirectX Compute概念,实际上这个概念在以前就存在不少应用。DirectX Compute在通用计算领域的增强,进一步提升了GPU通用计算的动能。OpenCL是GPU通用计算的API标准,它提供了并行计算API和一个扩展的编程语言,DirectX Compute增强了GPU通用性能,但由于重点不同,它与OpenCL完全不是竞争关系,反而进一步增强了OpenCL的实用性——DirectX 11提升GPU通用性能,基于OpenCL的通用计算程序将更富效率。
DirectX Compute概念包括了我们下面即将介绍的Compute Shader技术,实际上我们可以理解为它们是一种技术,两种称谓方式。所以下文我们直接称呼这种让GPU通用计算来辅助图形处理的技术为Compute Shader技术。
GPU是图形处理器,以往的GPU通用计算需要程序员先将资料伪装成GPU可识别的图像,再将GPU输出的图像转换为想要的结果,而通过DX11中的Compute Shader通用计算,任意类型的数据(即使是非图形数据)都可以直接进行计算,而且不受图形渲染流程的束缚,可以随时写入写出,GPU通用计算的效能提高了很多。
由于GPU的浮点运算能力非常强大,支持GPU进行通用计算的技术发展势头很快,NVIDIA和AMD分别有CUDA和Stream技术,以前两家是各自为战,如今微软也看到了GPU通用计算的曙光,在DX11中加入了Compute Shader这一技术,意在统一当前的通用计算技术。你可以认为Compute Shader标准就是微软提出的OPEN CL。
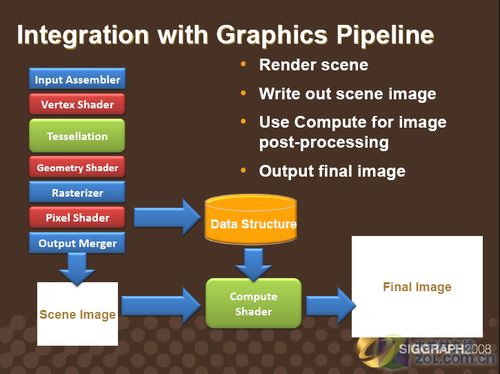
Compute Shader图形流水线
Compute Shader主要特性包括线程间数据通信、一整套随机访问和流式I/O操作基本单元等,能加快和简化图像和后期处理效果等已有技术,也为DX11级硬件的新技术做好了准备,对于游戏和应用程序开发有着很重大的意义。
在DirectX 11以及CS的帮助下,游戏开发者便可以越过复杂的数据结构,并在这些数据结构中运行更多的通用算法。与其他完整的可编程的DX10和DX11管线阶段一样,CS将会共享一套物质资源(也就是着色处理器)。
Compute Shader可发挥的地方很多,游戏中可以使用GPU进行光线追踪、A-Buffer采样抗锯齿、物理特效、人工智能AI等游戏特效运算。在游戏之外,程序员也可以利用CS架构进行图像处理、后期处理(Post Process)等。
Compute Shader技术是微软DirectX 11 API新加入的特性,在Compute Shader的帮助下,程序员可直接将GPU作为并行处理器加以利用,GPU将不仅具有3D渲染能力,也具有其他的运算能力,也就是我们说的GPGPU的概念和物理加速运算。

Computer Shader在图形计算中发挥重要作用
在上图中,图一表示了Compute Shader做图像后处理(Post Process),图片是《地铁2033》的游戏截图,利用Compute Shader技术做景深处理可以得到更好的效率。图二表示利用Compute Shader技术做IA人工智能。图三表示CUDA或者未来的Compute Shader结合OptiX技术做光线追踪。图四表示SPH流体模拟,流体的模拟,是典型的通用计算应用实例,对Shader性能要求较高。
用更加通俗易懂的话来解释,Compute Shader技术实际上就是一道把GPU通用计算和传统图形处理沟通起来的桥梁。未来更多的特性特效将通过GPU通用计算来实现。借助这一技术GPU中的流处理器单元可以变为类似CPU的计算中心,处理一系列如后期渲染、图像质量增强、高质量阴影过滤、景深效果以及高级环境光遮蔽效果。
Computer Shader的初衷,就是使用通用计算的手段来进行后处理。由于GPU的浮点运算能力非常强大,支持GPU进行通用计算的技术发展势头很快,NVIDIA和AMD分别有CUDA和Stream技术,以前两家是各自为战,如今微软也看到了GPU通用计算的曙光,在DX11中加入了Compute Shader这一技术,意在统一当前的通用计算技术。你可以认为Compute Shader标准就是微软提出的OPEN CL。
景深是人眼视觉系统中成像的重要特征。人眼对现实世界成像时,自动调节焦距以适应不同的取景距离,眼睛注视的物体便处于聚焦平面(focus plane)上,因此清晰成像于视网膜;而处于聚焦平面之外的物体,成像便模糊不清。透镜(瞳孔)的焦距、直径,以及物距共同决定了物体成像时的模糊程度。从Shader Model 2.0标准开始,景深处理已经能够被GPU硬件执行了,而进入DirectX 11时代这种执行效率在Compute Shader技术支持下得到了迅猛提升。
以往的虚拟现实系统中,几乎都未引入景深效果,整个场景成像后都是清晰的,这样,整个场景则显得不够真实、自然,并且缺少景深所带的深度暗示。加人景深效果,有助于立体照片的合成以及缓解虚拟现实系统中常有的眼睛疲劳,增强场景的真实感、沉浸感。

使命召唤4游戏封面
CS技术原则上可以处理一切效果。不过现在用得最多的,大体上是DOF(Depth of Field),也就是景深效果。HDR(High-Dynamic Range)高动态光照渲染目前已经不需要CS技术来实现,但是用CS技术来实现这些效果还是非常划算的。景深主要适合于第一人称视角游戏(First-person games)如使命召唤等游戏,景深效果可以让玩家沉浸在富于电影级别特效体验的游戏中,高效处理景深将成为实现真实游戏特效的重要环节。
Compute Shader可发挥的地方很多,游戏中可以使用GPU进行光线追踪、A-Buffer采样抗锯齿、物理特效、人工智能AI等游戏特效运算。在游戏之外,程序员也可以利用CS架构进行图像处理、后处理(Post Process)等。


发布DX11显卡之后不久AMD放出了一个名为ladybug的DX11 Demo,其中就有Depth of Field效果的演示。

在硬件支持Compute Shader之后,相应的硬件必须要比当代硬件更加灵活,因为在运行CS代码的时候,硬件必须支持随机读写、不规则列阵(而不是简单的流体或者固定大小的2D列阵)、多重输出、可根据程序员的需要直接调用个别或多个线程、32k大小的共享寄存空间和线程组管理系统、粒数据指令集、同步建构以及可执行无序IO运算的能力。
同时借助Direct Compute技术,DirectX 11可以实现次序无关透明。即物体不管以任何顺序进行摆放,GPU都能按照正确的前后关系计算透明。这个特性完全模拟了真实世界的透明行为。OIT次序无关透明使用了 Direct Compute 中的原子操作和 append buffer,在 GPU 内部完成 per-pixel fragment lists 和 sort,性能和精度都比传统的 alpha blending 有很大的提升。

简单的Alpha透明,效果显得杂乱无章;OIT透明,物体轮廓骨架显得非常清晰
上图所展示的Mecha主要是展示的OIT(order-independent transparency透明顺序排序)技术。以往的DirectX中对于透明物体的叠加处理是非常复杂的,因为透明物体的层次关系相当复杂,特别是烟雾、火、水、玻璃等等东西混合在一起的时候,程序很难判定物体的层次顺序。
这些以前都依赖程序员的手工指定,并且有些透明物体像烟雾、火焰等等这些透明的物体没有严格形状模型,并且变化相当迅速,处理这些透明物体会消耗程序员和GPU相当大的精力和性能。

微软在DirectX 11中引入了OIT技术来实现多个透明物体的快速混合,通过OIT技术可以很好的应付多重乱序透明处理,从而实现实现透明物体的快速正确排序。
实际上OIT技术是DirectCompute11中的一部分,OIT的对透明物体排序的实现都是通过DirectCompute11来实现的,并且实现起来非常简单。另外,在OIT中微软首次提到了使用原子操作,至于原子操作的具体意义对于非图形编程人员就不需要了解了,另外微软还提到OIT还提供了单独的缓存来提高处理透明物体的排序。
OIT效果的运算方面,原则上是可以通过流处理器单元来独立实现的。但是DirectX 11中定义OIT效果需要原子操作。基本上,DirectX 11新引入的几种特效中,除了曲面细分之外其他的都走得Compute Shader技术和原子操作。微软的说明里OIT是走CS5.0路径的,也就是说原子操作性能将大幅度影响到OIT效果的最终表现。
事实上很多测试结果也说明OIT效果确实可以从存储系统尤其是cache的优化中得到显著的好处,原子操作是很依赖Cache和Shared Memory。如果是传统手段实现的话,肯定是一层一层的贴图,像这种顺序比对忽略的操作肯定是要一来原子操作+数列和归约的。原子操作跟内存控制一样,必须通过固定单元来实现,Shader只是运算器,不能达成控制功能。