<<视觉问答>>2021:Zero-shot Visual Question Answering usingKnowledge Graph

目录
摘要:
一、介绍
二、相关工作
2.1、Visual Question Answering
2.2、Zero-shot VQA
三、Preliminaries
四、Methodology
4.1 Main Idea
4.2 Establishment of Multiple Feature Spaces
4.3 Answer Mask via Knowledge
五、实验
5.1 Datasets and Metrics
5.2 Implementation Details
5.3 Overall Results
5.4 Ablation Studies
5.5 Interpretability
六、Conclusion
摘要:
视觉问答引入外部知识可以增强模型泛化的能力,现有的方法大多是pipeline形式的,包括知识匹配、特征提取、特征学习等各个模块的组合,而模型的上限仅取决于上限最低的模块。此外,大多数方法也忽略了答案偏差的问题,即有些答案类别在训练集里从未出现。为了缓解这些问题,作者提出zero-shot VQA,基于知识图谱(训练阶段)和掩码机制(预测阶段)更好的融合外部知识,此外,针对F-VQA数据集提出了新的基于答案的zero-shot VQA数据集。实验证明在这两个数据集上,作者的方法均取得了最好的效果。
一、介绍
视觉问答是指根据给定的图像和问题来回答这个问题的答案。然而,目前大多数方法仍无法解决开放世界场景理解的问题,即答案没有显示的包含在图像里,而是需要依赖外部知识作答。考虑问题Q1:你会和谁玩这个游戏?一些额外的知识是必不可少的,因为答案dog并不能从图像中得到,只能通过外部知识得知是和dog玩这个游戏。

一些VQA方法利用外部知识来理解开放世界场景的问题。XXX利用网络上的非结构化文本信息作为外部知识,但无法解决文本中的噪声信息。XXX首先从图像提取视觉概念信息(如,桌子,椅子)与外部知识图谱连接组合,从而将视觉问答转换为对知识图谱的查询,以检索答案。XXX通过整合视觉概念之间的空间关系和描述性语义关系,以及知识图谱中的支持事实,构建多模态异构图,应用模态感知图卷积网络来推理答案。然而如果这些模型的某一个模块效果不行,势必会影响整个模型的性能。虽然已经提出了一些端到端模型,以避免错误的模块级联,但这些模型仍然是相当初步的,尤其是在利用外部知识方面,在许多VQA任务上的性能比pipeline方法差。
VQA另一个重要问题是对标记的数据集的依赖性,即每个样本均由图像、问题、答案组成,用这样的数据集训练出的模型也仅仅只能推理出训练集已经呈现出的答案类别。然而,对于新类型的问题和答案,以及图像中出现的新的对象,仍需要重新收集标记数据样本并重新训练模型。对于这种局限,zero-shot VQA被提出,旨在预测训练样本中从未出现过的对象。然而,目前的zero-shot VQA方法仍然专注于封闭世界场景的理解,而不考虑看不见的答案类别,很少充分利用知识图谱。在本文中,作者利用知识图谱研究了开放世界场景理解的VQA,这需要外部知识来回答问题,以及ZS-VQA,来预测新的答案类别。
在本文中,作者提出了一个使用KG(知识图谱)和基于掩码的学习机制的ZS-VQA算法,同时提出了一个新的ZS-F-VQA数据集,该数据集用于评估ZS-VQA的未知的答案。首先,作者分别训练学习三种不同的特征映射空间,即关于关系的语义空间、关于支持实体的对象空间和关于答案的知识空间,每一个都用于将图像问题对的联合表征与相应的目标对齐。
语义空间:图像问题的联合表征与关系(is a、belong to等等)对齐,余弦损失。
对象空间:图像问题的联合表征与对象(car、chair等等)对齐,余弦损失。
知识空间:图像问题的联合表征与答案(真实答案类别)对齐,余弦损失。
预测阶段通过所有选择的实体和关系之间的组合,根据包含事实的KG中所有三元组的映射表确定mask,该映射表指导未知答案类别预测的对齐过程。根据VQA任务,mask可以用作hard mask或soft mask。hard mask用于ZS-VQA任务,使用ZS-F-VQA数据集。soft mask用于标准VQA任务,使用F-VQA数据集。综上所述,主要贡献总结如下:
a、提出了一种使用KG的鲁棒ZS-VQA算法,该算法基于实体/关系和两个特征空间中的图像问题对与相应目标对齐,预测时通过masking调整答案预测分数。
b、定义了一个新的ZS-VQA问题,该问题需要外部知识并考虑看不见的答案、训练集不存在的答案。因此,作者开发了ZS-F-VQA数据集。
c、基于KG的ZS-VQA算法非常灵活。它可以成功地处理依赖外部知识的常规VQA任务和ZS-VQA任务,并可直接用于扩充现有的端到端模型。
二、相关工作
2.1、Visual Question Answering
Traditional VQA Methods. 没什么好说的。
Knowledge-based VQA. 利用符号化的知识是增强VQA的直接解决方案。为了研究将外部知识与VQA结合起来,出现了F-VQA、OK-VQA和KVQA等数据集。F-VQA中的每个问题都涉及到相关KG概念网络中的一个特定事实。而OK-VQA是手动标记的,没有指导KG作为参考。KVQA的目标是世界知识,其中的问题是关于特征之间的关系。
与当前方法不同,作者提出的框架利用了端到端和pipeline方法的优点。提高了模型的可移植性,同时有效地避免了错误级联(如图5所示),实现了良好的性能。
2.2、Zero-shot VQA
机器学习的数据集通常所有的预测类别都有训练的样本。然而,总是通过标记足够多的样本来重新训练模型以适应新的类别是不切实际的。针对这一限制,zero-shot learning被提出在没有相关训练样本的情况下处理这些新的类别。XXX首先提出了ZS-VQA,并在语言语义方面引入了新概念,如果测试样本的问题或答案中至少有一个新单词,则该测试样本被视为不可见的。XXX通过使用非结构化外部数据(从视觉和语义层面)进行预训练,将先验知识纳入模型。XXX将ZS-VQA重新表述为一项转移学习任务,该任务应用密切可见的I-Q对对不可见的概念进行推理。这些方法的主要限制是,它们很少考虑不平衡和低资源问题的答案本身。开放式答案的VQA要求模型从固定K个答案类别中选择概率最高的答案,但该模型无法处理k个类别之外的答案,因为答案是孤立的,没有特定意义。此外,VQA被定义为一个没有充分利用答案语义信息的分类问题。一些方法试图通过特征表示将答案与I-Q联合表征对齐,以实现看不见的答案预测,或者简单地将其特征表示拼接输入MLP以预测答案。然而,他们都无法回答那些需要外部知识的I-Q对,而且在外部信息不足的情况下,答案之间的相关性仍然不够强。本文提出的ZS-VQA方法利用KG融合了更丰富、更相关的知识,充分利用了现有的常识,并给出了更准确的答案。
三、Preliminaries
VQA and Zero-shot VQA. VQA数据集可表示为 ![]() ,I,Q,A分别表示图像集、问题集和答案集,训练集为
,I,Q,A分别表示图像集、问题集和答案集,训练集为![]() ,测试集为
,测试集为![]() ,两者的答案集相同。作者定义
,两者的答案集相同。作者定义![]() 和
和![]() ,其中
,其中![]() 和
和![]() 表示看得见和看不见的答案集,交集为空。ZS-VQA比普通VQA困难得多,因为图像和问题中的信息不足以回答训练样本中从未出现过的答案。具体来说,作者研究了ZS-VQA测试阶段的两种设置:一种是标准ZSL,其中测试样本(i,q,a)的候选答案是Au,另一种是广义ZSL(GZSL),使用完整的答案集(
表示看得见和看不见的答案集,交集为空。ZS-VQA比普通VQA困难得多,因为图像和问题中的信息不足以回答训练样本中从未出现过的答案。具体来说,作者研究了ZS-VQA测试阶段的两种设置:一种是标准ZSL,其中测试样本(i,q,a)的候选答案是Au,另一种是广义ZSL(GZSL),使用完整的答案集(![]() 和
和![]() 的并集)。需要注意的是,常规VQA只预测看到的答案,而GZSL设置下的VQA则预测看到和看不到的答案。
的并集)。需要注意的是,常规VQA只预测看到的答案,而GZSL设置下的VQA则预测看到和看不到的答案。
Knowledge Graph (KG). KG已广泛应用于知识表示和知识管理。作者使用的KG是三个KG(DBpedia、ConceptNet、WebChild)的子集(以RDF7三元组的形式),即(头实体,关系,尾实体),它用于建立先验知识连接。
以图1为例,根据答案来源,所有(i,q)对可以分为两类:(1)图片和问题之外的答案。例如,问题“Q1:通常你和谁玩这个游戏?”的答案是“dog”,这里答案的数据源是外部KG,其中包含用于QA支持的三元组
四、Methodology
4.1 Main Idea
作者的主要想法是基于当前基于知识的VQA方法中的两个缺陷。首先,在这些方法中,通常会建立一个中间模型,并以pipeline方式涉及KG查询,这导致错误级联和泛化能力差。其次,大多数研究将VQA定义为一个分类问题,该问题没有充分利用答案的信息,无法预测看不见的答案类别,也无法在候选答案几乎没有重叠或没有重叠的数据集之间传输。例如,如图1所示,如果“飞盘”概念没有出现在训练集中,传统的VQA将无法在词汇表外(OOV)问题的测试阶段识别它。
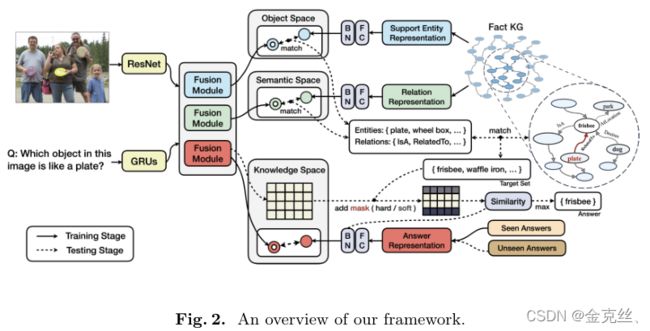
通过使用语义嵌入特征作为答案的表征,我们将VQA从分类任务转换为映射任务。经过参数学习后,问题与图像的联合嵌入分布可以部分接近包含shadow knowledge的答案的分布,意思就是图像问题对的表征和正确的答案表征的具有很高的相似度,从而映射到的正确的答案类别,称之为关于答案的知识空间。此外,我们还独立定义了另外两个特征空间:关于关系的语义空间和关于支持实体的对象空间。语义空间的目标是根据三元组中的语义信息将(i,q)融合特征投影到一个关系中,而对象空间的目标是在(i,q)和实体之间建立相关连接,跟知识空间一样,语义空间由图像问题对映射到某个关系类别,对象空间由图像问题对映射到某个对象类别。当它们结合在一起时,就起到了回答指导预测的作用(详见第4.2节)。为了克服第2.1节中提出的限制,我们在这种情况下提出了soft/hard mask方法,以有效地增强对齐过程,同时缓解错误级联。
4.2 Establishment of Multiple Feature Spaces
我们通过将答案和对应的(i,q)对投影到公共特征空间并彼此接近,来建立答案和对应(i,q)对之间的联系。首先,提取q和i之间的多模态融合信息,同时,我们将Gφ(a)定义为答案a的表示形式。我们遵循相容性概率模型(PMC),其实就是用的余弦相似度,类似于softmax,最相似的那个就是映射到的类别,并添加loss temperature τ以更好地优化:

其中,当设置为标准ZSL时,A表示Au,否则保持不变,a表示(in,qn)的正确答案。为了学习参数以最大化整个PMC模型中的可能性,我们采用以下损失函数:
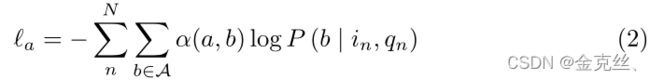
其中,加权函数![]() 衡量预测答案b对目标函数的贡献程度。自然设计是
衡量预测答案b对目标函数的贡献程度。自然设计是![]() ,其中
,其中![]() 表示二值指示函数,如果条件为真,则取1,否则取0。在测试过程中,给定已知的图像问题表征和答案表征,我们可以应用以下决策规则来预测(i,q)对的答案
表示二值指示函数,如果条件为真,则取1,否则取0。在测试过程中,给定已知的图像问题表征和答案表征,我们可以应用以下决策规则来预测(i,q)对的答案 :
:

与第5.3节所示的结果一样,上述特征投影过程可以学习VQA中需要外部知识的浅层知识。然而,由于网络不足以用少量的训练数据对丰富的先验知识进行建模(见表1中的数据统计),它的性能并不好。以显式或隐式的方式将图像或问题中的元素与KG实体匹配,可以用知识增强模型,从而很好地解决开放世界场景理解问题(参见图1示例中的连接)。在我们的方法中,图像问题和KG之间的对齐是由多个特征空间隐式完成的,我们利用另外两个功能空间来修改答案:
1)语义空间:侧重于(i,q)中的语言信息,它是三重关系r在KG中的投影的指导。特别是,在这一部分中,q的信息比i更重要。
2)对象空间: 与传统的图像分类识别给定图像的正确类别相比,对象空间是一个支持实体分类器的特征空间,同时观察图像和文本的显著特征。具体来说,支持实体的嵌入表征和(i,q)联合嵌入表征之间的对齐避免了复杂知识的直接学习,同时与语义空间中获得的预测关系一起作用于后续的答案mask过程。
4.3 Answer Mask via Knowledge
为了提高机器对文本的理解,mask被广泛应用于语言模型预训练中。如mask训练语料库中的部分单词(例如BERT)和mask常识概念(例如AMS)。但他们很少考虑知识在预测结果中的直接约束,忽视了人在现有先验知识的指导下如何做出合理的决策。与所有这些方法不同,我们提出了一种VQA的答案mask策略。
训练学习到的两个特征空间,分别表示图像问题对到关系的映射和图像问题对到对象实体的映射。给定一个图像问题对,![]() 表示图像问题对和关系的相似度,
表示图像问题对和关系的相似度,![]() 表示图像问题对和实体的相似度。对应于top-k个相似度值的e和r分别构成候选集
表示图像问题对和实体的相似度。对应于top-k个相似度值的e和r分别构成候选集![]() 和
和 ,其中k表示kr和ke,然后整合目标集
,其中k表示kr和ke,然后整合目标集![]() ,如下所示:
,如下所示:
![]()
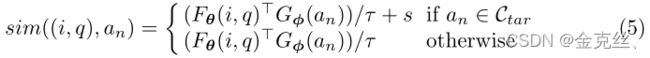
其中s代表masking得分,这是hard mask和soft mask的主要区别(详见第5.4节)。Soft score大大减少了pipeline方法在整个模型中引起的误差级联,这将在第5.5节中讨论。同时,如第5.3节所示,hard mask的重要性来自其在ZSL设置中的优越性能。对(i,q)对的预测答案ˆa被确定为:
![]()
需要注意的是,由于hard mask的存在,候选目标不能仅仅被视为候选答案,soft mask修正了答案概率,而不是简单地限制了答案的范围。此外,如第5.4节和第5.4节所述,上述k和s是超参数,可对结果产生各种影响。
五、实验
5.1 Datasets and Metrics
F-VQA. ZS-F-VQA. 评估指标详见原文,

5.2 Implementation Details
Fusion Model. SAN融合图像问题对,MLP编码目标,不同的特征空间的目标也不一样。
Visual Features. 在ImageNet上预训练的ResNet-152(14×14×2048张量)。
Text Features. GLOVE+LSTM
实验超参数设置详见原文。
5.3 Overall Results
源码中config文件里,top_rel参数即为表二三的kr,top_fact参数即为表二三的ke。


5.4 Ablation Studies
5.5 Interpretability
六、Conclusion
我们通过知识图谱提出了一个Zero-shot VQA模型,以解决利用外部知识进行Zero-shot VQA的问题。我们的方法成功的关键因素是考虑知识本身包含的知识和外部常识知识的知识图表。同时,我们将VQA从传统的分类任务转换为基于映射的对齐任务,以解决看不见的答案预测问题。在多个模型上的实验支持了我们的观点,即该方法不仅可以在Zero-shot场景中获得优异的性能,而且在一般VQA任务的不同端到端模型上也可以取得稳定的进展。接下来,我们将进一步研究KG构造和KG嵌入方法,以获得更健壮但紧凑的语义,从而解决ZS-VQA问题。。