2021:How Much Can CLIP Benefit Vision-and-Language Tasks?
摘要
大多现有的视觉和语言模型依赖预训练过的视觉编码器,使用一组相对较小的人工注释的数据来感知视觉世界,然而,我们观察到,大规模的预训练通常得到更好的泛化性能,如,CLIP(对比语言-图像预训练),在大量的图像标注对上训练,在各种视觉任务上显示出强大的零样本性能。为进一步研究CLIP带来的优势,我们建议在两种典型的场景下,在各种视觉和语言模型上使用CLIP作为视觉编码器:(1)将CLIP插入到特定于任务的微调中;(2)将CLIP与V&L预训练相结合,并转移到下游任务中。发现,CLIP显著优于广泛使用的用领域内的注释数据的视觉编码器,如BottomUp-TopDown。我们在不同V&L任务上取得了有竞争力或更好的结果,同时在视觉问答、视觉暗示和V&L导航任务上取得了最先进的结果。
一、介绍
大多数V&L模型依赖于视觉编码器来感知视觉世界,将原始像素转换为来自表示空间的向量。最近的研究观察到视觉表示已经成为V&L模型的性能瓶颈,并强调学习强大的视觉编码器的重要性。需要一个视觉编码器,在更多样化和大规模的数据源上进行训练,这些编码器不被一组固定的标签所限制,并具有对看不见的对象和概念的泛化能力。
最近,提出CLIP用于在语言监督下学习视觉概念。CLIP包括一个视觉编码器和一个文本编码器,是从互联网上爬取的4亿个噪声图像-文本对上进行训练的,因此数据收集过程是可伸缩的,不需人工注释。CLIP在ImageNet分类等基准上有很强的零样本能力。将CLIP作为一个零样本模型应用于V&L任务是困难的,因为很多V&L任务需要复杂的多模态推理,因此,我们建议使用CLIP的视觉编码器,用CLIP的视觉编码器取代现有的V&L模型的视觉编码器。
我们考虑以下两种典型情况:1)将CLIP插入直接的特定于任务的微调;2)将CLIP与图像文本对的V&L模型预训练集成,并转移到下游任务。将在这两种场景中使用的模型表示为CLIP-ViL(没有V&L预训练)和CLIP-ViLp(有V&L预训练)。
在直接特定于任务的微调中,在视觉问答任务中,CLIP-ViL在VQA v2.0上实现了1.4%的改善。在V&L预训练中,我们用CLIP取代传统的基于区域的表示,CLIP-ViLp在三个基准测试上表现好,并获得了最新结果(VQA在test-std上76.70%)。使用CLIP-Res50的CLIP-ViLp优于广泛使用的基于区域的编码器BottomUp-TopDown ResNet101,而且,使用CLIP-Res50x4的CLIP-ViLp超过了VinVL-ResNeXt152,这是目前的SotA,是基于区域的编码器的极端放大尝试。
二、背景和动机
视觉和语言模型:在图1中说明了典型的训练阶段:1)视觉编码器在注释的视觉数据集上训练(表示为视觉编码器预训练);2)(可选)对配对的图像-标注数据进行重构目标和图像-文本匹配目标(表示为视觉和语言预训练);3)在特定任务的数据上微调(表示为特定于任务的微调)。

在V&L模型上的视觉编码器:图2中说明它们的架构和预训练过程,编码器可分为:1)基于区域的模型如BUTD对象检测器;2)基于网格的模型。编码器首先在人类注释的视觉数据集上预训练,基于区域的编码器用检测数据预训练,如Visual Genome;基于网格的编码器使用图像分类数据或检测数据进行预训练,如ImageNet。这些手动标记的数据集很昂贵且难以扩展,因此使用CLIP作为视觉编码器。

CLIP(对比的语言-图像预训练):CLIP属于从自然语言监督中学习视觉表示的研究领域,CLIP遵循一个“浅层交互设计”,其中一个视觉编码器和一个文本编码器分别编码输入图像和文本,两个编码器输出间的点积被用作输入图像和文本间的对齐分数。用一个对比损失预训练,其中模型需要从随机样本对中区分对齐的对,CLIP利用一个大量的没有人工注释的可用的监督源:从互联网上发现的4亿对图像-文本对。结果,CLIP在一系列的图像分类和图像文本检索任务中实现了SotA。我们考虑以下的CLIP变体,有着不同的视觉骨架:CLIP-Res50,CLIP-Res101,CLIP-Res50x4和CLIP-ViT-B.
三、CLIP-ViL
本节直接将CLIP插入到任务特定的模型,并对任务进行微调。
3.1 视觉问答
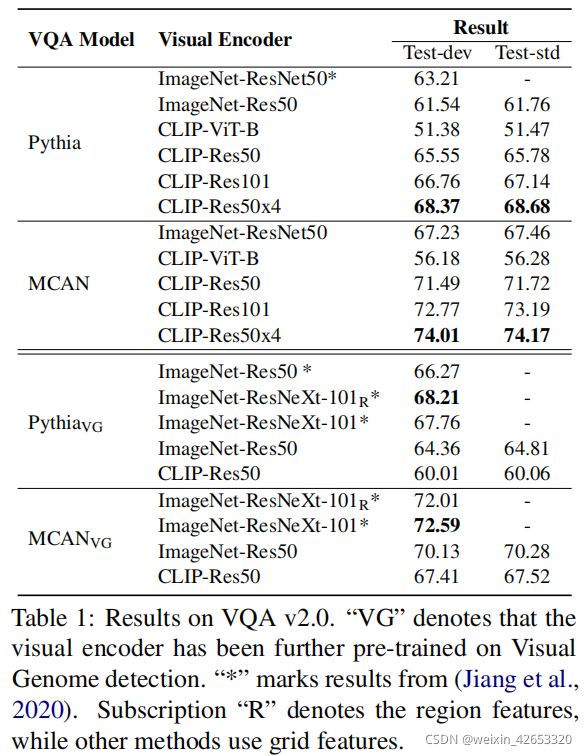
选择两个具有代表性的方法,pythia和MCAN,来研究CLIP视觉编码器在VQA中的影响。我们在VQA v2.0上评估,并遵循(Jiang等人,2020)进行网格特征提取。
结果如表1所示,与在ImageNet分类任务上预训练的视觉特征提取器相比,CLIP视觉模块显示出了明显的改进(前两部分)。在test-dev上,Pythia-Res50达到65.55%(比ImageNet-Res50好4.01%),MCAN达到71.49%(比ImageNetRes50好4.26%)。使用更大的模型(即CLIP-Res101和CLIP-Res50x4),结果继续改善,最大的CLIP-ViL CLIPRes50x4在Pythia上优于ImageNet-ResNeXt-101R(+0.16)。MCAN的CLIP-ViL CLIP-Res50x4在Test dev上达到74.01%,在test-std达到74.17%。
还显示了在VG上进一步检测预训练之后的结果(后两部分)。使用ImageNet-Res50编码器,VG帮助在PythiaVG上的性能提高2.82%(61.54%vs.64.36%),在MCAN VG上提高2.90%(67.23%vs.70.13%)。然而,PythiaVG的CLIP-Res50的性能显著下降了5.54%,MCANVG的性能下降了4.08%。潜在的原因是CLIP-Res50是在不同的数据上训练的,与ImageNet的方法不同,因此遵循之前为ImageNet模型设计的VIsual Genome微调实践可能会造成伤害。我们还注意到,我们表现最好的CLIP-ViL CLIPRes50x4 MCAN(74.01%)仍然超过了最好的ImageNet-ResNext-101 MCAN VG(72.59%)。
四、视觉和语言预训练
在特定任务的微调之前,模型对具有重构目标和图像文本匹配目标的对齐图像文本数据进行预训练。我们试图测试结合CLIP预训练和V&L预训练的潜力,我们引入CLIP-VILp,一种以CLIP视觉编码器为视觉主干,在图像-文本数据上预先训练过的视觉和语言模型。
4.1 CLiP-ViLp
模型结构 CLiP-ViLp假定一个文本段T和一个图像I作为输入,在BERT中,文本被标记为一系列子单词{w1,w2,...,wk}。每个子单词都被嵌入为它的标记、位置和段嵌入的总和,因此文本被嵌入为一个单词嵌入序列{w1,w2,...,wn}。图像嵌入一组来自网格特征图的视觉向量{v1、v2、...,vm}。然后将文本和视觉输入连接成一个序列,并由一个Transformer进行处理。在大多数基于区域的模型中,视觉主干被冻结,在CLiP-ViLp中,CLIP主干在V&L预训练和特定任务的微调中进行训练。
在图像-文本数据上预训练 为了学习视觉和语言的统一表示,我们遵循之前的工作,并根据图像-文本对对模型进行预训练。我们考虑LXMERT的三个预训练目标:1)接地的掩码语言建模,其中随机掩码输入句子中15%的单词,并训练模型来重构掩码单词;2)文本-图像匹配,模型提供一个概率为0.5的不匹配的句子,并训练分类文本是否对应于图像;3)视觉问答,训练模型预测给定一个问题的正确答案。
4.2 实验
我们将两种CLIP变体作为视觉编码器,CLIP-Res50和CLIP-Res50x4。根据LXMERT,我们使用从MSCOCO标注、Visual Genome标注、VQA、GQA和VG-QA中聚合的同一个语料库进行预训练。
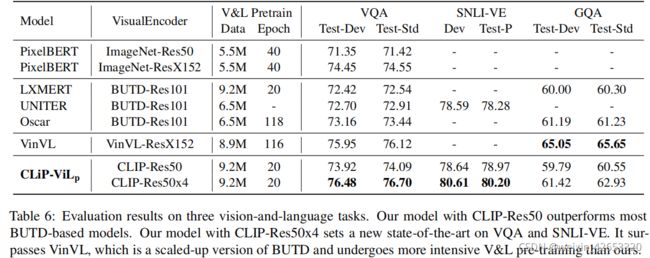
为进行评估,我们在三个V&L任务上微调了预训练好的模型:VQA v2.0,视觉暗示SNLI-VE和GQA。在表6中报告了结果,这些模型根据视觉编码器类型进行分组,我们的两个模型在所有指标上都具有竞争力,特别是使用CLIP-Res50x4的CLIP-ViL在VQA和SNLI-VE上建立了一个新的SotA.
我们的两个模型(CLIP-ViL与CLIP-Res50和CLIPRes50x4)显著优于大多数基于BUTDRes101的模型。我们特别注意到,LXMERT是在相同的预训练数据集上且与模型相同轮次的,但我们使用CLIP-Res50的CLiP-ViLp比VQA上的LXMERT强2.59。
VinVL是基于区域范式的极端扩展,该范式在多个对象检测数据集上进行预训练,包括MSCOCO、Open图像、对象365和视觉基因组。然而,我们的CLIP-Res50x4模型在VQA上优于VinVL,同时需要更少的步骤。
最后,我们与Pixel-BERT进行比较,与我们的模型有相似的设计,但使用ImageNet初始化ResNet。CLIP初始化显然比ImageNet初始化具有优势,因为CLIP-Res50显著优于有ImageNet-Res50的Pixel-BERT。
五、分析
在VQA中,CLIP的零样本性能 在原始论文中,CLIP是一种零样本模型,在各种视觉和图像检索任务上表现出较强的性能。因此,我们很好奇,CLIP是否也可以在可能需要复杂推理的V&L任务上作为一个零样本模型表现很好。为了进行零样本图像分类,CLIP使用数据集中所有类的名称作为候选文本集,并预测最可能的(图像、文本)对。因此,我们在VQA上使用类似的设置,但将候选文本修改为每个问题的问题和答案对的连接。此外,雷德福等人找到及时工程的结果改进。我们按照这个设计,构建“问题:[question text] 回答:[answer text]”作为提示模板。在VQAv2.0迷你版本上的结果如表7,所有的CLIP变体在零样本设置中表现在接近机会的水平,而提示工程只有一点帮助。当问题变得更加困难时,CLIP模型的性能也更差(“其他”vs “是/否”)。所有这些结果表明需要一个深度交互模型和额外的预训练/微调。

解开视觉骨干 由于微调对象检测器的技术困难,大多数V&L模型依赖于冻结的基于区域的编码器,然而,我们发现解冻视觉骨干可能会带来性能改进。具体来说,我们在VQA(test-dev)上测试了两个CLIP特征(即CLIP-Res50、CLIP-Res50x4)的主干微调性能,并与冻结的BUTD-Res101特征进行了比较。

没有预训练情况下,BUTD-Res101比CLIP-Res50获得了更高的性能。然而,经过V&L预训练后,CLIP-Res50明显优于BUTD-Res101,因为CLIPRes50的预训练(+9.25)获益大于BUTD-Res101(+5.72)。这表明,在预训练期间解冻视觉主干可以使CLIP-Res50适应预训练的任务。我们希望我们的发现能激发未来的工作,进一步探索解冻V&L的视觉主干。
CLIP-ViT-B的低的检测性能 如表1和表2所示,与其他模型相比,具有网格特征的CLIP-ViT-B有较大的性能下降。我们假设,这种减少是由于ViT特征图中缺乏视觉定位,因为不同的池化策略可能会影响定位能力。因此,我们遵循Jiang等人在CLIP-ViT-B网格特征图上训练视觉基因组上的检测器,以确认它。我们发现CLIP-ViT-B的平均精度(AP)仅为0.03,远低于其ImageNet-Res50的替代方案(我们复制的是3.14)。
CLIP变异体的定性比较 如上所述,我们怀疑CLIP-ViT-B缺乏一定的定位能力。为了更好地理解这一点,我们执行了基于梯度的定位(Grad-CAM)来可视化CLIP模型的显著区域。图3中的定性例子清楚地显示了CLIP-Res50定位了“左边女人的衬衫是什么颜色的?”比CLIP-ViT-B更好。

六、总结
在本文中,我们建议利用CLIP作为不同任务的不同V&L模型的视觉编码器。我们实验了两种方法:第一种,我们直接将CLIP插入特定任务的微调;第二种,我们将CLIP与V&L预训练集成,然后对下游任务进行微调。在不同的V&L任务上进行的各种大量实验表明,与强基线相比,CLIP-ViL和CLIP-ViLp可以实现具有竞争力或更好的性能。从不同的角度进行的分析解释了某些有趣的现象,并为未来的V&L研究提供了新的方向。