CLIP在V&L的应用论文笔记《HOW MUCH CAN CLIP BENEFIT VISION-AND- LANGUAGE TASKS?》
HOW MUCH CAN CLIP BENEFIT VISION-AND- LANGUAGE TASKS?
大多数现有的视觉和语言(V&L)模型依赖于预先训练过的视觉编码器,使用相对较小的手动注释数据集(与网络爬行的数据相比)来感知视觉世界。然而,我们可以观察到,大规模的预训练通常可以得到更好的泛化性能。我们建议在两种典型场景中使用CLIP作为各种V&L模型的视觉编码器:1)将CLIP插入特定任务的微调;2)将CLIP与V&L预训练结合起来,并转移到下游任务中。我们表明,CLIP显著优于广泛使用的使用领域内注释数据训练的视觉编码器,比如BottomUp-TopDown。我们在不同的V&L任务上取得了有竞争力或更好的结果,同时在Visual Question Answering,
Visual Entailment, and V&L Navigation tasks(视觉问答、视觉设计和V&L导航任务)上建立了新的最先进的结果。
1 INTRODUCTION
大多数V&L模型依赖于视觉编码器来感知视觉世界,它将原始像素转换为表示空间的向量。视觉表示已经成为V&L模型的性能瓶颈,并强调了学习一个强大的视觉编码器的重要性。检测或图像分类数据的收集成本很高,而且视觉表示受到预定义的类标签的限制。我们假设CLIP对V&L任务具有很大的潜力。然而,直接将CLIP作为零镜头模型应用于V&L任务被证明是困难的,因为许多V&L任务需要复杂的多模态推理。因此,我们建议将CLIP与现有的V&L模型集成,用CLIP的视觉编码器代替它们。
我们是最先使用CLIP作为视觉编码器的大规模实证研究。我们考虑两个典型的场景:1)我们直接在特定任务的微调中使用CLIP;2)将CLIP与在图像-文本对上预训练的V&L集成起来并转移到下游任务中we integrate CLIP with V&L pre-training on image-text pairs and transfer to downstream tasks.
为了清晰起见,我们将在这两种场景中使用的模型表示为 C L I P − V i L CLIP-ViL CLIP−ViL(不需要V&L预训练)和 C L I P − V i L p CLIP-ViL_p CLIP−ViLp(需要V&L预训练)。
在直接特定任务的微调中,我们考虑了三个广泛采用的任务: Visual Question Answering , Image Captioning , Vision-and-Language
Navigation,即视觉问题回答,图像字幕,视觉与语言导航。。在所有三个任务上,CLIP-ViL比强基线带来了相当大的改进,在VQAv2.0的准确率为1.4%,COCO字幕为6.5CIDEr,Room-to-Room导航的准确率为4.0%的成功率。
在V&L预训练中,我们用CLIP取代了传统使用的基于区域的表示。
2 BACKGROUND AND MOTIVATION
- Vision-and-Language (V&L) models
V&L任务需要一个模型来理解视觉世界,并将自然语言与视觉观察相结合。突出的任务包括visual question
answering, image captioning, vision-language navigation, image-text retrieval,即视觉问题回答、图像字幕、视觉语言导航、图像-文本检索等。为这些任务设计的V&L模型通常包括一个视觉编码器、一个文本编码器和一个跨模态交互模块。
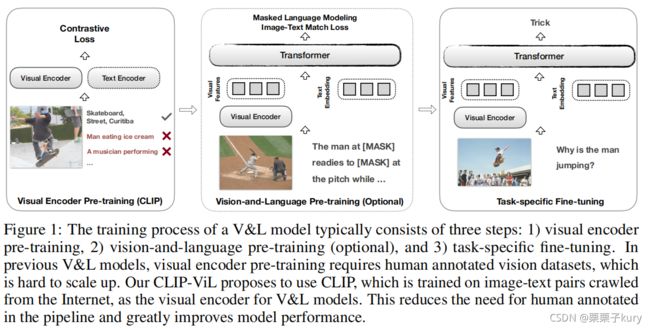
我们在图1中说明了三个典型的训练阶段
1)视觉编码器在标注的视觉数据集上进行训练。(记为视觉编码器预训练)
2)(可选)使用重建目标和图像文本匹配目标对配对的图像标题数据进行预训练(记为视觉和语言预训练)
3)对特定任务数据的微调(表示为特定任务的微调)
- Visual encoders in V&L models
从左到右依次为:基于区域的方法在对象上进行训练检测数据;对于基于网格的方法(图像分类或者检测任务);前两者均需要进行标注,而CLIP只需要对齐的文本。
- CLIP
CLIP遵循一种“浅层交互设计”,其中一个视觉编码器和一个文本编码器独立地对输入图像和文本进行编码,并使用两个编码器输出之间的点积作为输入图像和文本之间的相似性得分。
它是预先训练的对比损失,其中模型需要区分对齐的对和随机抽样的对。CLIP利用了一个大量可用的监督来源,而没有人工注释:在互联网上发现的4亿对图像-文本对。因此,CLIP在零镜头设置下的一系列图像分类和图像-文本检索任务中实现了Sota的性能。
2.1 MOTIVATION
我们建议将CLIP的视觉编码器与以前的V&L模型集成起来(图1)。接下来,我们将在两种场景下描述我们的方法:1)直接针对特定任务的微调,2)V&L预训练。
3 CLIP-VIL
在本节中,我们直接使用CLIP作为特定任务模型(称为CLIP-ViL)中的视觉编码器,并对三个代表性任务进行微调,包括视觉问题回答(第3.1节)、图像字幕(第3.2节)和视觉语言导航(第3.3节)。
3.1 VISUAL QUESTION ANSWERING
- Model Architecture
To integrate CLIP for the VQA models, we extract grid features using CLIP. For CLIP-ViT-B models, we reshape the patch representation from the final layer into grid features. For CLIP-ResNet models, we simply take the grid features from the last layer before the pooling.
- Implementation Details
For training the detector on the VG dataset, we replace the backbone with CLIP visual module using implementation of Faster R-CNN in Detectron2. For training VQA models, we use hyperparameters of the open-source implementation from (Jiang et al., 2020) for the large version of the MCAN and base version of Pythia.
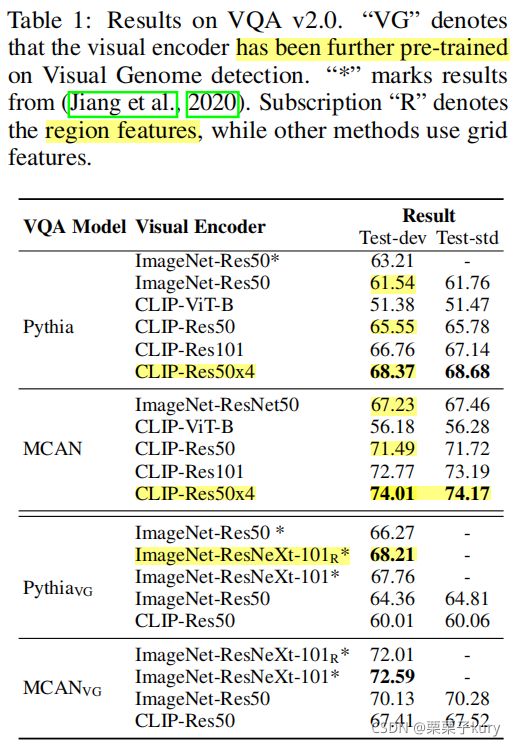
与在ImageNet分类任务中预训练的视觉特征提取器相比,CLIP视觉模块表现出明显的改进(表1的前两个块)。
P y t h i a V G Pythia_{VG} PythiaVG 比 P y t h i a Pythia Pythia的CLIP-Res50的性能显著下降了5.54%, M C A N V G MCAN_{VG} MCANVG比 M C A N V G MCAN_{VG} MCANVG的性能显著下降了4.08%。潜在的原因是CLIPRes50是在不同的数据上训练的,与ImageNet的方法不同,因此遵循之前为ImageNet模型设计的Visual-Genome(视觉基因组)微调实践可能会造成伤害。
3.2 IMAGE CAPTIONING
对于模型架构,我们用base Transformer模型进行了实验。为每个图像提取网格特征映射。我们在COCO数据集上评估了我们的模型。我们使用标准的自动评估指标,包括CIDEr, BLUE-4, METEOR and SPICE metric。
3.3 VISION-AND-LANGUAGE NAVIGATION
视觉和语言导航测试了代理根据人类指令采取行动的能力,这最近在具身人工智能中获得了广泛欢迎。具体来说,agent被放置在环境中的一个位置,并被要求按照语言指令达到目标。在这里,我们研究了CLIP视觉编码器对这项新任务的影响。
我们选择预训练的视觉编码器,把ImageNet预训练的ResNet替换为预先训练的CLIP视觉编码器。与使用特征图来包含详细信息的VQA任务不同,我们根据之前的工作对整个图像使用单向量输出。对于CLIP-ViT-B模型,我们取[CLS]标记的输出。对于CLIP-ResNet模型,我们取 attentive pooled feature of the feature map。这些特征也在CLIP被线性投影和L2归一化。
4 VISION-AND-LANGUAGE PRE-TRAINING
近年来,V&L预训练被认为是一种提高各种V&L任务性能的有效技术。 Before task-specific fine-tuning, the model is pre-trained on aligned image-text data with
a reconstructive objective and an image-text matching objective. 我们试图测试将CLIP预训练和V&L预训练相结合的潜力。 C L i P − V i L p CLiP-ViL_p CLiP−ViLp以CLIP视觉编码器为其visual backbone,对图像-文本数据进行预先训练的视觉和语言模型。
4.1 C L I P − V I L P CLIP-VIL_P CLIP−VILP
- Model Architecture
CLiP-ViLp假定一个文本段 T T T和一个图像 I I I作为输入。像在BERT中,文本被标记为一系列子单词{w1,w2,…,wk}。
Every subword is embedded
as the sum of its token, position, and segment embeddings and thus the text
is embedded as a sequence of word embeddings { w 1 , w 2 , . . . , w n } \{w1, w2, ..., wn\} {w1,w2,...,wn}.
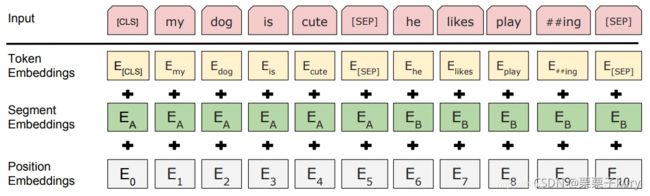
上图是Bert
The image is embedded as
a set of visual vectors {v1, v2, …, vm} from the grid-like feature map. The text and visual input
are then concatanated into a sequence, { w 1 , w 2 , . . . , w n , v 1 , v 2 , . . . , v m } \{w1, w2, ..., wn, v1, v2, ..., vm\} {w1,w2,...,wn,v1,v2,...,vm}, and processed by a single Transformer.
In most region-based models, the visual backbone is frozen as fine-tuning the object
detector along with the Transformer remains an open problem.
In C L i P − V i L p CLiP-ViL_p CLiP−ViLp, the CLIP backbone is trained during both V&L pre-training and task-specific fine-tuning.
- Model
For the model architecture, we experiment with the basic attentive neural agent.然后,代理模型(i.e., another LSTM)关注视觉特征和语言表征来预测动作。在每个时间步t中,代理会关注全景视图 { v t , i } i \{v_{t,i}\}_i {vt,i}i和指示 { w j } \{w_j\} {wj}来进行操作。全景视图用预先训练过的视觉编码器(如ResNet)处理,指令由语言LSTM处理,记为 L S T M L LSTM_L LSTML。代理模型, L S T M A LSTM_A LSTMA,关注视觉特征和语言表示来预测动作。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-AXXQk3CO-1634278751422)(./clip_benefit/shizi.png)]](http://img.e-com-net.com/image/info8/7e35eddc12b44749a81e49e485fd5207.jpg)
其中 h t h_t ht和 c t c_t ct分别是时间步长t时动作LSTM的隐藏层和状态。
- Pre-training on Image-Text Data
为了学习视觉和语言的统一表示,我们遵循之前的工作,并对图像-文本对对模型进行预训练。我们考虑了LXMERT的三个预训练目标:1)grounded masked language modeling,我们随机屏蔽输入句子中15%的单词,训练模型重建掩码单词;2)文本图像匹配,其中模型提供一个不匹配的概率为0.5的句子,并训练其分类文本是否对应于图像;3)视觉问题回答,我们训练模型预测给定问题的正确答案。
- Results Comparison to Grid Features
We also report the comparison to grid features that is trained with detection dataset. The results with these features are comparable to the original bottom-up attention with a heavy detection module.
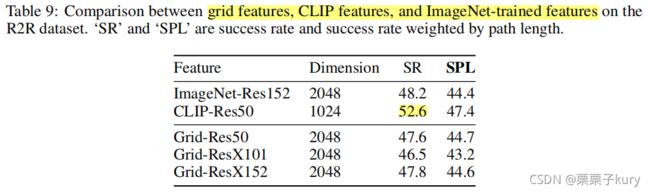
如表9所示,在相同的ResNet50主干下,我们发现, detection-trained grid features与classification-trained
grid features相同,仍然与contrastive-trained grid features存在差距。We hypothesize that the grid features inject regional knowledge into the dense feature map thus showing good results with
grid-based modules. However, pooling the feature map into a single feature
vector (as in previous VLN works) leads to a loss of this dense information.
4.2 EXPERIMENTS
- Setup
我们实验用CLIP的两种变体作为视觉编码器,CLIP-res50和CLIP-Res50x4。Following LXMERT, we use the same corpora aggregated from MS COCO Captions, Visual Genome Captions, VQA, GQA, and VG-QA for pre-training.我们遵循相同的预处理程序,并从训练前数据集中排除任何测试数据。这导致了918万像素的图像-文本对(9.18M image-text pairs)。
为了提高计算效率,我们对图像使用了相对较小的分辨率。我们通过保留的长宽比,将图像中较短的边调整为384,将较长的边调整为640以下。在预训练过程中,由于图像补丁的数量较大,我们根据PixelBERT为每张图像随机抽取100个图像补丁。我们对该模型进行了20次迭代的预训练,并在预训练和微调过程中解冻了CLIP主干。
- Task
为了进行评估,我们在三个V&L任务上调整了预先训练过的模型: VQA v2.0, visual entailment SNLI-VE,和GQA。
- Results
As our model is based on B E R T B A S E BERT_{BASE} BERTBASE, we compare only with models based on B E R T B A S E BERT_{BASE} BERTBASE. The models are grouped by their visual encoder type.
LXMERT与我们的模型在相同的预训练数据集上进行训练,并且对相同数量的迭代次数进行训练,然而,我们使用CLIP-Res50的CLIP-ViLp在VQA上的表现超过了LXMERT 2.59分。
VinVL是基于区域的范式的一个极端扩展,该范式在多个对象检测数据集上进行了预先训练。然而,我们使用CLIP-Res50x4的模型在VQA上优于VinVL,同时需要明显更少的V&L预训练步骤。在GQA上,我们的模型的性能没有VinVL表现好。潜在的原因是GQA是由对象边界框数据自动构建的,这可能会给根据这些对象数据训练的基于区域的模型一个显著的优势。
Pixel-BERT 与我们的模型类似,但使用ImageNet初始化的ResNet。CLIP初始化显然比ImageNet初始化具有优势,CLIP-Res50显著优于用ImageNet-Res50的Pixel-bert。
5 ANALYSIS
- Zero-Shot Performance of CLIP in VQA
在本文中,CLIP是一种零镜头模型,在各种视觉和图像检索任务上表现出较强的性能。因此,我们很好奇,CLIP是否也可以在可能需要复杂推理的V&L任务上执行零镜头模型。为了进行零拍摄图像分类,CLIP使用数据集中所有类的名称作为候选文本集,并预测最可能的(图像、文本)对。因此,我们在VQA上使用类似的设置,但将候选文本修改为每个问题的问答对的连接。 Moreover, Radford et al. (2021) find
a result improvement from prompt engineering.
我们按照这个设计,构建 “question:
[question text] answer: [answer text]”作为prompt template。VQA v2.0 mini-eval的结果如表7所示。所有的CLIP变体在零镜头设置中表现at near-chance level,而提示工程只有一点帮助。当问题变得更加困难时,CLIP模型的性能也更差 (“other” vs. “yes/no”)。所有这些结果表明需要一个深度交互模型和额外的预训练/微调。
- Unfreezing the Visual Backbone
Because of technical difficulty in fine-tuning the object detector, most V&L models rely on frozen region-based encoders. However, we find that
unfreezing the visual backbone may bring performance improvement.
在VQA(test-dev)上测试两个CLIP特性的主干微调性能(即CLIP-Res50,CLIP-Res50x4),并与冻结的BUTD-Res101特性进行比较。
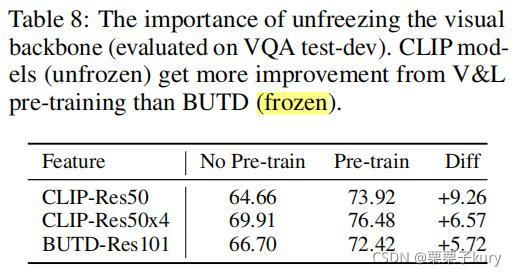
在没有预训练的情况下,BUTD-Res101比CLIP-Res50获得了更高的性能。然而,经过V&L预训练后,CLIP-Res50的性能显著优于BUTD-Res101,因为CLIP-Res50从预训练中获益(+9.25)大于BUTD-Res101(+5.72)。这表明,在预训练期间解冻visual backbone可以使CLIP-Res50适应预训练的任务。我们希望我们的发现能够激发未来的工作,在计算预算允许的情况下,进一步探索解冻V&L模型中的visual backbone。
- Low Detection Performance of CLIP-ViT-B
如表1和表2所示,与其他模型相比,具有网格特征的CLIP-ViT-B有较大的性能下降。We hypothesize
that such decrease is due to the lack of visual localization inside the ViT feature map since different
pooling strategies may affect the localization ability.
We thus train a detector on Visual Genome over the CLIP-ViT-B grid feature maps to confirm it.
- Qualitative Comparison of CLIP Variants
如上所述,我们怀疑CLIP-ViT-B缺乏一定的定位能力。为了更好地理解这一点,我们执行了基于梯度的定位(Grad-CAM)来可视化CLIP模型的显著区域。图3中的定性例子清楚地显示了CLIP-Res50定位了“左边女人的衬衫是什么颜色的?”比CLIP-ViT-B更好。

6 Conclusions
在本文中,我们建议利用CLIP作为不同任务的不同V&L模型的视觉编码器。我们实验了两种方法:第一种,我们直接将CLIP插入特定任务的微调;第二种,我们将CLIP与V&L预训练集成,然后对下游任务进行微调。在不同的V&L任务上进行的各种大量实验表明,与强基线相比,CLIP-ViL和CLIP-ViLp可以实现具有竞争力或更好的性能。从不同的角度进行的分析解释了某些有趣的现象,并为未来的V&L研究提供了新的方向。