机器学习 | 最大熵模型
什么是最大熵模型?
- 1 前言
- 2 什么是最大熵模型?
-
- 2.1 通俗解释
- 2.2 最大熵原理
- 2.3 最大熵模型
-
- 2.3.1 模型约束
- 2.3.2 什么叫经验分布?
- 2.3.3 最大熵模型的表示
- 2.3.4 最大熵模型的学习
- 3 最大熵模型的应用场景
- 4 模型优缺点
-
- 4.1 优点
- 4.2 缺点
- 参考
1 前言
继续梳理李航老师《统计学习方法》的章节内容,今天我们一起来看一看啥叫最大熵模型?
2 什么是最大熵模型?
2.1 通俗解释
首先来看看吴军老师的《数学之美》书中对于最大熵模型的通俗解释。
- 一句话概括:不要把鸡蛋放到一个篮子里!
- 保留全部的不确定性,将风险降到最小,此时对应的熵最大!
- 最大熵原理指出对于一个随机事件的概率分布进行预测时,我们的预测应当满足全部已知的条件,而对未知的情况不要做任何的主观假设。在这种情况下,概率分布最均匀,预测的风险最小。因为这时候概率分布的信息熵最大,所以人们将模型称为“最大熵模型”!
这时候有一个基础的问题:什么叫信息?什么叫熵?继续来看吴军老师是如何给我们解释的!
- 信息量等于不确定性的多少。那如何来度量这个不确定性呢?1948年香农在著名的论文“通信的数学原理”中给出“信息熵”的概念!
这时候吴老师提出了一个很形象的例子,记得之前上数据挖掘课的时候老师也说过~
典例-什么是熵?
世界杯32支队伍比赛,小李同学因沉迷学习没有观看比赛直播,这时候他问一位知道冠军队伍的观众:“哪支球队是冠军?”嘿,他这时候却不说,说你猜!猜一次就要给我一块钱!(然后脸上露出了狡诈的坏笑表情!)行吧,那么小李同学就开始猜了!那需要猜几次呢?相信看过之前 数据结构与算法 | 二分查找 的小伙伴肯定会这么猜:
首先给32支队伍进行编号1-32。
- 冠军球队在1-16号吗?
- 如果是,在1-8号吗?
- 如果是,在1-4号吗?
- 如果是,在1-2号吗?
- 如果是,是1吗?
这时候无论最后一次猜没猜中,我都知道了冠军队伍是谁了!不是1就是2嘛!所以我一共进行了5次猜测,需要付给这位狡猾的小伙伴5元人民币!
这个故事说明什么?谁是冠军队伍这条信息值5元钱!
当然,香农不是用钱的,而是用“比特”(Bit)这个概念来度量信息量。即谁是冠军队伍这条信息值5比特!
同理,如果队伍扩充为64支,对应的信息值6比特了!
Python求解的代码见下:
def Cal_entropy(n):
'''
计算等概率的熵
n:样本量
'''
H = 0
for i in range(n):
H += ((1/n) * np.log2(1/n))
# print(- H)
return (-H)
print('32支队伍谁获得冠军的信息量值 %s 比特' % Cal_entropy(32))
print('64支队伍谁获得冠军的信息量值 %s 比特' % Cal_entropy(64))
结果为:
32支队伍谁获得冠军的信息量值 5.0 比特
64支队伍谁获得冠军的信息量值 6.0 比特
其实上面的推导暗含了一个假设:32支队伍各自夺得世界杯冠军的概率是一致的!其实我们完全可以首先在所有队伍去除掉一些非常弱的球队,这样其实就不需要猜5次了,所以我们根据现在等概率计算出来的熵(将上述信息量称为熵)是最大熵!
故精确的来说,对于任意一个随机变量 X X X,它的熵定义为:
-
H ( X ) = − ∑ x ∈ X p ( x ) l o g p ( x ) H(X)=-\sum_{x \in X}p(x)logp(x) H(X)=−∑x∈Xp(x)logp(x)
-
变量的不确定性越大,熵就越大,要把它搞清楚,所需的信息量也就越大!
上面把熵的概念弄清楚了,还有一个叫条件熵的:
在已知 y y y的情况下 x x x的条件熵为:
- H ( X ∣ Y ) = − ∑ x ∈ X , y ∈ Y P ( x , y ) l o g P ( x ∣ y ) H(X|Y)=-\sum_{x\in X,y\in Y}P(x,y)logP(x|y) H(X∣Y)=−∑x∈X,y∈YP(x,y)logP(x∣y)
- 数学上可以证明 H ( X ∣ Y ) < H ( X ) H(X|Y) <H(X) H(X∣Y)<H(X)
- 即多了 y y y的信息之后 x x x的不确定性下降了,也说明了二元模型的不确定性小于一元模型,可推广~
- 信息的作用在于消除不确定性,自然语言处理的大量问题就是寻找相关的信息。
有了熵和条件熵的概念,似乎还不太够,因为我们目前好像还是单纯的比较一条信息的价值是多少,然后用熵来衡量,熵越大,信息价值越大,以及条件熵的概念,即给定 y y y的情况下 x x x的不确定性。但如何衡量两条信息之间的相关性呢?推广位为两个时间的相关性!
可以用一个图形象描述:

引入互信息的概念:
- I ( X ; Y ) = H ( X ) − H ( X ∣ Y ) I(X;Y)=H(X)-H(X|Y) I(X;Y)=H(X)−H(X∣Y)
- 相关性:在了解了其中一个Y的前提下,对消除另一个X不确定性所提供的信息量。
- 互信息取值范围:(0,min(H(X),H(Y)))
- X和Y完全相关:H(X|Y)没有任何价值,为0,结果为H(X)
- X和Y完全无关时,H(X|Y)=H(X),故结果为0!
同时还有相对熵的概念,这里暂时不补充讲解了。
2.2 最大熵原理
最大熵模型是由最大熵原理引申的,那么什么叫最大熵原理呢?
举一个形象的例子就ok了!“等可能”!
例子1:
- 假设随机变量 X X X有5个取值 A , B , C , D , E {A,B,C,D,E} A,B,C,D,E,要估计各个值的概率 P ( A ) P(A) P(A), P ( B ) P(B) P(B),…, P ( E ) P(E) P(E)
- 这些概率值满足条件 P ( A ) + P ( B ) + P ( C ) + P ( D ) + P ( E ) = 1 P(A)+P(B)+P(C)+P(D)+P(E)=1 P(A)+P(B)+P(C)+P(D)+P(E)=1
- 但是满足这个条件的概率分布有无数个。如果没有其他信息,一个可行的办法就是认为他们的概率都相等,均为0.2。
补充例1:
- 如果再加一个条件 P ( A ) + P ( B ) = 0.3 P(A) + P(B) = 0.3 P(A)+P(B)=0.3,那么各个值的概率为多少? 认为 P ( A ) = P ( B ) = 0.15 P(A)=P(B)=0.15 P(A)=P(B)=0.15, P ( C ) = P ( D ) = P ( E ) = 0.23 P(C)=P(D)=P(E)=0.23 P(C)=P(D)=P(E)=0.23
上述就是最大熵原理,即等可能!满足约束条件下,不作任何假设!
2.3 最大熵模型
2.3.1 模型约束
- 最大熵原理是统计学习的一般原理,将它应用到分类就得到了最大熵模型,故最大熵模型是一种分类模型!
- 假设分类模型是一个条件概率分布P(Y|X),X表示输入,Y表示输出。这个模型表示的是对于给定的输入X,以条件概率P(Y|X)输出Y,即达到了分类效果!
- 给定一个训练数据集 T = ( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . ( x n , y n ) T={(x_1,y_1),(x_2,y_2),...(x_n,y_n)} T=(x1,y1),(x2,y2),...(xn,yn),我们的目标就是利用最大熵原理选择最好的分类模型。
- 按照最大熵原理,我们应该优先保证模型满足已知的所有约束。那么如何得到这些约束呢?
- 思路是:
- 从训练数据T中抽取若干特征
- 然后要求这些特征在T上关于经验分布的期望与它们在模型中关于p(x,y)的数学期望 相等,这样,一个特征就对应一个约束。
上面这个思路还是比较抽象的,我们来看个具体的例子!
首先**提取特征**:

约束为:下面的 f ( x , y ) f(x,y) f(x,y)就是上面提取的特征!
- 特征在T上关于经验分布 p ˉ ( x , y ) \bar{p}(x,y) pˉ(x,y) 的期望 E p ˉ ( f ) E_{\bar{p}}(f) Epˉ(f)
- 特征在模型中关于 p ( x , y ) p(x,y) p(x,y)的期望 E p ( f ) E_{{p}}(f) Ep(f)
- 约束1为: E p ˉ ( f ) = E p ( f ) E_{\bar{p}}(f)=E_{{p}}(f) Epˉ(f)=Ep(f)

但上面有一个问题就是 p ( x , y ) p(x,y) p(x,y)我们无法直接得到,于是用贝叶斯定理 p ( x , y ) = p ( x ) ⋅ p ( y ∣ x ) p(x,y)=p(x)·p(y|x) p(x,y)=p(x)⋅p(y∣x) 来进行估计!所以上式约束中的 E p ( f ) E_{{p}}(f) Ep(f)就变为:
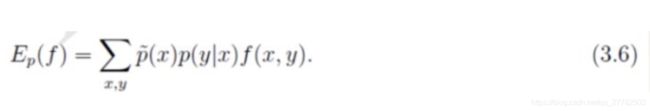
- p ( x ) p(x) p(x)虽然也还是未知,但我们可以使用经验分布 p ˉ ( x ) \bar{p}(x) pˉ(x)对 p ( x ) p(x) p(x)进行近似。
- 而 p ( y ∣ x ) p(y|x) p(y∣x)则是我们要求解的,最大熵模型希望达到分类的效果就是根据 p ( y ∣ x ) p(y|x) p(y∣x)的结果得到的!
于是上面得到了第一个约束,也就是两个期望要相等,另一个约束则比较显而易见,就是概率之和为1:
- 约束2: ∑ y p ( y ∣ x ) = 1 \sum_{y}p(y|x)=1 ∑yp(y∣x)=1
至此,最大熵模型的两个约束我们就都列举ok了!
2.3.2 什么叫经验分布?
上面在约束的推导过程中用到了“经验分布”这个概念,这究竟是什么意思呢?其实考过研的同学应该知道,这个经验分布其实很简单的一个内容,所以也就基本不怎么考…
首先我们来举个实例,具体看看什么叫经验分布!
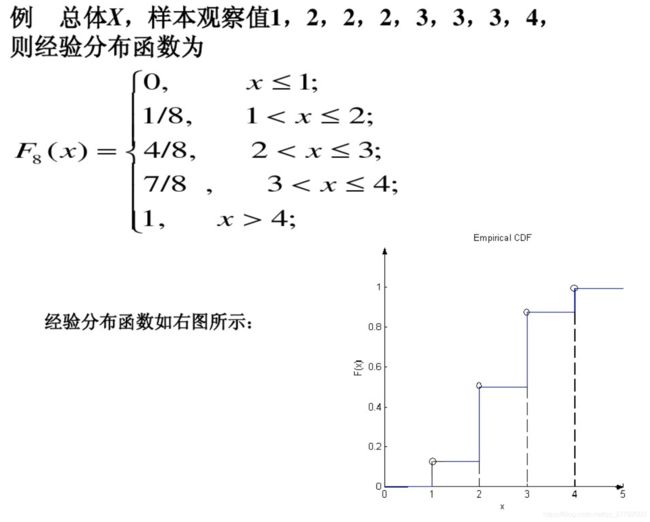
是不是超简单?就是数个数!然后分段描述!
具体的数学定义是什么样的呢?

那大家肯定会问一个问题,这个经验分布和实际的分布是什么关系?经验分布能用来近似实际的分布吗?
下面从两个角度来进行阐述。
- 角度1:图形角度。可以看到阶梯形的经验分布是可以用来近似理论分布的。
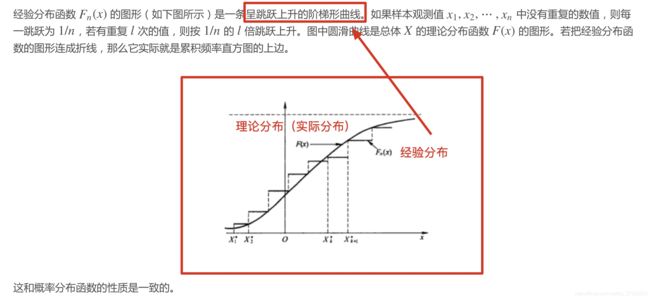
- 角度2:定理角度-格利文科定理(Glivenko Theorem)

这就在理论的层面解释了可以用经验分布来代替理论分布!
2.3.3 最大熵模型的表示
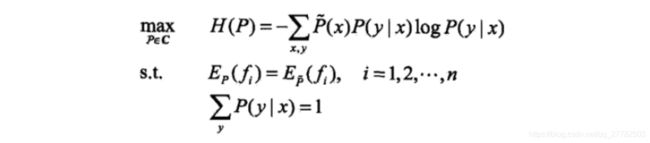
总结一下最大熵模型:
- 目标函数:
- 给定数据集 T T T,我们的目标就是根据最大熵原理选择一个最优的分类器,即在条件概率分布 P ( Y ∣ X ) P(Y|X) P(Y∣X)上的条件熵 H ( P ) H(P) H(P)达到最大!即得到 p ( y ∣ x ) p(y|x) p(y∣x)。
- 两个约束:
- 从数据集 T T T中抽取的特征关于经验分布的期望=从数据集 T T T中抽取的特征关于 p ( x , y ) p(x,y) p(x,y)的期望。一个特征就对应一个约束。
- 概率和为1
2.3.4 最大熵模型的学习
这部分运用到的知识包括:
- 将有约束问题变为无约束问题(拉格朗日乘子法)
- 将min max问题转为求解其对偶问题 max min (凸优化问题,满足KKT条件)
- 对于max min问题进行分解,首先求min问题得到结果为 f f f,然后求 m a x ( f ) max(f) max(f),得到 p ( y ∣ x ) p(y|x) p(y∣x)
具体的过程参考刘建平老师的博客:

补充一点,求出了min之后,对 ψ ( w ) ψ(w) ψ(w)求极大化,由于它是连续可导的,所以优化方法有很多种,比如梯度下降法,牛顿法,拟牛顿法都可以。对于最大熵模型还有一种专用的优化方法,叫做改进的迭代尺度法(improved iterative scaling, IIS)。
IIS也是启发式方法,它假设当前的参数向量是 w , w, w,我们希望找到一个新的参数向量 w + δ w+δ w+δ,使得对偶函数 ψ ( w ) ψ(w) ψ(w)增大。如果能找到这样的方法,就可以重复使用这种方法,直到找到对偶函数的最大值。
IIS使用的方法是找到 ψ ( w + δ ) − ψ ( w ) ψ(w+δ)−ψ(w) ψ(w+δ)−ψ(w)的一个下界 B ( w ∣ δ ) B(w|δ) B(w∣δ),通过对 B ( w ∣ δ ) B(w|δ) B(w∣δ)极小化来得到对应的 δ δ δ的值,进而来迭代求解 w w w。对于 B ( w ∣ δ ) B(w|δ) B(w∣δ),它的极小化是通过对 δ δ δ求偏导数而得到的。
PS:后面可以单独出一篇推文讲解下梯度下降法,牛顿法,拟牛顿法!
3 最大熵模型的应用场景
- 分类模型!
4 模型优缺点
4.1 优点
- 形式简单,思路简单。
- 准确率高。最大熵统计模型获得的是所有满足约束条件的模型中信息熵极大的模型,作为经典的分类模型时准确率较高。
- 可以灵活地设置约束条件。通过约束条件的多少可以调节模型对未知数据的适应度和对已知数据的拟合程度
4.2 缺点
- 计算太复杂,难以应用。 它的约束函数的数目一般来说会随着样本量的增大而增大,导致样本量很大的时候,对偶函数优化求解的迭代过程非常慢,应用困难。
参考
- 刘建平老师博客:最大熵模型原理小结
- 知乎 推导讲的很细致 深入机器学习系列21-最大熵模型
- 经验分布函数(Empirical Distribution Functions)
- 经验分布函数的例题