Self-attention
Self-attention
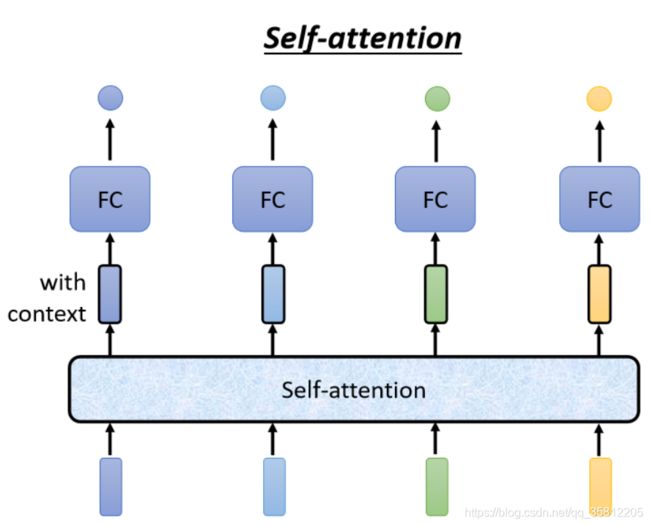
然后你Input几个Vector,它就输出几个Vector,比如说你这边Input一个深蓝色的Vector,这边就给你一个另外一个Vector。这边给个浅蓝色,它就给你另外一个Vector,这边输入4个Vector,它就Output 4个Vector。
这4个Vector,他们都是考虑一整个Sequence以后才得到的。
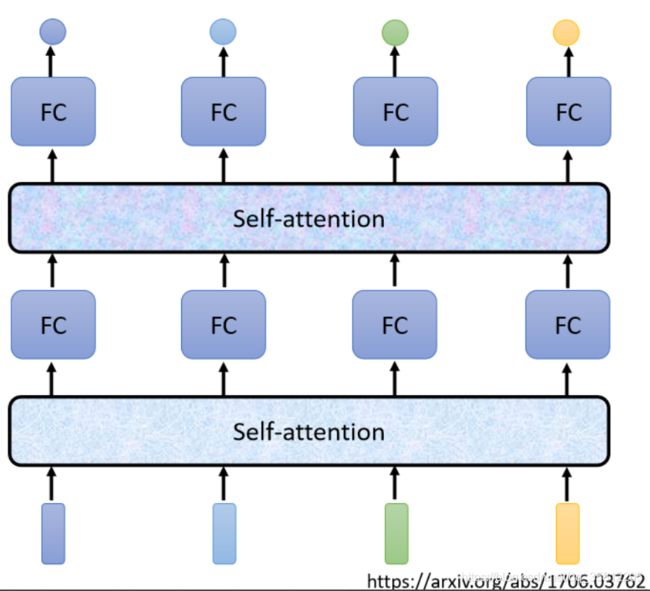
Self-Attention不是只能用一次,你可以叠加很多次。所以可以把Fully-Connected的Network,跟Self-Attention交替使用
- Self-Attention处理整个Sequence的资讯
- Fully-Connected的Network,专注於处理某一个位置的资讯
- 再用Self-Attention,再把整个Sequence资讯再处理一次
- 然后交替使用Self-Attention跟Fully-Connected
Self-Attention过程

Self-Attention的Input,它就是一串的Vector,那这个Vector可能是你整个Network的Input,它也可能是某个Hidden Layer的Output,所以我们这边不是用x来表示它,
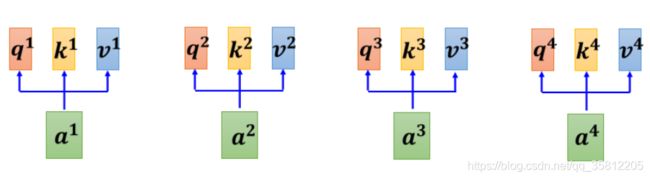
1.怎么产生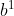
https://andyguo.blog.csdn.net/article/details/119547811



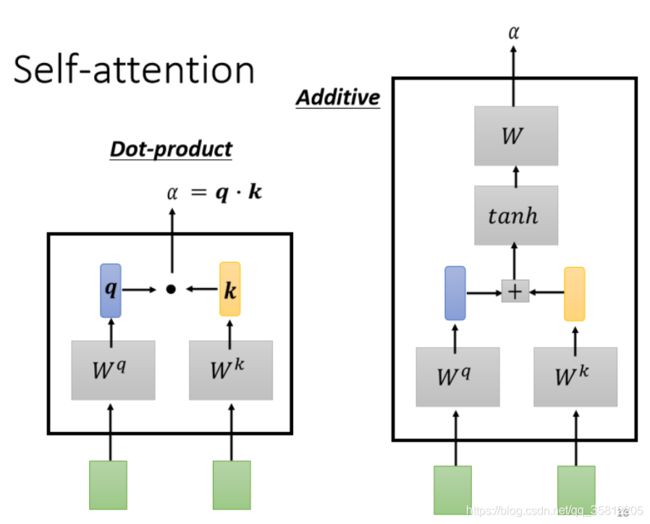
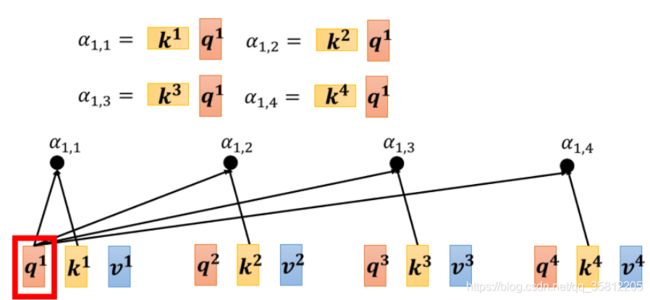
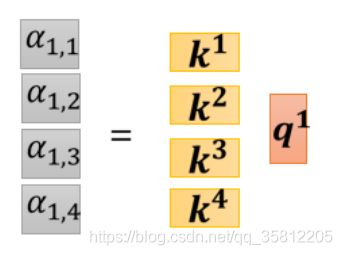
这个计算attention的模组,就是拿两个向量作為输入,然后它就直接输出α那个数值,
2.计算α







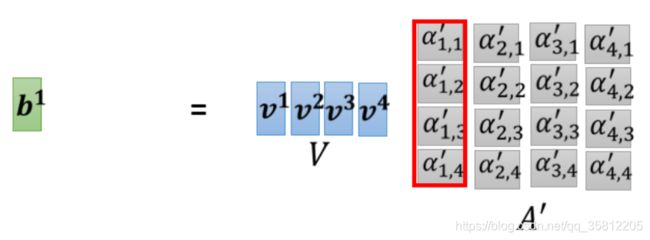
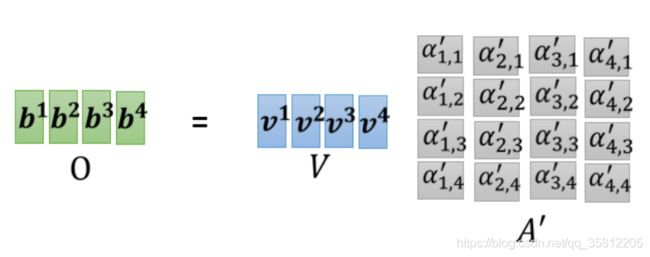
求


矩阵的角度

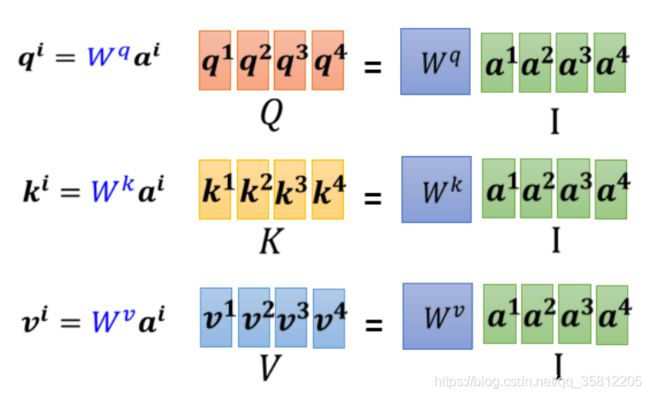


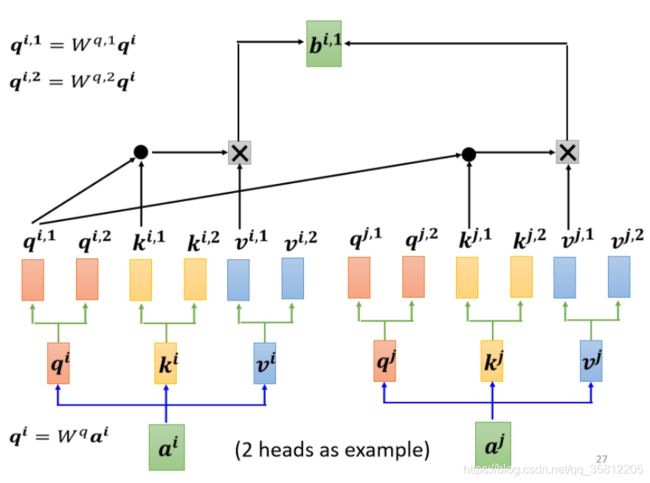
Multi-head Self-attention



Transformer

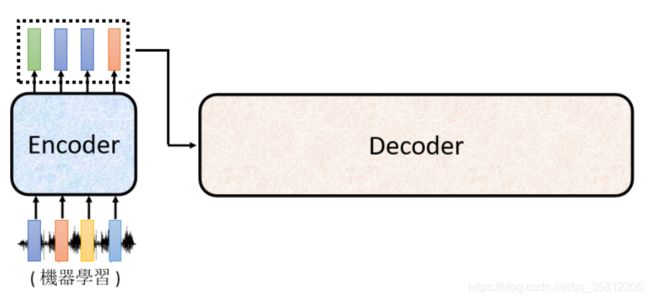
一般的seq2seq’s model分成2块——Encoder和Decoder

Encoder
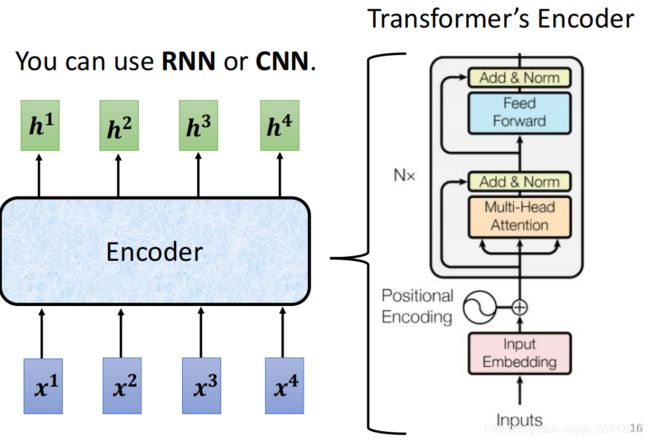
在transformer里的encoder用的就是self-attention,我们先看简化图,最后在和transformer原始论文的图进行对比。
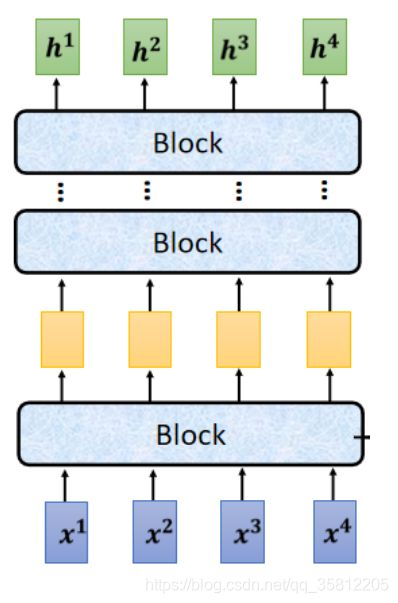
现在的Encoder里分成很多block,每个block都是输入一排向量输出一排向量,注意这里每个block其实不是neural network的一层,是好几个layer做的事情(如下图所示):
先做一个self-attention,input一排vector以后,做self-attention,考虑整个sequence的资讯,Output另外一排vector.
接下来这一排vector,会再丢到fully connected的feed forward network裡面,再output另外一排vector,这一排vector就是block的输出
但其实在原来的transformer里面这个block做的事更加复杂。在之前讲的self-attention中输入一排vector输出一排vector,这里的每个vector是考虑了所有的input后得到的结果。而在transformer里面加了了一个设计——不只是输出这个vector,还要把这个vector加上它的input得到新的ouput(这样的network架构叫做residual connecttion,在DL领域也是应用非常广泛)
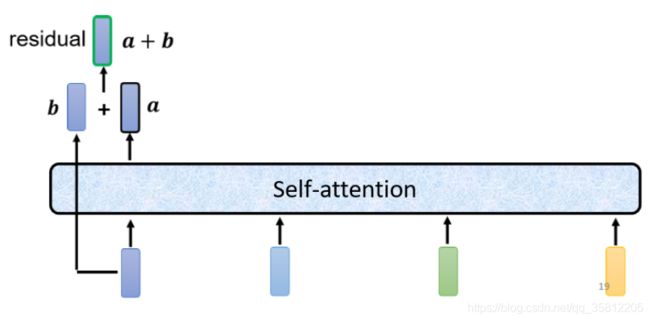
把得到的residual结果做normalization(这边用的不是batch normalization,而是用layer normalization)。
计算出mean跟standard deviation以后,就可以做一个normalize,我们把input 这个vector里面每一个dimension减掉mean再除以standard deviation以后得到x’,就是layer normalization的输出。
![]()
得到layer normalization的输出以后,它的这个输出 才是FC network的输入。

注意:
batch normalization是对不同example,不同feature的同一个dimension,去计算mean跟standard deviation。
但layer normalization,它是对同一个feature,同一个example里面不同的dimension去计算mean跟standard deviation。

而FC network这边也有residual的架构,所以 我们会把FC network的input跟它的output加起来 做一下residual得到新的输出。这个FC network做完residual以后,还不是结束 你要把residual的结果再做一次layer normalization得到的输出,才是residual network里面的一个block的输出。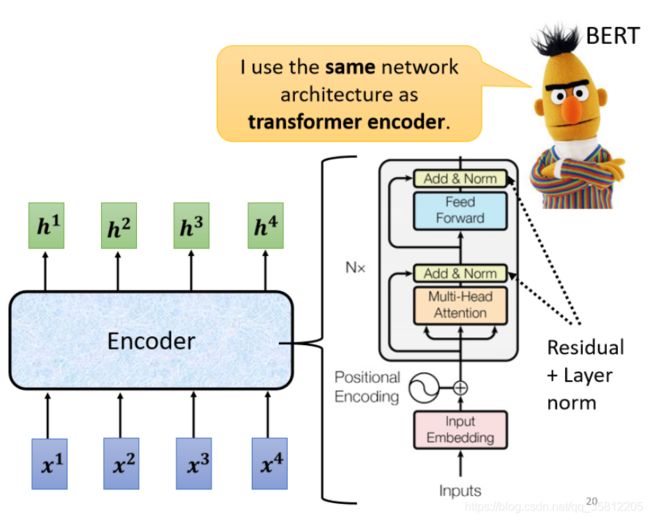
首先 你有self-attention,其实在input的地方,还有加上positional encoding(如果你只光用self-attention,你没有位置的资讯)
Multi-Head Attention,这个就是self-attention的block,用到多头注意力机制
Add&norm,就是residual加layer normalization
接下来,要过feed forward network
fc的feed forward network以后再做一次Add&norm,再做一次residual加layer norm,才是一个block的输出,
然后这个block会重复n次,这个复杂的block,其实在之后会讲到的一个非常重要的模型BERT,它其实就是transformer的encoder
Decoder – Autoregressive
(1)先给它一个特殊的符号——代表开始,在开始的ppt里写Begin Of Sentence(缩写是BOS),这是一个special的token。就是在你的Lexicon(字典)里面,即Decoder可能产生的文字里面多加一个特殊的字——该字代表begin(开始)
(2)接着Decoder会吐出一个很长的vector(和vocabulary的size一样)

vocabulary size是什么意思?
先想好Decoder输出的单位是什么,如果做得是中文的语音识别则我们Decoder输出的是中文,那么vocabulary size可能就是中文方块字的数目
不同的字典size可能是不同的,常用的中文方块字大约三千,一半人可能人的四五千,那么这个Decoder能够输出常见的3000个方块字就好(这个取决于你对该语言的理解)。
再举栗子:可以选择输出字母A到Z输出英文的字母,而如果觉得字母这个单位太小了,可以用英文单词的“词根”作为单位。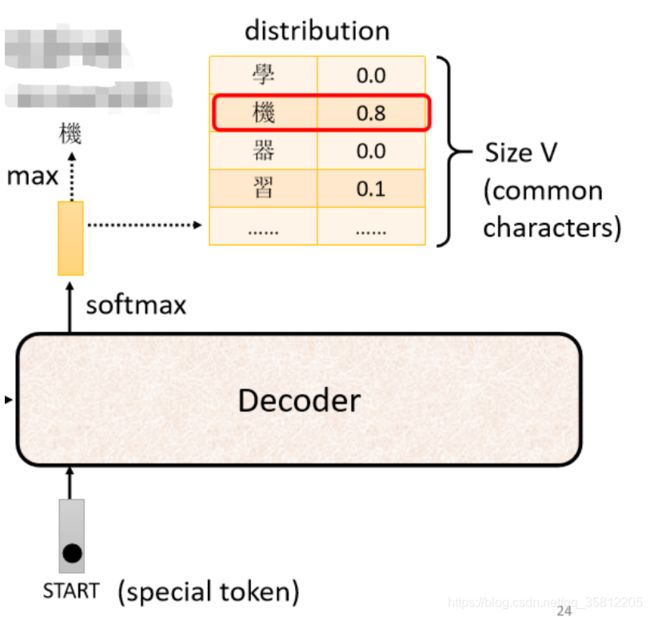
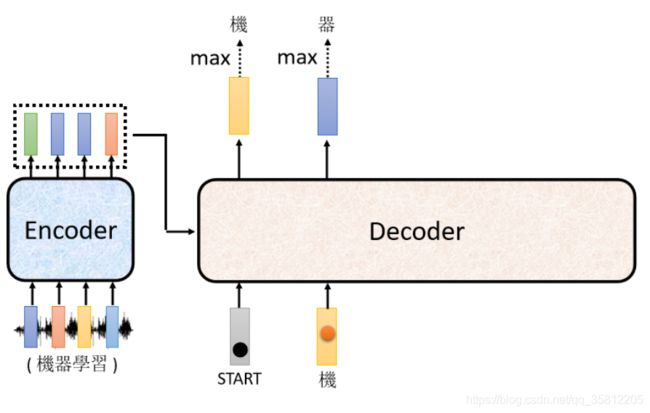

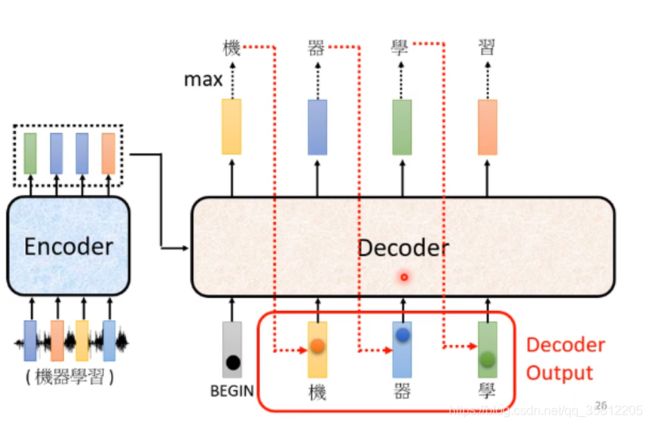
Decoder内部结构
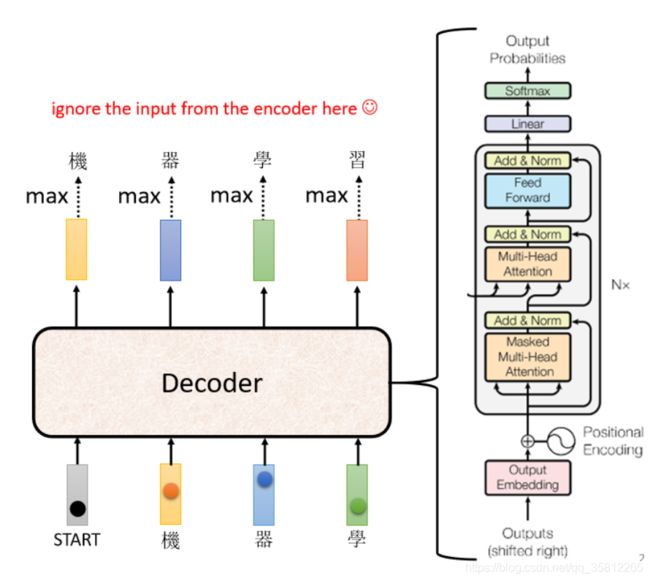
在transformer里面的Decoder结构如下图所示,比Encoder稍微复杂点:
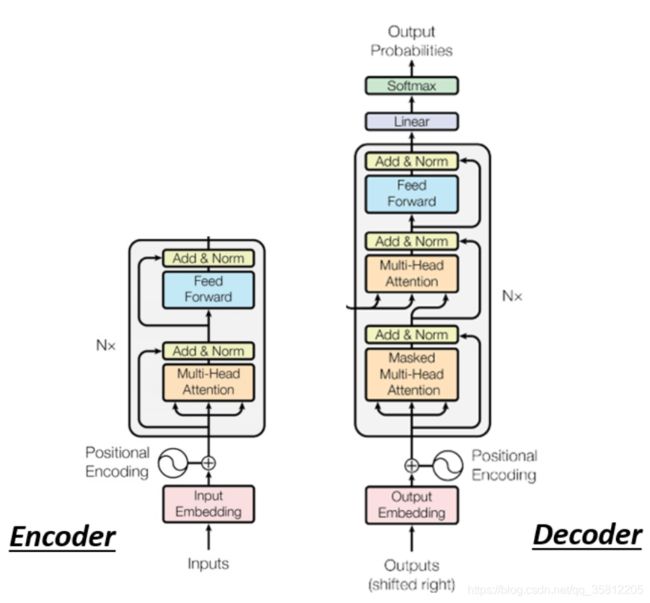
注意有个地方不同,在Decoder的Multi-Head Attention这个Block上面还加了一个Masked。
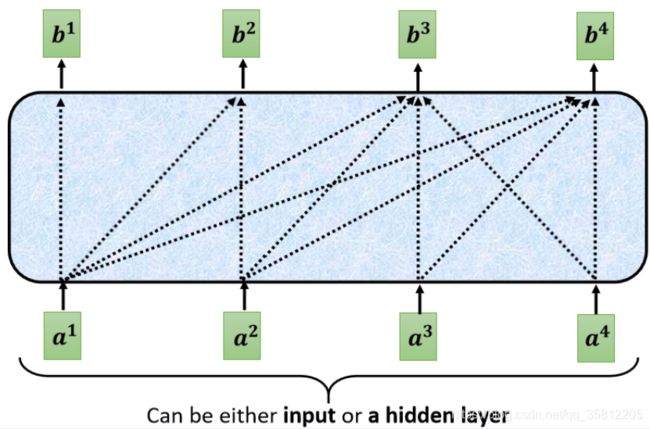
带Masked的MHA
这个 Masked 的意思是这样子的,首先这是我们原来的 Self-Attention



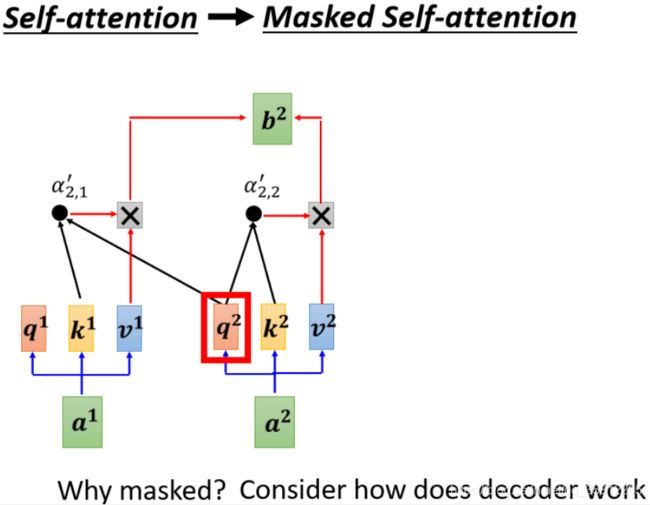

Decoder – Non-autoregressive (NAT)
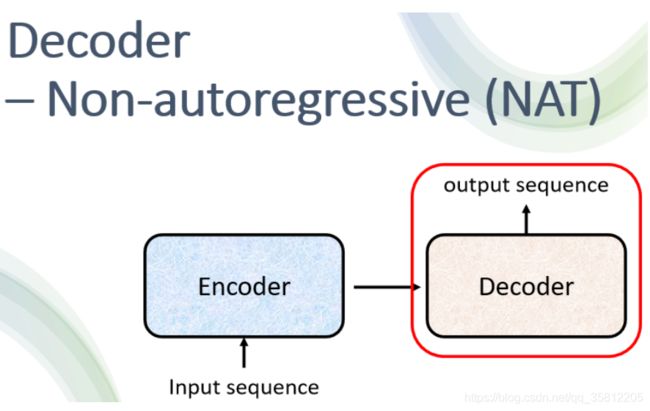

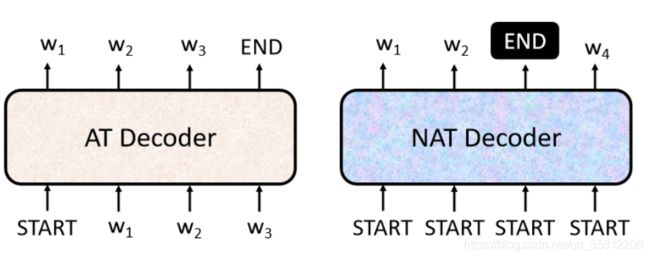
Encoder-Decoder

Cross Attention的运作流程

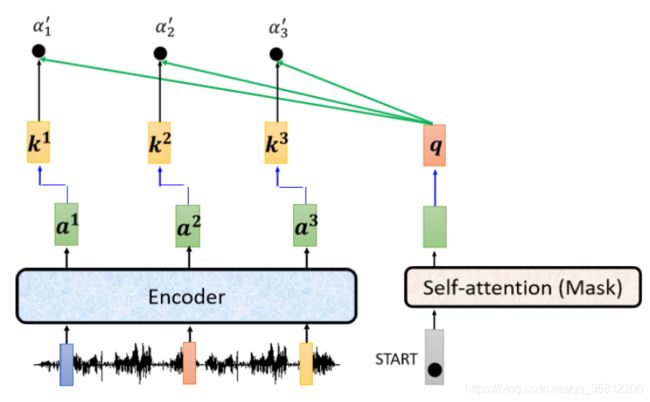


Training


BERT
BERT是一个transformer的Encoder,BERT可以输入一行向量,然后输出另一行向量,输出的长度与输入的长度相同。BERT一般用于自然语言处理,一般来说,它的输入是一串文本。当然,也可以输入语音、图像等“序列”。
BERT只学习了两个“填空”任务。
- 一个是掩盖一些字符,然后要求它填补缺失的字符。
- 预测两个句子是否有顺序关系。
但是,BERT可以被应用在其他的任务【真正想要应用的任务】上,可能与“填空”并无关系甚至完全不同。【胚胎干细胞】当我们想让BERT学习做这些任务时,只需要一些标记的信息,就能够“激发潜能”。
使用BERT的整个过程是连续应用Pre-Train+Fine-Tune,它可以被视为一种半监督方法(semi-supervised learning)
- 当你进行Self-supervised学习时,你使用了大量的无标记数据⇒unsupervised learning
- Downstream Tasks 需要少量的标记数据。
Auto-encoder

本章内容是更深入的学习auto-encoder,主要围绕两方面:
- 为什么一定要minimize reconstruction error,以及有没有其他的方法?
- 如何让encoder的向量更有解释性 ?
评估encoder
一个好的embedding应该包含了关于输入的关键信息,从中我们就可以大致知道输入是什么样的。即希望得到一个关于input有代表性,解释性强的embedding,例如machine知道看到蓝色的耳机,它就会想到三九而不是其他人。

Beyond Reconstruction:Discriminator
然而我们如何知道embedding能否很好的包含输入的特性呢?我们可以训练一个Discriminator(判别器,类似于二分类),输入是一个image和embedding,输出结果是看image和embedding是否是一对。它可以判断图片与code是否匹配,给出一个结果对匹配进行打分。



Typical auto-encoder is a special case

我们把Discriminator的内部架构设计一下:Discriminator接收一个图片和一个vector,vector通过Decoder解码生成一个图片,然后和输入图片进行相减,看它们的接近程度计算分数。
image和vector输入到判别器中,得到的结果score,就是auto-encoder的reconstruction error,即Discriminator得到的结果还是可以认为是最小化重建误差。
如何得到解释性更好的Embedding的方法
Feature Disentangle (特征解耦)


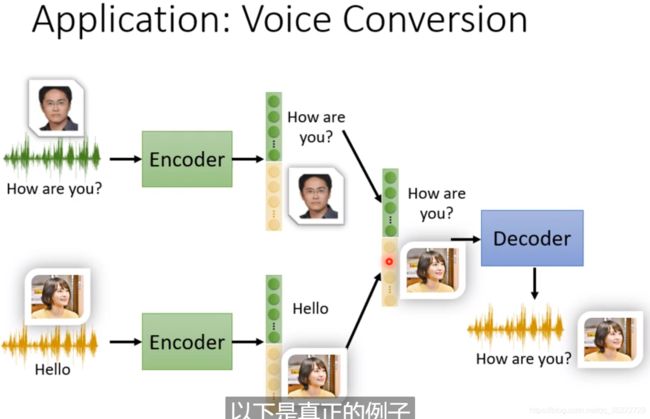
一种是将vector进行划分,以声音讯号为例,假设通过Encoder得到的Embedding是一个200维的向量,它只包含内容和讲话者身份两种信息。前100维是语音信息,而后100维则是语者信息。
一种是直接就训练两个encoder处理不同的信息,可以有两个Encoder,一个负责处理语意内容,一个负责处理说话人的资讯,两个输出再合并给Decoder来做reconstructed。

Discrete Representation
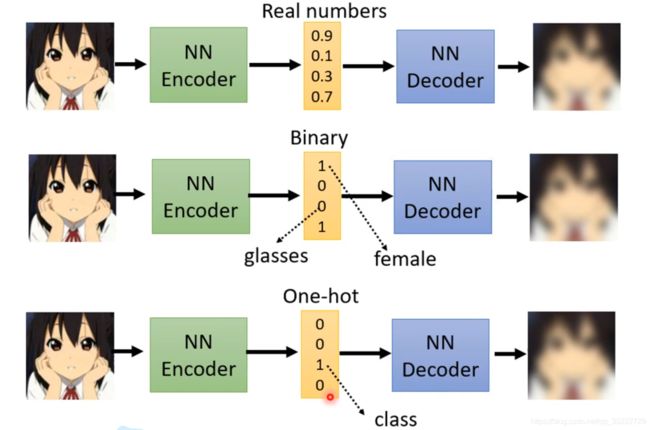
向量的表示有三种可能性: Real Numbers、Binary和One-hot! 比如Binary中某一个值就代表了是不是的问题, 是男的还是女的?戴眼镜了吗? 而One-hot也代表了分类任务,比如0-9手写体的识别!
VQVAE(Vector Quantized Variational Auto-encoder
Codebook中是一系列向量,是学习出来的数据! 同时也是预定义的向量! 我们需要的就是计算Encoder出的向量和Codebook中的相似度,相似度最高的那个向量就作为Decoder的输入! 类似于Self-attention! 当然也可以用在语音识别中,在语音识别中,codebook中的向量完全可以代表kk音标!
