Unet系列+Resnet模型(Pytorch)
Unet系列+Resnet模型(Pytorch)
一.Unet
1.模型简介
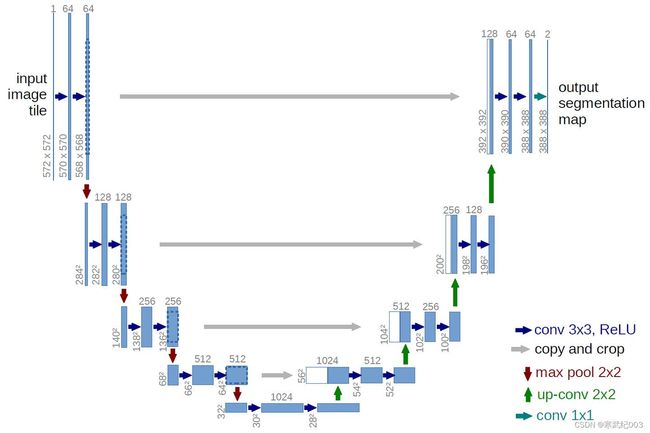
Unet的结构如图所示,网络是一个经典的全卷积网络,模型与FCN类似没有全连接层,但是相比于FCN逐点相加,Unet使用torch.cat将特征在channel维度进行拼接,使得特征可以重复利用达到了更好的图像分割效果。
2.代码实现
为了使得代码简单明了,可以将双卷积单独作为一个Block处理。
import torch
import torch.nn as nn
class VGGBlock(nn.Module):
def __init__(self, in_channels, middle_channels, out_channels):
super().__init__()
self.first = nn.Sequential(
nn.Conv2d(in_channels, middle_channels, 3, padding=1),
nn.BatchNorm2d(middle_channels),
nn.ReLU()
)
self.second = nn.Sequential(
nn.Conv2d(middle_channels, out_channels, 3, padding=1),
nn.BatchNorm2d(out_channels),
nn.ReLU()
)
def forward(self, x):
out = self.first(x)
out = self.second(out)
return out
class UNet(nn.Module):
def __init__(self, num_classes, input_channels=3):
super().__init__()
nb_filter = [64, 128, 256, 512,1024]
self.pool = nn.MaxPool2d(2, 2)
self.up = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)
self.conv0_0 = VGGBlock(input_channels, nb_filter[0], nb_filter[0])
self.conv1_0 = VGGBlock(nb_filter[0], nb_filter[1], nb_filter[1])
self.conv2_0 = VGGBlock(nb_filter[1], nb_filter[2], nb_filter[2])
self.conv3_0 = VGGBlock(nb_filter[2], nb_filter[3], nb_filter[3])
self.conv4_0 = VGGBlock(nb_filter[3], nb_filter[4], nb_filter[4])
self.conv3_1 = VGGBlock(nb_filter[3]+nb_filter[4], nb_filter[3], nb_filter[3])
self.conv2_2 = VGGBlock(nb_filter[2]+nb_filter[3], nb_filter[2], nb_filter[2])
self.conv1_3 = VGGBlock(nb_filter[1]+nb_filter[2], nb_filter[1], nb_filter[1])
self.conv0_4 = VGGBlock(nb_filter[0]+nb_filter[1], nb_filter[0], nb_filter[0])
self.final = nn.Conv2d(nb_filter[0], num_classes, kernel_size=1)
def forward(self, input):
x0_0 = self.conv0_0(input)
x1_0 = self.conv1_0(self.pool(x0_0))
x2_0 = self.conv2_0(self.pool(x1_0))
x3_0 = self.conv3_0(self.pool(x2_0))
x4_0 = self.conv4_0(self.pool(x3_0))
x3_1 = self.conv3_1(torch.cat([x3_0, self.up(x4_0)], 1))
x2_2 = self.conv2_2(torch.cat([x2_0, self.up(x3_1)], 1))
x1_3 = self.conv1_3(torch.cat([x1_0, self.up(x2_2)], 1))
x0_4 = self.conv0_4(torch.cat([x0_0, self.up(x1_3)], 1))
output = self.final(x0_4)
return output
二.Unet++
1.模型简介.
Unet++继承了Unet的结构,最大的改动是在Unet模型的中央添加了稠密连接方式,看起来更像一个巢式结构。有点类似于Densenet。其中还有一个创新点就是可以连接多个Loss,例如X0_4可以输出一个结果,X0_3也可以连接Loss输出结果。
2.代码实现
import torch
import torch.nn as nn
class VGGBlock(nn.Module):
def __init__(self, in_channels, middle_channels, out_channels):
super().__init__()
self.first = nn.Sequential(
nn.Conv2d(in_channels, middle_channels, 3, padding=1,bias = False),
nn.BatchNorm2d(middle_channels),
nn.ReLU(inplace = True)
)
self.second = nn.Sequential(
nn.Conv2d(middle_channels, out_channels, 3, padding=1,bias = False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace = True)
)
def forward(self, x):
out = self.first(x)
out = self.second(out)
return out
class UNetplusplus(nn.Module):
def __init__(self, num_classes, input_channels=3, deep_supervision=False, **kwargs):
super().__init__()
nb_filter = [64, 128, 256, 512,1024]
self.deep_supervision = deep_supervision
self.pool = nn.MaxPool2d(2, 2)
self.up = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)
self.conv0_0 = VGGBlock(input_channels, nb_filter[0], nb_filter[0])
self.conv1_0 = VGGBlock(nb_filter[0], nb_filter[1], nb_filter[1])
self.conv2_0 = VGGBlock(nb_filter[1], nb_filter[2], nb_filter[2])
self.conv3_0 = VGGBlock(nb_filter[2], nb_filter[3], nb_filter[3])
self.conv4_0 = VGGBlock(nb_filter[3], nb_filter[4], nb_filter[4])
self.conv0_1 = VGGBlock(nb_filter[0]+nb_filter[1], nb_filter[0], nb_filter[0])
self.conv1_1 = VGGBlock(nb_filter[1]+nb_filter[2], nb_filter[1], nb_filter[1])
self.conv2_1 = VGGBlock(nb_filter[2]+nb_filter[3], nb_filter[2], nb_filter[2])
self.conv3_1 = VGGBlock(nb_filter[3]+nb_filter[4], nb_filter[3], nb_filter[3])
self.conv0_2 = VGGBlock(nb_filter[0]*2+nb_filter[1], nb_filter[0], nb_filter[0])
self.conv1_2 = VGGBlock(nb_filter[1]*2+nb_filter[2], nb_filter[1], nb_filter[1])
self.conv2_2 = VGGBlock(nb_filter[2]*2+nb_filter[3], nb_filter[2], nb_filter[2])
self.conv0_3 = VGGBlock(nb_filter[0]*3+nb_filter[1], nb_filter[0], nb_filter[0])
self.conv1_3 = VGGBlock(nb_filter[1]*3+nb_filter[2], nb_filter[1], nb_filter[1])
self.conv0_4 = VGGBlock(nb_filter[0]*4+nb_filter[1], nb_filter[0], nb_filter[0])
if self.deep_supervision:
self.final1 = nn.Conv2d(nb_filter[0], num_classes, kernel_size=1)
self.final2 = nn.Conv2d(nb_filter[0], num_classes, kernel_size=1)
self.final3 = nn.Conv2d(nb_filter[0], num_classes, kernel_size=1)
self.final4 = nn.Conv2d(nb_filter[0], num_classes, kernel_size=1)
else:
self.final = nn.Conv2d(nb_filter[0], num_classes, kernel_size=1)
def forward(self, input):
x0_0 = self.conv0_0(input)
x1_0 = self.conv1_0(self.pool(x0_0))
x0_1 = self.conv0_1(torch.cat([x0_0, self.up(x1_0)], 1))
x2_0 = self.conv2_0(self.pool(x1_0))
x1_1 = self.conv1_1(torch.cat([x1_0, self.up(x2_0)], 1))
x0_2 = self.conv0_2(torch.cat([x0_0, x0_1, self.up(x1_1)], 1))
x3_0 = self.conv3_0(self.pool(x2_0))
x2_1 = self.conv2_1(torch.cat([x2_0, self.up(x3_0)], 1))
x1_2 = self.conv1_2(torch.cat([x1_0, x1_1, self.up(x2_1)], 1))
x0_3 = self.conv0_3(torch.cat([x0_0, x0_1, x0_2, self.up(x1_2)], 1))
x4_0 = self.conv4_0(self.pool(x3_0))
x3_1 = self.conv3_1(torch.cat([x3_0, self.up(x4_0)], 1))
x2_2 = self.conv2_2(torch.cat([x2_0, x2_1, self.up(x3_1)], 1))
x1_3 = self.conv1_3(torch.cat([x1_0, x1_1, x1_2, self.up(x2_2)], 1))
x0_4 = self.conv0_4(torch.cat([x0_0, x0_1, x0_2, x0_3, self.up(x1_3)], 1))
if self.deep_supervision: #多个输出
output1 = self.final1(x0_1)
output2 = self.final2(x0_2)
output3 = self.final3(x0_3)
output4 = self.final4(x0_4)
return [output1, output2, output3, output4]
else:
output = self.final(x0_4)
return output
三.Resnet
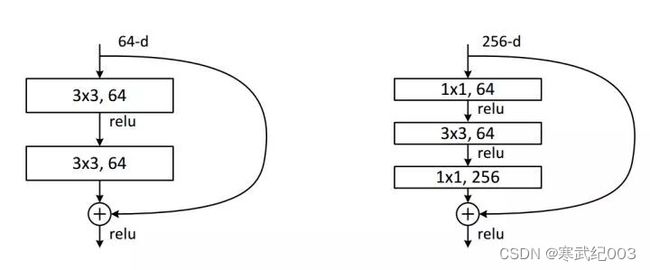
Resnet的模型其实很简单,基本框架就是两部分。BasicBlock(双卷积)以及BottleNeck(三卷积)。当模型超过50层时选用BottleNeck来堆叠网络。另外一个需要注意的点是Resnet是直接相加add,所以相加时应保证channels相同,为保证维度相同可以使用kernel_size等于1的卷积核进行升维。
import torch
import torch.nn as nn
class BasicBlock(nn.Module):
expansion = 1
'''
expansion通道扩充比例
out_channels就是输出的channel
'''
def __init__(self, in_channels, out_channels, stride=1):
super().__init__()
self.residual_function = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride, padding=1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True),
nn.Conv2d(out_channels, out_channels * BasicBlock.expansion, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(out_channels * BasicBlock.expansion)
)
self.shortcut = nn.Sequential()
if stride != 1 or in_channels != BasicBlock.expansion * out_channels:
self.shortcut = nn.Sequential(
nn.Conv2d(in_channels, out_channels * BasicBlock.expansion, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(out_channels * BasicBlock.expansion)
)
def forward(self, x):
return nn.ReLU(inplace=True)(self.residual_function(x) + self.shortcut(x))
class BottleNeck(nn.Module):
expansion = 4
'''
espansion是通道扩充的比例
注意实际输出channel = middle_channels * BottleNeck.expansion
'''
def __init__(self, in_channels, middle_channels, stride=1):
super().__init__()
self.residual_function = nn.Sequential(
nn.Conv2d(in_channels, middle_channels, kernel_size=1, bias=False),
nn.BatchNorm2d(middle_channels),
nn.ReLU(inplace=True),
nn.Conv2d(middle_channels, middle_channels, stride=stride, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(middle_channels),
nn.ReLU(inplace=True),
nn.Conv2d(middle_channels, middle_channels * BottleNeck.expansion, kernel_size=1, bias=False),
nn.BatchNorm2d(middle_channels * BottleNeck.expansion),
)
self.shortcut = nn.Sequential()
if stride != 1 or in_channels != middle_channels * BottleNeck.expansion:
self.shortcut = nn.Sequential(
nn.Conv2d(in_channels, middle_channels * BottleNeck.expansion, stride=stride, kernel_size=1, bias=False),
nn.BatchNorm2d(middle_channels * BottleNeck.expansion)
)
def forward(self, x):
return nn.ReLU(inplace=True)(self.residual_function(x) + self.shortcut(x))
四.Resnet+Unet
参考这位大佬
但是他的模型不支持Resnet50以上的网络,自己对这个模型做了细小的调整。
import torch
import torch.nn as nn
class BasicBlock(nn.Module):
expansion = 1
'''
expansion通道扩充比例
out_channels就是输出的channel
'''
def __init__(self, in_channels, out_channels, stride=1):
super().__init__()
self.residual_function = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride, padding=1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True),
nn.Conv2d(out_channels, out_channels * BasicBlock.expansion, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(out_channels * BasicBlock.expansion)
)
self.shortcut = nn.Sequential()
if stride != 1 or in_channels != BasicBlock.expansion * out_channels:
self.shortcut = nn.Sequential(
nn.Conv2d(in_channels, out_channels * BasicBlock.expansion, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(out_channels * BasicBlock.expansion)
)
def forward(self, x):
return nn.ReLU(inplace=True)(self.residual_function(x) + self.shortcut(x))
class BottleNeck(nn.Module):
expansion = 4
'''
espansion是通道扩充的比例
注意实际输出channel = middle_channels * BottleNeck.expansion
'''
def __init__(self, in_channels, middle_channels, stride=1):
super().__init__()
self.residual_function = nn.Sequential(
nn.Conv2d(in_channels, middle_channels, kernel_size=1, bias=False),
nn.BatchNorm2d(middle_channels),
nn.ReLU(inplace=True),
nn.Conv2d(middle_channels, middle_channels, stride=stride, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(middle_channels),
nn.ReLU(inplace=True),
nn.Conv2d(middle_channels, middle_channels * BottleNeck.expansion, kernel_size=1, bias=False),
nn.BatchNorm2d(middle_channels * BottleNeck.expansion),
)
self.shortcut = nn.Sequential()
if stride != 1 or in_channels != middle_channels * BottleNeck.expansion:
self.shortcut = nn.Sequential(
nn.Conv2d(in_channels, middle_channels * BottleNeck.expansion, stride=stride, kernel_size=1, bias=False),
nn.BatchNorm2d(middle_channels * BottleNeck.expansion)
)
def forward(self, x):
return nn.ReLU(inplace=True)(self.residual_function(x) + self.shortcut(x))
class VGGBlock(nn.Module):
def __init__(self, in_channels, middle_channels, out_channels):
super().__init__()
self.first = nn.Sequential(
nn.Conv2d(in_channels, middle_channels, 3, padding=1),
nn.BatchNorm2d(middle_channels),
nn.ReLU()
)
self.second = nn.Sequential(
nn.Conv2d(middle_channels, out_channels, 3, padding=1),
nn.BatchNorm2d(out_channels),
nn.ReLU()
)
def forward(self, x):
out = self.first(x)
out = self.second(out)
return out
class UResnet(nn.Module):
def __init__(self, block, layers, num_classes, input_channels=3):
super().__init__()
nb_filter = [64, 128, 256, 512, 1024]
self.in_channel = nb_filter[0]
self.pool = nn.MaxPool2d(2, 2)
self.up = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)
self.conv0_0 = VGGBlock(input_channels, nb_filter[0], nb_filter[0])
self.conv1_0 = self._make_layer(block,nb_filter[1], layers[0], 1)
self.conv2_0 = self._make_layer(block,nb_filter[2], layers[1], 1)
self.conv3_0 = self._make_layer(block,nb_filter[3], layers[2], 1)
self.conv4_0 = self._make_layer(block,nb_filter[4], layers[3], 1)
self.conv3_1 = VGGBlock((nb_filter[3] + nb_filter[4]) * block.expansion, nb_filter[3],
nb_filter[3] * block.expansion)
self.conv2_2 = VGGBlock((nb_filter[2] + nb_filter[3]) * block.expansion, nb_filter[2],
nb_filter[2] * block.expansion)
self.conv1_3 = VGGBlock((nb_filter[1] + nb_filter[2]) * block.expansion, nb_filter[1],
nb_filter[1] * block.expansion)
self.conv0_4 = VGGBlock(nb_filter[0] + nb_filter[1] * block.expansion, nb_filter[0], nb_filter[0])
self.final = nn.Conv2d(nb_filter[0], num_classes, kernel_size=1)
def _make_layer(self, block,middle_channel, num_blocks, stride):
'''
middle_channels中间维度,实际输出channels = middle_channels * block.expansion
num_blocks,一个Layer包含block的个数
'''
strides = [stride] + [1] * (num_blocks - 1)
layers = []
for stride in strides:
layers.append(block(self.in_channel, middle_channel, stride))
self.in_channel = middle_channel * block.expansion
return nn.Sequential(*layers)
def forward(self, input):
x0_0 = self.conv0_0(input)
x1_0 = self.conv1_0(self.pool(x0_0))
x2_0 = self.conv2_0(self.pool(x1_0))
x3_0 = self.conv3_0(self.pool(x2_0))
x4_0 = self.conv4_0(self.pool(x3_0))
x3_1 = self.conv3_1(torch.cat([x3_0, self.up(x4_0)], 1))
x2_2 = self.conv2_2(torch.cat([x2_0, self.up(x3_1)], 1))
x1_3 = self.conv1_3(torch.cat([x1_0, self.up(x2_2)], 1))
x0_4 = self.conv0_4(torch.cat([x0_0, self.up(x1_3)], 1))
output = self.final(x0_4)
return output
如果要调用模型
UResnet34 = UResnet(block=BasicBlock,layers=[3,4,6,3],num_classes=2) #这里我是做二分类
UResnet50 = UResnet(block=BottleNeck,layers=[3,4,6,3],num_classes=2)
UReset101 = UResnet(block=BottleNeck,layers=[3,4,23,3],num_classes=2)
UReset152 = UResnet(block=BottleNeck,layers=[3,8,36,3],num_classes=2)
五.Resnet+Unetplusplus
与Unet一样,都是将encode做替换
import torch
from torch import nn
class VGGBlock(nn.Module):
def __init__(self, in_channels, middle_channels, out_channels):
super().__init__()
self.first = nn.Sequential(
nn.Conv2d(in_channels, middle_channels, 3, padding=1,bias=False),
nn.BatchNorm2d(middle_channels),
nn.ReLU(inplace = True)
)
self.second = nn.Sequential(
nn.Conv2d(middle_channels, out_channels, 3, padding=1,bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace = True)
)
def forward(self, x):
out = self.first(x)
out = self.second(out)
return out
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, in_channels, out_channels, stride=1):
super().__init__()
self.residual_function = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride, padding=1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True),
nn.Conv2d(out_channels, out_channels * BasicBlock.expansion, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(out_channels * BasicBlock.expansion)
)
self.shortcut = nn.Sequential()
if stride != 1 or in_channels != BasicBlock.expansion * out_channels:
self.shortcut = nn.Sequential(
nn.Conv2d(in_channels, out_channels * BasicBlock.expansion, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(out_channels * BasicBlock.expansion)
)
def forward(self, x):
return nn.ReLU(inplace=True)(self.residual_function(x) + self.shortcut(x))
class BottleNeck(nn.Module):
expansion = 4
def __init__(self, in_channels, out_channels, stride=1):
super().__init__()
self.residual_function = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True),
nn.Conv2d(out_channels, out_channels, stride=stride, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True),
nn.Conv2d(out_channels, out_channels * BottleNeck.expansion, kernel_size=1, bias=False),
nn.BatchNorm2d(out_channels * BottleNeck.expansion),
)
self.shortcut = nn.Sequential()
if stride != 1 or in_channels != out_channels * BottleNeck.expansion:
self.shortcut = nn.Sequential(
nn.Conv2d(in_channels, out_channels * BottleNeck.expansion, stride=stride, kernel_size=1, bias=False),
nn.BatchNorm2d(out_channels * BottleNeck.expansion)
)
def forward(self, x):
return nn.ReLU(inplace=True)(self.residual_function(x) + self.shortcut(x))
class NestedUResnet(nn.Module):
def __init__(self,block,layers,num_classes, input_channels=3, deep_supervision=False):
super().__init__()
nb_filter = [64, 128, 256, 512, 1024]
self.in_channels = nb_filter[0]
self.relu = nn.ReLU()
self.deep_supervision = deep_supervision
self.pool = nn.MaxPool2d(2, 2)
self.up = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)
self.conv0_0 = VGGBlock(input_channels, nb_filter[0], nb_filter[0])
self.conv1_0 = self._make_layer(block,nb_filter[1],layers[0],1)
self.conv2_0 = self._make_layer(block,nb_filter[2],layers[1],1)
self.conv3_0 = self._make_layer(block,nb_filter[3],layers[2],1)
self.conv4_0 = self._make_layer(block,nb_filter[4],layers[3],1)
self.conv0_1 = VGGBlock(nb_filter[0] + nb_filter[1] * block.expansion, nb_filter[0], nb_filter[0])
self.conv1_1 = VGGBlock((nb_filter[1] +nb_filter[2]) * block.expansion, nb_filter[1], nb_filter[1] * block.expansion)
self.conv2_1 = VGGBlock((nb_filter[2] +nb_filter[3]) * block.expansion, nb_filter[2], nb_filter[2] * block.expansion)
self.conv3_1 = VGGBlock((nb_filter[3] +nb_filter[4]) * block.expansion, nb_filter[3], nb_filter[3] * block.expansion)
self.conv0_2 = VGGBlock(nb_filter[0]*2+nb_filter[1] * block.expansion, nb_filter[0], nb_filter[0])
self.conv1_2 = VGGBlock((nb_filter[1]*2+nb_filter[2]) * block.expansion, nb_filter[1], nb_filter[1] * block.expansion)
self.conv2_2 = VGGBlock((nb_filter[2]*2+nb_filter[3]) * block.expansion, nb_filter[2], nb_filter[2] * block.expansion)
self.conv0_3 = VGGBlock(nb_filter[0]*3+nb_filter[1] * block.expansion, nb_filter[0], nb_filter[0])
self.conv1_3 = VGGBlock((nb_filter[1]*3+nb_filter[2]) * block.expansion, nb_filter[1], nb_filter[1] * block.expansion)
self.conv0_4 = VGGBlock(nb_filter[0]*4+nb_filter[1] * block.expansion, nb_filter[0], nb_filter[0])
if self.deep_supervision:
self.final1 = nn.Conv2d(nb_filter[0], num_classes, kernel_size=1)
self.final2 = nn.Conv2d(nb_filter[0], num_classes, kernel_size=1)
self.final3 = nn.Conv2d(nb_filter[0], num_classes, kernel_size=1)
self.final4 = nn.Conv2d(nb_filter[0], num_classes, kernel_size=1)
else:
self.final = nn.Conv2d(nb_filter[0], num_classes, kernel_size=1)
def _make_layer(self,block, middle_channels, num_blocks, stride):
strides = [stride] + [1] * (num_blocks - 1)
layers = []
for stride in strides:
layers.append(block(self.in_channels, middle_channels, stride))
self.in_channels = middle_channels * block.expansion
return nn.Sequential(*layers)
def forward(self, input):
x0_0 = self.conv0_0(input)
x1_0 = self.conv1_0(self.pool(x0_0))
x0_1 = self.conv0_1(torch.cat([x0_0, self.up(x1_0)], 1))
x2_0 = self.conv2_0(self.pool(x1_0))
x1_1 = self.conv1_1(torch.cat([x1_0, self.up(x2_0)], 1))
x0_2 = self.conv0_2(torch.cat([x0_0, x0_1, self.up(x1_1)], 1))
x3_0 = self.conv3_0(self.pool(x2_0))
x2_1 = self.conv2_1(torch.cat([x2_0, self.up(x3_0)], 1))
x1_2 = self.conv1_2(torch.cat([x1_0, x1_1, self.up(x2_1)], 1))
x0_3 = self.conv0_3(torch.cat([x0_0, x0_1, x0_2, self.up(x1_2)], 1))
x4_0 = self.conv4_0(self.pool(x3_0))
x3_1 = self.conv3_1(torch.cat([x3_0, self.up(x4_0)], 1))
x2_2 = self.conv2_2(torch.cat([x2_0, x2_1, self.up(x3_1)], 1))
x1_3 = self.conv1_3(torch.cat([x1_0, x1_1, x1_2, self.up(x2_2)], 1))
x0_4 = self.conv0_4(torch.cat([x0_0, x0_1, x0_2, x0_3, self.up(x1_3)], 1))
if self.deep_supervision:
output1 = self.final1(x0_1)
output2 = self.final2(x0_2)
output3 = self.final3(x0_3)
output4 = self.final4(x0_4)
return [output1, output2, output3, output4]
else:
output = self.final(x0_4)
return output
六.写在最后
经过测试Unet++效果确实比Unet效果要好,同样以Resnet34作为encoder,Unet++的
IOU相比于Unet稍高。
Unet++的巢结构使得其内部连接更为紧密,同样,单纯的加深网络结构效果并没有
Unet的效果显著,接下来的改进方向可以添加自注意力机制,或许能获得更好的效果。