【学习】auto-encoder、feature disentanglement、discrete representation、anomaly detection
李宏毅深度学习
- 一、auto-encoder
- 1、auto-encoder
- 2、de-nosing auto-encoder
- 二、feature disentanglement
-
- 1、应用:voice conversion声音转换
- 三、discrete representation
-
- 1、VAVAE
-
- embedding也可以是text。
- 四、更多应用
-
-
- compression压缩
- anomaly detection
- 异常检测的应用
- auto-encoder
-
- 五、anomaly detection异常检测
-
- 1、分类
-
- 训练分类器
- 置信度
- 示例框架
- 可能问题
- 无标签资料
- 极大似然
一、auto-encoder
1、auto-encoder
auto-encoder也是使用无标注的资料进行训练。

auto-encoder的概念:
跟cycle GAN的思想很像。encoder的输出vector叫embedding、representation或者code。我们输入高维的图片到encoder里面得到一个低维向量(dimension reduction高维转低维,这个low dim叫做bottleneck瓶颈),然后把这个低维向量用在下游任务。


为什么能够压缩复原图片呢?事实上对于图片来说,不是所有的像素分布都是能组成图片的,只有一些分布是表示图片的。所以我们可以可以用一些低纬度的矩阵表示高纬度的矩阵。

auto-encoder不是一个新的思想。这是以前的一些做法:

2、de-nosing auto-encoder
在原图上加上噪声之后输入到encoder里面,decoder还原的目标是还原原图,也就是要去掉噪声还原图片。
BERT可以看成是一个de-noising auto-encoder:
二、feature disentanglement
Representation includes information of different aspects表示包括不同方面的信息
一段文字/图片/声音信号放到auto-encoder的时候,embedding是混合很多种信号的。feature disentanglement要做的就是分辨出auto-encoder的embedding不同维度的不同信息。


1、应用:voice conversion声音转换
过去:要让两种声音说一样的话,这样不切实际。
现在:两种声音可以不说一样的话,不用同意的语音,就能实现这个转换。

而在feature disentanglement能够分辨内容和说话者信息,那样就能把内容和声音混合了。
三、discrete representation
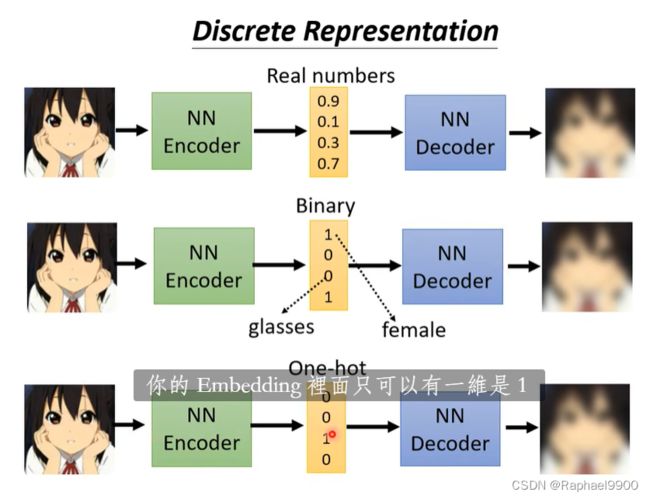
embedding可以是真实数据表示的向量,也可以是二元向量、或者是one-hot向量。
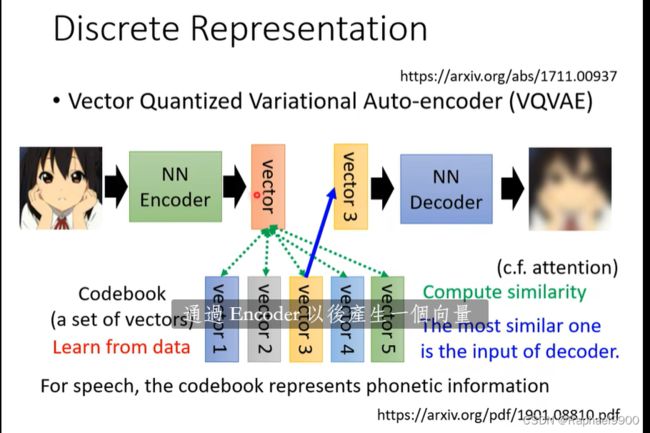
1、VAVAE
把embedding(query)与一个codebook的向量(key)算相似度,最像的一个被选出来输入到decoder里面,然后三个一起训练:encoder、decoder、codebook。
embedding也可以是text。
把文章输入,得到类似的输出,中间的embedding可能是摘要。但是这是不真实的,因为摘要可能是人看不懂的,但是机器可以看懂的。
这些输入可以是大量的无标注文章。

所以我们要让他看人写的摘要,加入discriminator,用RL训练,就变成了cycle GAN了。

实现的比较好的:

表现的不太好:

总结:确实能把一段文字作为embedding。
还有可能是树结构:

四、更多应用
decoder跟generator很像,可以把D当初G用。

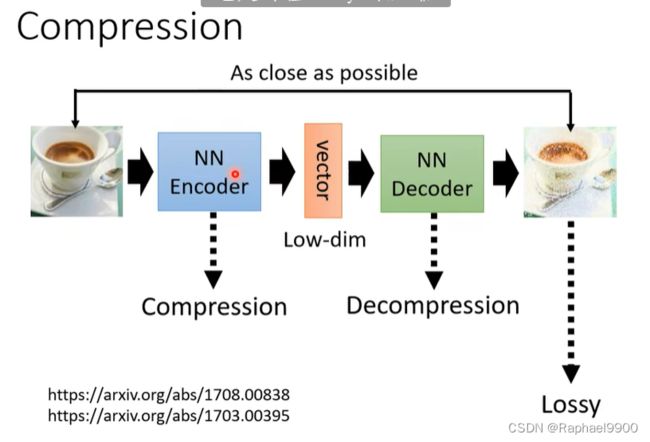
compression压缩
可以把embedding看出是压缩的结果。不过这个输出是会失真的(lossy)。
anomaly detection
给定一组训练数据{x1,x2,…,xN},检测输入x是否类似于训练数据。

没有说某些东西一定是异常的。

异常检测的应用
信用卡诈骗检测、网络入侵检测、癌细胞检测。这样可以做分类任务吗?实际上异常检测是资料是难以收集的,比如异常资料难收集,我们通常只有一个类别的资料。作为分类器是不适合的,但是可以用auto-encoder训练。

auto-encoder
训练的时候希望输入输出越接近越好,但是测试的时候如果发现输入和输出之间的差距很大,那可能就是异常的资料,不能被重建出来,就能用来进行异常检测。

五、anomaly detection异常检测
给定一组训练数据{x1,x2,…,xN},我们希望找到一个函数来检测输入x是否与训练数据相似。


不能当做二元分类的问题:1、异常数据很多,无法被视为一个类别;2、很难找异常类别。
1、分类
(1)输入训练资料x,资料有标签y^,我们希望训练一个分类器识别这些数据并且能够输出“unknown”。
(2)没有标签,资料是干净的(所有资料都是正常的)或者资料是被污染的(混有一点异常资料)。
训练分类器
每个输入x都有一个标注表示这个x是什么。
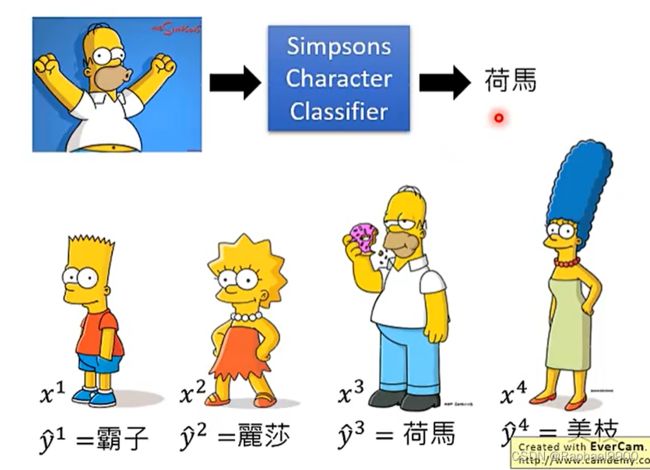
输入x,不仅写出是什么,还输出一个置信度c。置信度门限λ,大于λ的是正常资料,小于的是异常资料。

如果是正常输入,那置信度很高;如果是异常图片,就会输出比较平均的分布。自信度是输出最高的分数。


置信度
训练直接输出置信度的网络(不仅可以输出分布还能输出置信度)。

示例框架
训练集:辛普森一家中人物的x幅图像。每个图像x由它的字符标记y^。训练一个分类器,我们可以从分类器中获得置信度得分c(x)。根据置信度与门限的比较判断这个输入是正常的还是异常的。
dev集:图像x标记每张图片x是否来自辛普森一家。数据有来自辛普森或者不是辛普森。我们可以计算f(x)的performance,使用dev集确定λ和其他超参数。

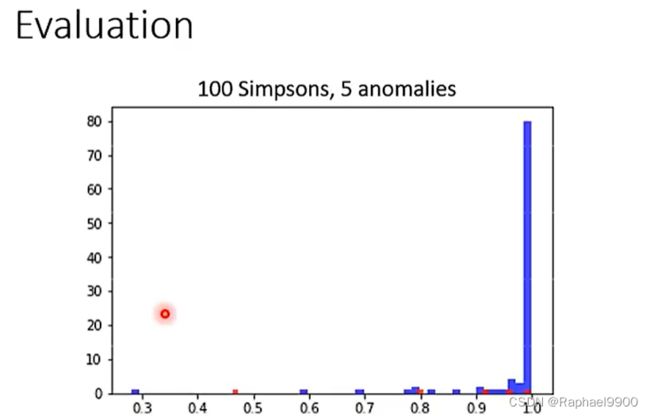
因为正常样本和异常样本分布悬殊,所以准确性不是一个好的衡量标准!一个系统可以有很高的准确率,但是什么都不做。

那用什么判断呢?
错误:正常资料被判定为异常资料(错误警报);异常资料被判断为正常资料(missing)。


这两个移动λ的系统哪个更好?取决于我们认为missing和错误警报哪个更重要。
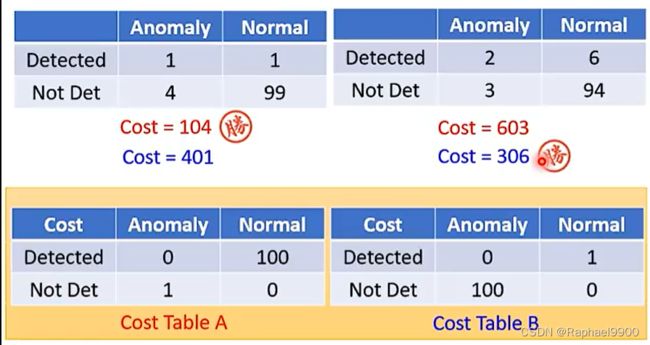
一些评估指标考虑排名。
可能问题
区分猫和狗的类别,不是这个类别的放在线上,其他老虎?

变黄之后,准确度高!

学习分类器:对异常给出低置信度分数
如何获得异常?通过生成模型生成?

无标签资料

给定一组训练数据{x1,x2,…,xN,我们希望找到一个函数来检测输入x是否与训练数据相似。

在没有分类器的时候可以使用P(x)


我们还是需要一个数值化的表示:
极大似然
假设数据点是从概率密度函数fθ (x)中采样的,θ决定了fθ (x)的形状,θ未知,可从数据中找到。

输入:向量x,
输出:决定函数形状的抽样概率密度x
θ决定均值u和协方差矩阵E
高斯分布里面,取样大多出于u附近。
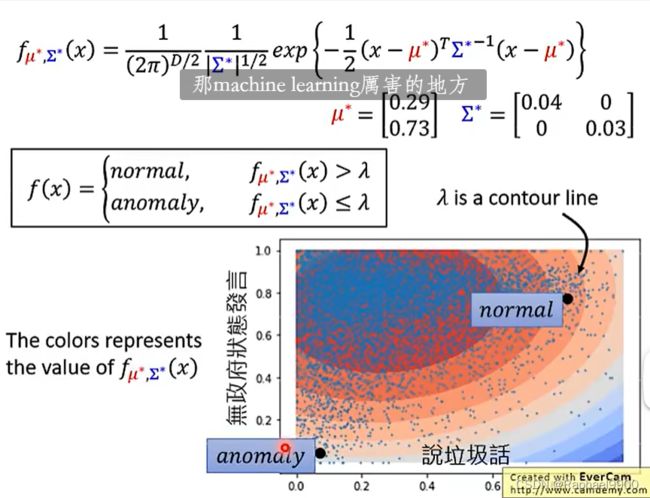
二维比较简单,增加:

可以用auto-encoder做

