基于CNN的图像分类任务
文章目录
- 前言
- 一、导入相关的库
- 二、数据读取
- 三、数据预处理
- 四、继承dataset类
- 五、搭建模型
- 六、训练模型
- 七、保存模型
- 八、测试
- 九、结果
- 写在最后
前言
使用的百度的paddle框架,在AIstudio上面运行本次任务。
# 查看当前挂载的数据集目录, 该目录下的变更重启环境后会自动还原
# View dataset directory.
# This directory will be recovered automatically after resetting environment.
!ls /home/aistudio/data
# 查看工作区文件, 该目录下的变更将会持久保存. 请及时清理不必要的文件, 避免加载过慢.
# View personal work directory.
# All changes under this directory will be kept even after reset.
# Please clean unnecessary files in time to speed up environment loading.
!ls /home/aistudio/work
# 如果需要进行持久化安装, 需要使用持久化路径, 如下方代码示例:
# If a persistence installation is required,
# you need to use the persistence path as the following:
!mkdir /home/aistudio/external-libraries
!pip install beautifulsoup4 -t /home/aistudio/external-libraries
# 同时添加如下代码, 这样每次环境(kernel)启动的时候只要运行下方代码即可:
# Also add the following code,
# so that every time the environment (kernel) starts,
# just run the following code:
import sys
sys.path.append('/home/aistudio/external-libraries')
#解压数据集
!unzip -d work data/data78873/food-11.zip
!rm -rf work/__MACOSX
一、导入相关的库
#导入相关库
import os
import paddle
import paddle.vision.transforms as T
import numpy as np
from PIL import Image
import paddle
import paddle.nn.functional as F
import cv2
from sklearn.utils import shuffle
二、数据读取
# 读取数据
data_path='work/home/aistudio/work/food-11'# 设置初始文件地址
character_folders=os.listdir(data_path)# 查看地址下文件夹
# 每次运行前删除txt,重新新建标签列表
if(os.path.exists('./training_set.txt')):# 判断有误文件
os.remove('./training_set.txt')# 删除文件
if(os.path.exists('./validation_set.txt')):
os.remove('./validation_set.txt')
if(os.path.exists('./testing_set.txt')):
os.remove('./testing_set.txt')
for character_folder in character_folders: #循环文件夹列表
with open(f'./{character_folder}_set.txt', 'a') as f_train:# 新建文档以追加的形式写入
character_imgs = os.listdir(os.path.join(data_path,character_folder))# 读取文件夹下面的内容
count = 0
if character_folder in 'testing':# 检查是否是测试集
for img in character_imgs:# 循环列表
f_train.write(os.path.join(data_path,character_folder,img) + '\n')# 把地址写入文档
count += 1
print(character_folder,count)
else:
for img in character_imgs:# 检查是否是训练集和测试集
f_train.write(os.path.join(data_path,character_folder,img) + '\t' + img[0:img.rfind('_', 1)] + '\n')# 写入地址及标签
count += 1
print(character_folder,count)
三、数据预处理
下面使用paddle.vision.transforms.Compose做数据预处理,主要是这几个部分:
1、以RGB格式加载图片
2、将图片resize,从224x224变成100x100
3、进行transpose操作,从HWC格式转变成CHW格式
4、将图片的所有像素值进行除以255进行归一化
5、对各通道进行减均值、除标准差
img_h, img_w = 100, 100 #适当调整,影响不大
means, stdevs = [], []
img_list = []
imgs_path = 'work/home/aistudio/work/food-11/training'
imgs_path_list = os.listdir(imgs_path)
len_ = len(imgs_path_list)
i = 0
for item in imgs_path_list:
img = cv2.imread(os.path.join(imgs_path,item))
img = cv2.resize(img,(img_w,img_h))
img = img[:, :, :, np.newaxis]
img_list.append(img)
i += 1
# print(i,'/',len_)
imgs_path = 'work/home/aistudio/work/food-11/testing'
imgs_path_list = os.listdir(imgs_path)
len_ = len(imgs_path_list)
i = 0
for item in imgs_path_list:
img = cv2.imread(os.path.join(imgs_path,item))
img = cv2.resize(img,(img_w,img_h))
img = img[:, :, :, np.newaxis]
img_list.append(img)
i += 1
imgs=np.concatenate(img_list,axis=3)
imgs=imgs.astype(np.float32)/255.
for i in range(3):
pixels=imgs[:, :, i, :].ravel() # 拉成一行
means.append(np.mean(pixels))
stdevs.append(np.std(pixels))
# BGR --> RGB , CV读取的需要转换,PIL读取的不用转换
means.reverse()
stdevs.reverse()
print("normMean = {}".format(means))
print("normStd = {}".format(stdevs))
# 只需要执行一次代码记录住数据即可
# normMean = [0.5560434, 0.4515875, 0.34473255]
# normStd = [0.27080873, 0.2738704, 0.280732]
normMean=[0.5560434,0.4515875,0.34473255]
normStd=[0.27080873,0.2738704,0.280732]
# 定义数据预处理
data_transforms = T.Compose([
T.Resize(size=(100,100)),
T.RandomHorizontalFlip(100),
T.RandomVerticalFlip(100),
T.RandomRotation(90),
T.CenterCrop(100),
T.Transpose(),# HWC -> CHW
T.Normalize(
mean=[0.5560434,0.4515875,0.34473255],#归一化 上个模块所求的均值与标准差
std=[0.27080873,0.2738704,0.280732],
to_rgb=True)
#计算过程:output[channel] = (input[channel] - mean[channel]) / std[channel]
])
四、继承dataset类
#继承dataset类
class FoodDataset(paddle.io.Dataset):
"""
数据集类的定义
"""
def __init__(self, mode='training_set'):
"""
初始化函数
"""
self.data = []
with open(f'{mode}_set.txt') as f:
for line in f.readlines():
info = line.strip().split('\t')
if len(info) > 0:
self.data.append([info[0].strip(), info[1].strip()])
def __getitem__(self, index ):
"""
读取图片,对图片进行归一化处理,返回图片和标签
"""
image_file, label = self.data[index] # 获取数据
img = Image.open(image_file).convert('RGB') # 读取图片
return data_transforms(img).astype('float32'),np.array(label, dtype='int64')
def __len__(self):
return len(self.data)
train_dataset = FoodDataset(mode='training')
train_loader = paddle.io.DataLoader(train_dataset, places=paddle.CPUPlace(), batch_size=64, shuffle=True, num_workers=0)
eval_dataset = FoodDataset(mode='training')
val_loader = paddle.io.DataLoader(eval_dataset, places=paddle.CPUPlace(), batch_size=64,shuffle=True, num_workers=0)
#查看训练和验证集数据的大小
print('train size:', train_dataset.__len__())
print('eval size:', eval_dataset.__len__())
五、搭建模型
# 继承paddle.nn.Layer类,用于搭建模型
class MyCNN(paddle.nn.Layer) :
def __init__(self):
super(MyCNN,self).__init__()
self.conv0 = paddle.nn.Conv2D(in_channels=3,out_channels=20,kernel_size=5,padding = 0)
self.pool0 = paddle.nn.MaxPool2D(kernel_size =2, stride =2)#最大池化层
self._batch_norm_0 = paddle.nn.BatchNorm2D(num_features = 20)#归一层
self.conv1 = paddle.nn.Conv2D(in_channels=20,out_channels=50,kernel_size=5,padding=0)
self.pool1 = paddle.nn.MaxPool2D(kernel_size=2,stride = 2)
self._batch_norm_1 = paddle.nn.BatchNorm2D(num_features = 50)
self.conv2 = paddle.nn.Conv2D(in_channels=50,out_channels=50,kernel_size=5,padding=0)
self.pool2 = paddle.nn.MaxPool2D(kernel_size =2,stride = 2)
self.fc1= paddle.nn.Linear(in_features=4050,out_features=218)# 线性层
self.fc2 = paddle.nn.Linear(in_features=218,out_features=100)
self.fc3 = paddle.nn.Linear(in_features=100,out_features=11)
def forward(self,input):
#将输入教据的样子该变成[ 1,3,180,100]
input = paddle.reshape(input,shape=[-1,3,100,100]) #转换维读
# print(input.shape)
x = self.conv0( input)#教据输入卷积层
x = F.relu(x)#激活层
x = self.pool0(x)#池化层
x = self._batch_norm_0(x)#归一层
x = self.conv1(x)
x = F.relu(x)
x = self.pool1(x)
x = self._batch_norm_1(x)
x = self.conv2(x)
x = F.relu(x)
x = self.pool2(x)
x = paddle.reshape(x,[x.shape[0],-1])
# print(x.shape)
x = self.fc1(x)#线性层
x = F.relu(x)
x = self.fc2(x)
x = F.relu(x)
x = self.fc3(x)
#y = F.softmax(x)# 分类器
return x
network = MyCNN() # 模型实例化
六、训练模型
# 训练模型
# 实例化模型
inputs = paddle.static.InputSpec(shape=[None, 3, 100, 100], name='inputs')
labels = paddle.static.InputSpec(shape=[None, 11], name='labels')
model = paddle.Model(network,inputs,labels)
# 模型训练相关配置,准备损失计算方法,优化器和精度计算方法
# 定义优化器
scheduler = paddle.optimizer.lr.LinearWarmup(
learning_rate=0.001, warmup_steps=100, start_lr=0, end_lr=0.001, verbose=True)
optim = paddle.optimizer.SGD(learning_rate=scheduler, parameters=model.parameters())
# 配置模型
model.prepare(
optim,
paddle.nn.CrossEntropyLoss(),
paddle.metric.Accuracy()
)
visualdl = paddle.callbacks.VisualDL(log_dir='visualdl_log')
# 模型训练与评估
model.fit(
train_loader, # 训练数据集
val_loader, # 评估数据集
epochs=1, # 训练的总轮次
batch_size=128, # 训练使用的批大小
verbose=1, # 日志展示形式
callbacks=[visualdl]) # 设置可视化
# 模型评估
model.evaluate(eval_dataset, batch_size=128, verbose=1)
七、保存模型
#保存模型
model.save('finetuning/food') # 保存模型
八、测试
# 测试
def opening(): # 读取图片函数
with open(f'testing_set.txt') as f: # 读取文件夹
test_img = []
txt = []
for line in f.readlines(): # 循环读取每一行
img = Image.open(line[:-1]) # 打开图片
img = data_transforms(img).astype('float32')
txt.append(line[:-1]) # 生成列表
test_img.append(img)
return txt,test_img
img_path, img = opening() # 读取列表
from PIL import Image
model_state_dict = paddle.load('finetuning/food.pdparams') # 读取模型
model = MyCNN() # 实例化模型
model.set_state_dict(model_state_dict)
model.eval()
site = 20 # 读取图片位置
ceshi = model(paddle.to_tensor(img[site])) # 测试
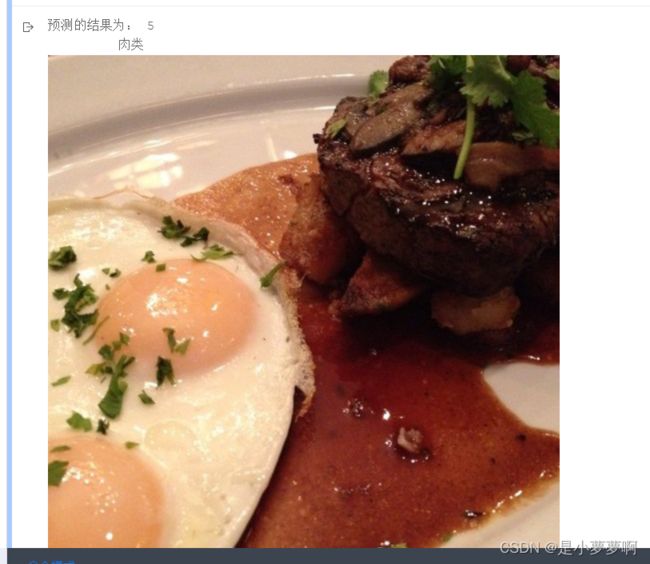
print('预测的结果为:',np.argmax(ceshi.numpy())) # 获取值
value = ["面包","乳制品","甜点","鸡蛋","油炸食品","肉类","面条/意大利面","米饭","海鲜","汤","蔬菜/水果"]
print(' ', value[np.argmax(ceshi.numpy())])
Image.open(img_path[site]) # 显示图片
九、结果
写在最后
仅对个人的深度学习实验做一次记录,文中不足、错误之处欢迎指正;
创作不易,点个赞吧!