使用OpenCV对物体搜索检测与识别
在本教程中,我们将了解对象检测中称为“选择性搜索”的重要概念。我们还将用C ++和Python共享OpenCV代码。
物体检测与物体识别
对象识别算法识别图像中存在哪些对象。它将整个图像作为输入,并输出该图像中存在的对象的类标签和类概率。例如,类标签可以是“狗”,相关的类概率可以是97%。
另一方面,对象检测算法不仅告诉您图像中存在哪些对象,还输出边界框(x,y,宽度,高度)以指示图像内对象的位置。
所有物体检测算法的核心是物体识别算法。假设我们训练了一个物体识别模型,该模型识别图像斑块中的狗。该模型将判断图像中是否有狗。它不会告诉对象的位置。
为了本地化对象,我们必须选择图像的子区域(块),然后将对象识别算法应用于这些图像块。对象的位置由图像块的位置给出,其中对象识别算法返回的类概率高。

生成较小子区域(补丁)的最直接方法称为滑动窗口方法。然而,滑动窗口方法有几个局限性。一类称为“区域提议”算法的算法克服了这些限制。选择性搜索是最受欢迎的区域提案算法之一。
滑动窗口算法
在滑动窗口方法中,我们在图像上滑动框或窗口以选择补丁,并使用对象识别模型对窗口覆盖的每个图像补丁进行分类。它是对整个图像上的对象的详尽搜索。我们不仅需要搜索图像中的所有可能位置,还必须搜索不同的比例。这是因为对象识别模型通常以特定尺度(或尺度范围)进行训练。这导致对数万个图像块进行分类。
问题并没有在这里结束。滑动窗口方法适用于固定宽高比的物体,如面部或行人。图像是3D对象的2D投影。宽高比和形状等对象特征会根据拍摄图像的角度而有很大差异。滑动窗口方法,因为当我们搜索多个宽高比时,计算上非常昂贵。
区域提案算法
到目前为止我们讨论的问题可以使用区域提议算法来解决。这些方法将图像作为输入和输出边界框,对应于图像中最可能是对象的所有面片。这些区域提议可能是嘈杂的,重叠的并且可能不完全包含对象,但是在这些区域提议中,将有一个非常接近图像中的实际对象的提议。然后我们可以使用对象识别模型对这些提议进行分类。具有高概率得分的区域提议是对象的位置。

区域提议算法使用分段识别图像中的预期对象。在分割中,我们基于一些标准(例如颜色,纹理等)将相邻区域彼此相似地分组。与我们在所有像素位置和所有尺度上寻找对象的滑动窗口方法不同,区域建议算法通过以下方式工作:将像素分组为较少数量的段。因此,生成的最终提案数量比滑动窗口方法少很多倍。这减少了我们必须分类的图像补丁的数量。这些生成的区域提议具有不同的比例和宽高比。
区域提案方法的一个重要特性是具有非常高的召回率。这只是一种奇特的说法,即包含我们正在寻找的对象的区域必须在我们的区域提案列表中。为了实现这一点,我们的区域提议列表最终可能会包含许多不包含任何对象的区域。换句话说,区域提议算法可以产生大量的误报,只要它能够捕获所有真正的正数。大多数这些误报将被物体识别算法拒绝。当我们有更多的误报并且精度受到轻微影响时,检测所需的时间就会增加。但是,召回率高仍然是一个好主意,因为错过包含实际对象的区域的替代方案会严重影响检测率。
已经提出了几种区域提议方法,例如
- 对象性
- 用于自动对象分割的约束参数最小割
- 类别独立对象提案
- 随机Prim
- 选择性搜索
在所有这些区域提议方法中,选择性搜索是最常用的,因为它速度快且召回率很高。
选择性搜索对象识别
什么是选择性搜索?
选择性搜索是用于对象检测的区域提议算法。它设计为快速,具有很高的召回率。它基于根据颜色,纹理,大小和形状兼容性计算相似区域的分层分组。
选择性搜索首先使用Felzenszwalb和Huttenlocher 基于图形的分割方法,根据像素的强度对图像进行过度分割。算法的输出如下所示。右侧的图像包含使用纯色表示的分段区域。

中使用分段部分作为区域提案吗?答案是否定的,我们不能这样做有两个原因:
原始图像中的大多数实际对象包含2个或更多分段部分
使用该方法不能产生用于封闭物体的区域建议,例如由杯子覆盖的板或装有咖啡的杯子
如果我们试图通过进一步合并彼此相似的相邻区域来解决第一个问题,那么我们将最终得到一个覆盖两个对象的分段区域。
完美的细分不是我们的目标。我们只想预测许多区域提案,使得其中一些提案应与实际对象具有非常高的重叠。
选择性搜索使用来自Felzenszwalb和Huttenlocher方法的调查作为初始种子。一个过度注释的图像看起来像这样。

选择性搜索算法将这些过量作为初始输入并执行以下步骤
将与分段部件对应的所有边界框添加到区域提案列表中
根据相似性对相邻段进行分组
转到第1步
在每次迭代中,形成更大的段并将其添加到区域提议列表中。因此,我们以自下而上的方式创建从较小的细分市场到较大细分市场的区域提案。这就是我们所说的使用Felzenszwalb和Huttenlocher的计划来计算“分层”分段。

此图显示了分层分段过程的初始,中间和最后一步。
相似
让我们深入探讨如何计算两个区域之间的相似性。
选择性搜索使用基于颜色,纹理,大小和形状兼容性的4种相似性度量。
颜色相似
针对图像的每个通道计算25个区间的颜色直方图,并且连接所有通道的直方图以获得颜色描述符,得到25×3 = 75维颜色描述符。
两个区域的颜色相似性基于直方图交集,可以计算为:
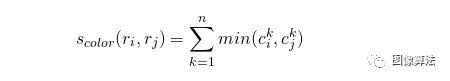
是第颜色描述符中bin 的直方图值
![]()
![]()
纹理相似性
通过为每个通道提取8个方向的高斯导数来计算纹理特征。对于每个方向和每个颜色通道,计算10个箱的直方图,得到10x8x3 = 240维特征描述符。
还使用直方图交叉来计算两个区域的纹理相似性。

大小相似
大小相似性鼓励较小的区域尽早合并。它确保在图像的所有部分形成所有尺度的区域提议。如果不考虑该相似性度量,则单个区域将逐个吞噬所有较小的相邻区域,因此仅在该位置处生成多个尺度的区域提议。大小相似度定义为:

其中大小Size(im)是图像的大小,以像素为单位。
形状兼容性
形状兼容性衡量两个区域(Ri和Rj)相互适合的程度。如果R_I适合r_j我们想合并它们以填补空白,如果它们甚至没有相互接触它们就不应该合并。
形状兼容性定义为:

在哪里大小Size(BBijj)是一个边界框Ri和Rj。
最终相似性
两个区域之间的最终相似性被定义为前述4个相似性的线性组合。
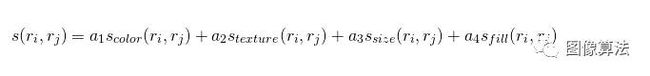
中和是图像中的两个区域或区段,并表示是否使用相似性度量。
![]()
![]()
![]()
结果
OpenCV中的选择性搜索实现提供了按对象性递减顺序排列的数千个区域提议。为清楚起见,我们与图像上方的200-250个框共享结果。一般来说,1000-1200个提案足以获得所有正确的区域提案。


让我们来看看我们如何在OpenCV中使用基于选择性搜索的分段。
选择性搜索:C ++
下面的代码是使用OpenCV进行选择性搜索的C ++教程。请仔细阅读评论以了解代码。
#include "opencv2/ximgproc/segmentation.hpp"
#include "opencv2/highgui.hpp"
#include "opencv2/core.hpp"
#include "opencv2/imgproc.hpp"
#include 选择性搜索:Python
下面的代码是使用OpenCV 3.3进行选择性搜索的Python教程。请注意代码块后提到的OpenCV 3.2的错误警报。请仔细阅读评论以了解代码。
#!/usr/bin/env python
'''
Usage: ./ssearch.py input_image (f|q)
f=fast, q=quality
Use "l" to display less rects, 'm' to display more rects, "q" to quit.
'''
import sys
import cv2
if __name__ == '__main__':
# If image path and f/q is not passed as command
# line arguments, quit and display help message
if len(sys.argv) < 3:
print(__doc__)
sys.exit(1)
# speed-up using multithreads
cv2.setUseOptimized(True);
cv2.setNumThreads(4);
# read image
im = cv2.imread(sys.argv[1])
# resize image
newHeight = 200
newWidth = int(im.shape[1]*200/im.shape[0])
im = cv2.resize(im, (newWidth, newHeight))
# create Selective Search Segmentation Object using default parameters
ss = cv2.ximgproc.segmentation.createSelectiveSearchSegmentation()
# set input image on which we will run segmentation
ss.setBaseImage(im)
# Switch to fast but low recall Selective Search method
if (sys.argv[2] == 'f'):
ss.switchToSelectiveSearchFast()
# Switch to high recall but slow Selective Search method
elif (sys.argv[2] == 'q'):
ss.switchToSelectiveSearchQuality()
# if argument is neither f nor q print help message
else:
print(__doc__)
sys.exit(1)
# run selective search segmentation on input image
rects = ss.process()
print('Total Number of Region Proposals: {}'.format(len(rects)))
# number of region proposals to show
numShowRects = 100
# increment to increase/decrease total number
# of reason proposals to be shown
increment = 50
while True:
# create a copy of original image
imOut = im.copy()
# itereate over all the region proposals
for i, rect in enumerate(rects):
# draw rectangle for region proposal till numShowRects
if (i < numShowRects):
x, y, w, h = rect
cv2.rectangle(imOut, (x, y), (x+w, y+h), (0, 255, 0), 1, cv2.LINE_AA)
else:
break
# show output
cv2.imshow("Output", imOut)
# record key press
k = cv2.waitKey(0) & 0xFF
# m is pressed
if k == 109:
# increase total number of rectangles to show by increment
numShowRects += increment
# l is pressed
elif k == 108 and numShowRects > increment:
# decrease total number of rectangles to show by increment
numShowRects -= increment
# q is pressed
elif k == 113:
break
# close image show window
cv2.destroyAllWindows()