alexnet学习笔记(代码篇)
1.知识回归
01 论文整体框架及神经网络处理图像分类问题的流程
论文整体共包含了九个部分,详细讲的摘要,relu,dropout函数的优点图像分类包含两个阶段训练阶段和测试阶段,softmax,交叉熵
02网络结构及部分参数计算
网络包含5个conv,3个pooling,3个fc(全连接层)
每层网络的featuremap尺寸的计算,参数量的计算,连接数的计算
03网络超参数及训练
网络超参数设置,学习率,batchize等
训练数据产生方式及测试方式
04网络特点
使用了relu激活函数,dropout层,重叠池化,多卡训练,数据增强
2.图像基础知识



图像的像素值一般为0-255,值越大越接近白色,即255图像就是白色,0图像就是黑色。
图片有灰色的也有彩色,灰度图与彩色图的区别在于,灰度图的颜色通道只有一个,而彩色图的颜色通道有三个,它们分别为RGB颜色通道,R代表red红色,G代表green绿色,B代表blue蓝色,如上图,对彩色的lena图片进行分离通道显示,可以看到RGB不同的通道亮度会有所区别,通道值越大越亮,从三张图片可以看出红色通道的值偏大,因为它更亮。从lena的不同通道图可以看到lena彩色图红色的更多一点,红色的分量更大一些。
3.准备工作
代码运行前的准备工作
因为imagenet数据量大,且alexnet参数较多,模型训练耗费时长很久,所以本次实验用训练好的Alexnet权重用其初始化部分层,然后训练一个猫狗分类的模型,这种操作是CNN的重要技巧微调,微调的好处是可以使网络训练的更快,节省时间和资源。
代码所需环境及数据集的下载

所需环境
Python 3
tensorflow>=1.14
Numpy
jupyter notebook
数据集合简介
train data : 25000 images
test data: 12500 images
权重下载
伯克利alexnt.npy二进制权重
4.重点代码
代码结构:finetune.py
主程序,包含了整个工程的完整流程,超参数的设计,优化器创建,以及优化网络
datagenerator.py
数据产生程序,包含了数据的读取与去除均值的操作
alexnet.py
定义了网络的结构,将权重文件的值赋值给张量的操作
validate_alexnet_on_imagenet,ipynd
测试alxndt效果
images文件夹
包含三张测试图片(来源于imagenet数据集合的测试集合)
功能:使用alexnet进行微调
工程名称:featune_alexnet_with_tensorflow
代码的下载链接:
https://github.com/kratzert/finetune_alexnet_with_tensorflow
python 的匿名函数lambda
python 使用lambda关键字创造匿名函数。所谓匿名,通俗的说就是没有名字的函数,意即不再使用def语句这样标准的形式来定义一个函数。
好处:可以使得代码变得简洁美观。
用法:lambda arg1,arg2...argN(参数):expression(表达式)
eg:
import numpy as np
x = np.array([1,2,3,4])
y = np.array([7,8,9,10])
addx_y = lambda x,y:x+y
print(addx_y) # at 0x7fb622ef6f28>
add = addx_y(x,y)
print(add)#[8 10 12 14] 网络结构
import tensorflow as tf
import numpy as np
class AlexNet(object): #定义ALexNet类
def_init_(self,x,keep_prob,num_classes,skip_layer,weights_path='DEFAULT')
self.X = x #输入
self.NUM_CLASSES = num_classes
self.keep_PROB = keep_prob #类别数
self.SKIP_LAYER = skip_layer #跳跃层
if weight_path == 'DEFAULT'
self.WEIGHT_PATH = './bvic_alexnet.npy' #权重文件位置
els:
self.WEIGHTS_PATH = weights_path #网络函数调用
self.create()Keep_PROB也就是dropout层的参数
SKIP_LAYER为不需要使用伯克利权重初始化的层。
网络创造函数creat的调用
def create(self):
conv1 = conv(self.X,11,11,96,4,4,padding ='VALID',name = 'conv1')
norm1 = lrn(conv1,2,2e-05,0.75,name='norm1')
pool1 = max_pool(norm1,3,3,2,2,padding='VALID',name = 'pool1')
conv2 = conv(1,5,5,256,1,1,groups = 2,name = 'conv2')
norm2 = lrn(conv2,2,2e-05,0.75,name='norm2')
pool2 = max_pool(norm2,3,3,2,2,padding='VALID',name = 'pool2')
conv3 = conv(pool2,3,3,384,1,1,name='conv3')
conv4 = conv(conv3,3,3,384,1,1,groups=2,name='conv4')
conv5 = conv(conv4,3,3,256,1,1,groups=2,name='conv5')
pool5 = max_pool(conv5,3,3,2,2,padding='VALID',name = 'pool5')
flattened = tf.reshape([pool5,[-1,6*6*256])
fc6 = fc(flattened,6*6*256,4096,name='fc6')
dropout6 = dropout(fc6,self.KEEP_PROB)
fc7 = fc(dropout6,4096,4096,name='fc7')
dropout7 = dropout(fc7,self.KEEP_PROB)
self.fc8 = fc(droupout7,4096,self.NUM_CLASSES,relu=False,name='fc8')
三个卷积层之后就是maxpooling层,把得到的特征使用reshape函数变成一个向量,然后经过fc6,之后为dropout层,之后是fc7层,使用dropout,fc8为输出层。
def conv(x, filte_height,filter_width,num_filtes,strids_y,stride_x,name,
padding='SAME',groups=1)
input_channels = int(x.get_shape()[-1])
convolve = lambda i,k:tf.nn.conv2d(i,k,strides=[1,stride_y,stride_x,1],
padding=padding)
with tf.variable_scope(name) as scope:
#Create tf variables for the weights and biases of the conv layer
weights = tf.get_variable('weights',shape=[filter_height,
filter_width,
input_channels/groups,
num_filters])
biases = tf.get_variable('biases',shape=[num_filters])
if groups == 1:
conv = convolve(x,weights)
else:
input_groups = tf.split(axis=3,num_or_size_splits = groups,value=x)
weight_groups = tf.split(axis=3,num_or_size_splits = groups,value = weights)
output_groups = [convolve(i,k)for i zip(input_groups,\weight_groups)]
conv = tf.concat(axis = 3,values = output_groups)
relu = tf.nn.relu(bias,name = scope.name)
return relu输入数据x ,卷积核的高度和宽度,卷积核的数量,卷积核的步长,name,卷积的方式为SAME,卷积的组数。
首先获取张量的最后一个维度,也就是特征的通道数,定义一个匿名函数i,k为匿名函数的参数,tf.nn.conv2d为其表达式,也即其实现的功能就是对i,k进行卷积操作。
定义一个名与name相同的命名空间,在整个命名空间下定义了weight & biases变量
然后判断是否进行分组卷积操作,Alexnet不同层的操作分别在两个不同的GPU上进行,为了还原
这个操作,我们把卷积分为两组进行,所以这个地方有一个分组操,若group=1就直接进行卷积操作,否则就将特征图与权重一份二,分别进行卷积,然后进行拼接操作,再进行relu。
命名空间可以更好的管理变量,在tensorboard中显示网络时也更一目了然。
网络结构的可视化
在复杂的问题中,网络往往都是很复杂的。为了方便调试参数以及调整网络结构,我们需要将计算图可视化出来,以便能够更好的进行下一步决策。Tensorboard工具可以满足以上需求。
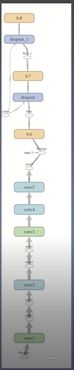
该图详细的解释了alexnet.py程序各个节点的关系,从下往上看,该图清晰的展示了alexnet网络的结构,也可以用这个方法检查自己搭建的网络是否正确。
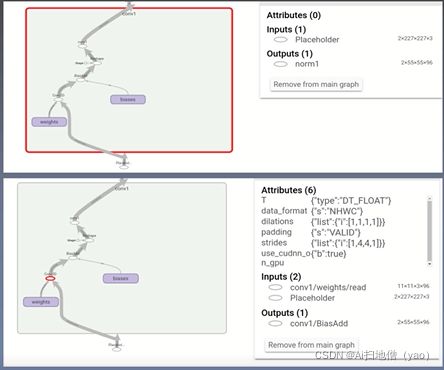
上图(1)是conv1放大之后的结果,可以看到Input为placeholder,输出连接了norm 1,conv1 的小节点 conv2d可以继续细化图(2)详细展示了它细化的内容,这里详细展示了conv2d的具体内容。
tensorflow.data
Dataset API:
tf.data API 可以帮助我们构建灵活高效的输入流水线。
将数据直接放到graph中进行处理,整体对数据集进行数据操纵,使得代码更加简洁。
tensorflow >= 1.40
from tensorflow.data import Dataset 引入方式
根据输入的tensors创建数据集合
data = Dataset.from_tensor_slices((数据tensor,标签tensor))
map使用方式
data = data.map(funtion.num_parallel_calls=4)
function对数据进行操作的函数num_parallel_calls指定并行处理级别(根据cpu性能设置)
prefetch
data = data.prefetch(buffer_size = batch_size * 100)
使数据处理过程高效
合并使用方式
data=
data.map(self._parse_function_train,num_parallel_calls=4).prefetch(100
*batch_size)
常用的功能还有shuffle打乱数据
data = data.shuffle(buffer_size=buff_siza)
buffer_size越大数据越混乱
创建data包含bathsize个images
data = data.batch(batch_size)
batch_size就是批量大小iterator的使用方法
from tensorflow.data import iterator 引入方式
创建一个按照给定数据结构未初始化的迭代器
iterator=lterator.from_structure(数据类型,数据大小)
数据类型比如tf.int64 Tensors, 数据大小一般设置为batchsize大小
获取下一个batchsize的数据
next_batch=iterator.get_next()
初始化数据迭代器
training_init_op = iterator.make_initializer(tr_data.data)
tr_data.data为输入到网络的数据5.训练模型
train data(datagenerator.py)
txt_file:数据列表的路径
mode: 模式
batch_size: 批量大小
num_classes: 数据种类
shuffle:是否进行打乱
buffer_size:缓冲大小
import tensorflow as tf
import numpy as np
import os
from tensorflow.python.framework import dtypes
from tensorflow.data import Dataset
from tensorflow.python.framework.ops import convert_to_tensor
IMAGENET_MEAN = tf.constant([123.68,116.779,103.939],dtype=tf.float32)
class imageDataGenerator(object):
def_init_(self,txt_file,model,batch_size,num_classes,shuffle=True,buffer_size=1000):
self.txt_file = txt_file
self.num_classes = num_classes
#从文件中读取数据read_txt_file()是一个函数
self._read_txt_file()
#数据大小
self.data_size = len(self.labels)
导入必须的包,创建一个imageDataGenerator的类,这个类集成了object类,定义构造函数, self.txt_file是数据的路径。read_txt_file()可以实现从文件中读取数据的功能。调用函数可以获取到self.labels,使用len函数来得到它的长度。
if shuffe:
self._shuffle_lists()
#将列表转换为tensor
self.img_patchs = convert_to_tensor(self.img_patchs, dtype=dtypes.string)
self.labels = convert_to_tensor(self.labels,dtype=dtypes,int32)
#创建数据集合
data = Dataset.from_tensor_slices((self.image_paths,self.labels))
#分训练和推断模式来生成数据
if model == 'training':
data = data.map(self._parse_function_train,num_parallel_calls=4)
data = data.prefetch(buffer_size=batch_size*100)
else model == 'inference'
data = data.map(self._parse_function_inference,num_parallel_calls=4)
data = data.prefetch(buffer_size=batch_size*100)
else:
raise ValueError("invalid model '%s'.%(model))通过传入的参数,判断是否shuffle数据列表,若shuffle为true则打乱否则就不打乱。
self.img_patchs = convert_to_tensor(self.img_patchs, dtype=dtypes.string)
self.labels = convert_to_tensor(self.labels,dtype=dtypes,int32)
以上两个语句将列表转换为tensor,分别将图像路径labels转换为tensor,然后使用dataset创建数据集合,根据参数为training或者inference来决定处理数据的方式,那么就报一个invalid mode错误信息。
#是否打乱缓冲区数据
if shuffle:
data = data.shuffle(buffer_size=buffer_size)
#生成batchsize数据从缓冲区中sample batchsize个数据
data = data.batch(batch_size)
self.data = data然后判断是否打乱缓冲区的数据,最后使用batch函数从缓冲区中选取batchsize个数据生成新的data数据。
主程序 main(finetune.py)
train_file = '/path/to/train.txt' #位置指定训练数据
val_file = '/path/to/val.txt' #定义验证集合数据
learning_rate = 0.01 #定义网络的超参数
num_epochs = 10 #大小等于10
batch_size=128 #批量大小为128,一般把batch_size设置为2的n次方
dropout_rate = 0.5
num_classes = 2 #指定类别数
train_layer = ['fc8','fc7','fc6'] #指定训练的层
display_step = 20 #多久写一次tensorboard
filewriter_patch = "/temp/finetune_alexnet/tensorboard" #指定模型存储位置
checkpoint_path = "/tem/finetune_alexnet/checkpoints"
if not os.path.isdir(checkpoint_path): #判断文件是否存在,若不存在创建
os.mkdir(checkpoint_path)因为是在别人训练好的网络上进行微调,所以不需要将所有层都进行训练,这里是使用了三层进行训练,当train_layers设置为所有层的时候那么所有层都会学习。
with tf.devic('/cpu:0'): #指定运行设备为cpu
tr_data = ImageDataGenerator(train_file, #训练数据路径
mode='training', #训练的模式
batch_size=batch_size, #批量的大小
num_classes=num_classes,#数据类别的多少
shuffle=True) #是否打散数据
val_data = imageDataGenerator(val_file, #获取验证数据
mode='inference'
batch_size='batch_size',
num_classes=num_classes,
shuffle=False)
iterator=iterator.from_structre(tr_data.data.doutput_types, #创建数据迭代器
tr_data.data.output_shapes)
next_batch=iterator.get_next() #获取下一个batch的数据我们通过devic函数来指定运算的设备,比如cpu0,cpu1,gpu0,gpu1等,获取训练数据,需要指定数据的位置,训练模式,batchsize大小,num_classes,以及是否需要打乱,我们在训练模型的时候需要将模型进行打乱,所以shuffle为true,这样训练效果更好,在验证和测试的 时候,网络参数不会更新,所以数据不需要打乱所以shuffle为false,创建一个数据迭代器,通过get_next()获取下一个批量数据。
training_init_op = iterator.make_initialzer(tr_data.data) #初始化数据迭代器
validation_init_op=iterator.make_initializer(val_data.data)
x=tf.placeholder(tf.float32,[batch_size,227,227,3]) #定义输入数据占位符
y=tf.placeholder(tf.float32,[batch_size,num_classes]) #定义类别占位符
keep_prob=tf.placeholder(tf.float32) #定义dropout参数占位符
model=AlexNet(x,keep_prob,num_classes,train_layers) #初始化模型
score-model.fc8 #获取fc8张量
var_list=[v for v in tf.trainable_variables()if v.names.split('/')[0] in train_layers]
#获得可训练变量
with tf.name_scope("cross_entropy")
loss=
tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=score,labels=y))
with tf.name_scope("train"): #获取可训练变量梯度
gradients = tf.gradients(loss,var_list)
gradients = list(zip(gradients,var_list))
optimizer = tf.train.GradientDescentOptimizer(learning_rate) #创建优化器
train_op = optimizer.apply_gradients(grads_and_vars=gradients)#对可训练变量使用梯度下降然后定义三个占位符,第一个为图像的占位符,第二个为标签的占位符,第三个为dropout的占位符 tensorflow的placeholder机制相当于定义了一个位置,这个位置的数据在程序运行时再指定,在程序运行时再赋值,而且占位符不属于变量,不会进行训练,定义占位符的时候必须定义类型,用Alexnet类来实例化了一个model实例,然后获取了网络最后的输出fc8层,定义了损失命名空间cross_entropy,tf.reduce是损失的计算,最后几行是创建网络优化器的过程,获取变量梯度信息,创建优化器,并且使用梯度下降算法对变量进行优化。
with tf.name_scope("accuracy"): #打印时间和epoch信息
correct_pred=tf.equal(tf.argmax(score,1),tf.argmax(y,1)) #初始化参数
accuracy=tf.reduce_mean(tf.cast(correct_pred,tf.float32))#运行步幅迭代
tf.summary.scalar('accuracy',accuracy) #将信息写入到summary
merged_summary=tf.summary.merge_all() #合并所有的summary
writer=tf.summary.FileWriter(filewriter_path) #初始化FileWriter
saver=tf.train.Save() #创建saver对象
train_batches_per_epoch #获取训练数据一轮迭代多少步
=int(np.floor(tr_data.data_size/batch_size))
val_batches_per_epoch #获取验证数据一轮多少步
=int(np.floor(val_data.data_size/batch_size))
with tf.Session() as sess: #创建会话
sess.run(tf.golab_variables_initializer()) #将网络图加载到tensorboard
writer.add_graph(sess.graph)
model.load_initial_weights(sess)
print(*()Start training...*format(datetime.now())) #加载不需要训练层的权重
print(*()Open Tensorboard at --logdir{}*.format(datetime.now(),filewriter_path))创建准确率命名空间,计算正确预测的样本,准确率,将准确率写入到summary,将写入到summary中的东西都合并,并写到filewriter_path里,声明一个tf.train.Saver在之后的持久化变量会用到它,训练数据与验证数据有多少批量,创建会话,进行可训练参数的初始化,这里将变量图加载到tensorboard中,也即将网络结构加载到tensorboard中,初始化需要用到伯克利权重的层,也即为不训练的层,然后打印训练时的时间信息。
for epoch in range(num_epochs):
print(*{}Epoch number:{}*.format(datetime>now(),epoch+1)) #打印时间与epoch信息
sess.run(train_batches_per_epoch): #初始化参数
for step in range(train_batches_per_rpoch): #进行步幅迭代
img_batch,label_batch=sess.run(next_batch) #读取训练数据与标签数据
sess.run(train_op,feed_dict={x:img_batch, #给张量赋值
y:label_batch,
keep_prob:dropout_rate})
if step % display_step == 0:
s=sess.run(merged_summary,feed_dict={x:img_batch, #运行merged_summary
y:label_batch,
keep_prob:1.})
writer.add_summary(s,epoch*train_batches_per_epoch+step) #将信息写入到summary定义网络的迭代过程
进行参数初始化操作,然后获取训练数据和label,之情定义了三个占位符,在这里给占位符传入了数据,feed_dic定义了一一对应的字典,x对应的img_batch也就是批量的数据,y对应的labelbatch,keep_prob对应dropout_rate这个操作就是将数据赋值给对应的占位符,placeholder与feed_dict是一对好朋友,使用了placeholder必须使用feed_dict来给它赋值否则就会报错。

随着epoch的增加准确率越来越高,等到达设定最大的epoch时,程序会自动停止。在主程序中我们将可训练的权重和偏置参数以及它们的梯度写入了summary里,接下来使用tensorboard可视化权重与偏置的分布。

在图中我们可以看到权重与偏置的数据分布及梯度,左上图是数据分布,右上图是梯度分布。
在tensorboard中可以看到模型训练的不同时期,权重与梯度数据分布和它们梯度的变化趋势。
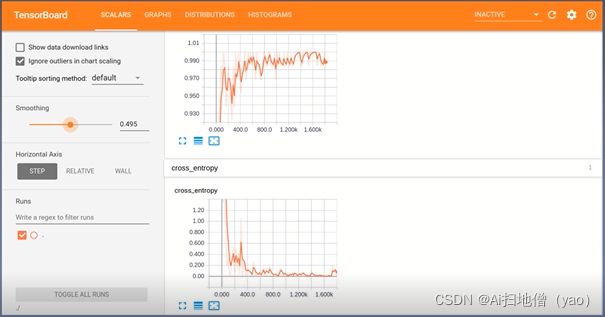
loss与accuracy曲线
通过曲线可以看到,损失函数cross_entropy越来越小,准确率越来越高。可以看到曲线都是有锯齿状,并不是那么平滑,因为网络在训练的时候有不稳定的情况,所以值会有所波动,但它们的总体趋势是没有问题的,这是正常的现象。
6.测试模型
测试的模型为训练好的伯克利权重模型
import... #导入程序所需的包
imagenet_mean=np.arry([104,117,124],dtype=np.float32) #imagenet RGB通道均值
current_dir=os.getcwd() #获取当前程序工作路径
image_dir=os.path.join(image_dir,f) for f in/os.listdir(image_dir) #得到images文件的绝对路径
if f.endswith('.jpeg') #获得所有测试图像的路径
imgs=[] #定义空列表,用来保存数据
for f in img_files: #将测试数据添加到imgs中
imgs.append(cv2.imread(f))
fig = plt.figure(figsize=(15,6))
for i,img in (imgs): #获取imgs列表中数据及其索引
fig.add_subplot(1,3,i+1) #画1*3的图
plt.imshow(cv2.cvtColor(img,cv2.COLOR_BGR2RGB)) #使用plt画图
plt.axis('off') #不显示坐标使用os.getcwd()获得当前工作路径,使用os.path.join将current_dir与images连接,得到images文件夹的绝对路径。使用endswith来判断图片的类型,定义一个imgs的空列表,用来保存图像数据,使用for循环将所有的测试数据添加到列表imgs中获取imgs列表中数据及其索引,生成1*3的画板,使用plt.imshow展示,使用了cv2进行通道转换,因为cv2读出的图像为GBR,而plt.imshow绘制图像数据为RGB,所以画图的同时将图片的通道进行转换。

details: plt.imshow(cv2.cvtColor(img,cv2.COLOR_BGR2RGB))
使用cv2进行通道转换
因为cv2模块读取的图像信息为BGR
plt,imshow绘制图像的通道为RGB
如不转换图像看起来很奇怪。
from alexnet import AlexNet #导入网络
from caffe_classes import class_names #导入1000类物体名称
x=tf.placeholder(tf.float32,[1,227,227,3]) #定义图像占位符
keep_prob=tf.placeholder(tf.float32) #定义dropout参数的占位符
model=AlexNet(x,keep_prob,1000,[]) #定义网络
score=model.fc8 #获取得分
softmax=tf.nn.softmax(score) #计算softmax
with tf.Session() as sess: #创建会话
sess.run(tf.global_variables_initializer()) #初始化变量
model.load_initial_weights(sess) #加载权重
fig2=plt.figure(figsize=(15,6)) #创建画板
images for i, image in (imgs): #获取测试图片
img=cv2.resize(image.astype(np.float32),(227,227)) #将图片变成227*227
img-=imagent_mean #减去均值
img=img.reshape((1,227,227,3)) #变成四维
probs=sess.run(softmax,feed_dict={x:img,keep_prob:1}) #获得结果的概率分布
class_name=class_names[np.argmax(probs)] #输出类别名称
测试结果:第一张图预测的是sea lion置信度是0.9834,第二张图是 liama 置信度为0.9984 最后一张图预测为zebra置信度是1.0000
卷积核可视化

从卷积核可视化的结果可以看出第一层主要学会到一些纹理信息(各种频率和方向的选择性类似于gabor滤波器),以及各种彩色斑点信息

conv2其中一个grop中的一组filter学习到的参数可视化,不能直接的看到学习到了什么内容,层越靠后越抽象。

斑马图经过第一层卷积获得到的特征,从特征可视化结果可以看出卷积核提取出了不同的特征,有些特征斑马比较明显,有些特征背景比较明显,一些纹理比较突出等。
对于神经网络的前几层包含的物体信息比较丰富,越靠后的网络提取出的特征越抽象,包含的语意信息越丰富。
7.总结
网络过拟合------数据增强,dropout
tanth,sigmoid梯度消失训练速度慢----使用非饱和神经元relu,relu6
gpu计算能力不够-------使用多卡训练
训练模型
主函数,网络训练,可视化loss,accuracy
测试模型
如何测试模型的效果,输入图像得到正确分类结果
特征可视化
如何通过可视化查看网络学习到的信息。
实际工程中可能存在的问题
A:如何计算modelsize
(所有参数总和)
B:loss不变化,或者为nan
loss不变化增大学习率,为nan降低学习率
C:一些设计的选择出于实际的考虑
使用卷积层代替全链接层
fc参数太多容易过拟合。