【NIPS 2019】PVCNN:用于高效3D深度学习的点-体素 CNN

文章目录
- Point-Voxel CNN for Efficient 3D Deep Learning
-
- 动机
- PVConv
-
- 基于体素的上分支
- 基于点的下分支
- 特征融合
- 效率(Efficiency)和有效性(Effectiveness)
Point-Voxel CNN for Efficient 3D Deep Learning
https://proceedings.neurips.cc/paper/2019/file/5737034557ef5b8c02c0e46513b98f90-Paper.pdf
动机
硬件因素
设计处理3D数据的深度学习模型需要考虑硬件因素。一方面,与算术运算相比,内存操作消耗更多的能量,而带宽却较低:

另一个方面是内存访问模式,随机访问将引入存储体冲突(bank conflict)并降低了吞吐量:

高效且有效的3D深度学习需要减少内存占用(传统基于体素的方法的瓶颈)以及随机内存访问(传统的基于点的方法的瓶颈)。
体素:
体素表示是有规则的且局部的邻居体素不是随机的。然而,在分辨率较低的情况下,体素化过程中会出现信息丢失:多个点在同一个网格中会被合并在一起。因此,需要一个高分辨率的表示来保留输入数据中的信息。但是,随着体素分辨率的增加,计算成本和所需内存也呈立方体增长。

点:
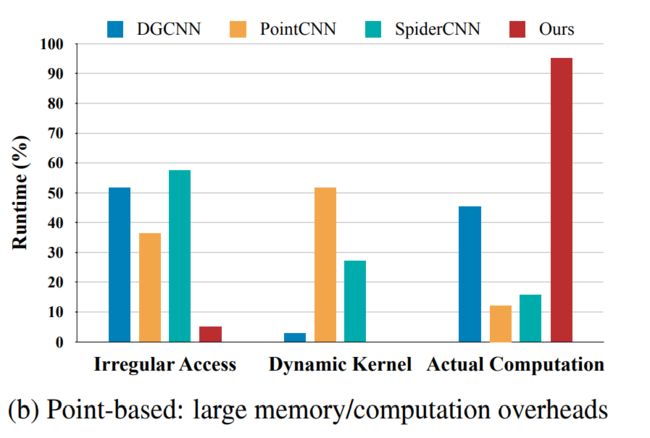
由于点云的稀疏表示,基于点的模型比基于体素的模型需要的GPU内存更低。然而,由于点在整个三维空间中的分布是不规则的;点的邻居是随机的。我们在处理点时会引入随机内存访问(Irregular Access),这是非常低效的。
另一个开销是由动态核(Dynamic Kernel)计算带来的。点不规则地分布在整个三维空间中,因此相邻节点的相对位置不是固定的。有些基于点的模型必须根据不同的偏移量动态生成卷积核,从而需要巨大的时间开销。
PVConv
点-体素卷积(PVConv)结合了基于点的方法(即占用内存小)和基于体素的方法(即良好的数据局部性和规则性)的优点。
PVConv的下分支实现细粒度的(fine-grained)特征转换;上分支实现粗粒度(coarse-grained)的局部特征聚合:
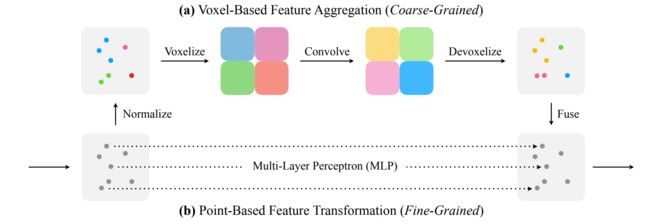
基于体素的上分支
PVConv的基于体素的上分支首先将点转换为低分辨率体素网格,然后通过基于体素的卷积聚集相邻点特征,然后进行去体素化以将其转换回点。
归一化
点坐标 P k {\boldsymbol{P}_k} Pk转换为以重心为原点的局部坐标系。
除以 max ∣ ∣ P k ∣ ∣ 2 \max ||{\boldsymbol{P}_k}||_2 max∣∣Pk∣∣2,然后通过缩放将点转换到 [ 0 , 1 ] [0,1] [0,1]。
体素化
体素化,每个体素单元的特征值为体素内所有点特征的均值。
特征聚合
堆叠的3D卷积+ReLU+BN聚合特征。
去体素化
利用三线性插值将体素网格转换为点,以确保映射到每个点的特征是不同的。
由于体素化和去素化都是可微分的,因此整个基于体素的特征聚合分支可以以端到端方式进行优化。
基于点的下分支
直接对每个点进行操作,使用MLP提取每个点特征。
特征融合
将两个分支的特征相加,用高分辨率的个体点信息补充基于粗粒度体素的信息。
效率(Efficiency)和有效性(Effectiveness)
之前的基于点的方法下采样获取局部特征大都都使用了KNN,这种方式需要收集所有点的邻点,需要至少 O ( k n ) O(kn) O(kn)的随机内存访问,其中 k k k是邻居的数量。一个空间交换时间的方法在最近邻居搜索中对每个中心点复制整个点云,但又导致 O ( n 2 ) O(n^2) O(n2)的内存消耗( n n n为输入点的数量)。
PVConv结合基于点和基于体素的特征提取,能够在无需下采样的同时仍然具有建模邻域信息的能力。PVConv的基于点的下分支被实现为逐点MLP。这样保持了点的高分辨率,避免了下采样导致的信息丢失。基于体素的上分支则通过卷积获取局部特征,这个过程的体素化和去素化都需要遍历所有点一次,将它们分散到相应的体素网格中,所以仅需要 O ( n ) O(n) O(n)的随机内存访问。因此,从这个角度来看,PVCNN效率要高 k × k× k×,实现了更好的数据局部性。在规则的体素进行卷积还意味着PVConv避免了随机内存访问和动态核计算。
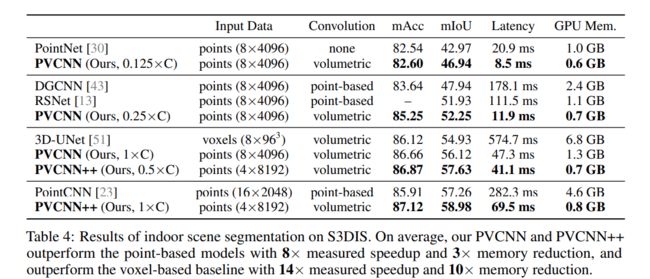
下面给出延迟、GPU内存占用和IoU的对比:
部件分割
PVCNN:用PVConv替换PointNet的MLP。


室内场景分割
PVCNN++:用PVConv替换PointNet++的MLP。

3D目标检测
基于F-PointNet https://arxiv.org/abs/1711.08488。
efficent:PVConv替换实例分割网络的MLP
complete:PVConv替换实例分割和盒估计网络的MLP
