Point-Voxel CNN for Efficient 3D Deep Learning(PVCNN)论文翻译
Point-Voxel CNN for Efficient 3D Deep Learning(PVCNN)
摘要
我们介绍了Point-Voxel CNN(PVCNN),可进行高效,快速的3D深度学习。以前的工作使用基于体素或基于点的NN模型处理3D数据。但是,这两种方法在计算上都是低效的。基于体素的模型的计算成本和内存占用量随输入分辨率的增加而立方增长,从而使其无法扩展分辨率。对于基于点的网络,最多有80%的时间被浪费在构造稀疏数据上,这些稀疏数据的内存局部性很差,而不是实际的特征提取。在本文中,我们提出了以点表示3D输入数据的PVCNN,以减少内存消耗,同时在体素中进行卷积以减少不规则,稀疏数据访问并提高局部性。我们的PVCNN模型在存储和计算效率上都很高。通过对语义和零件细分数据集进行评估,与基于体素的基准相比,它的精度要高得多,并且GPU内存减少了10倍;它也以平均7倍的实测加速性能优于最新的基于点的模型。值得注意的是,较窄版本的PVCNN在零件和场景分割基准上的精度比PointNet(效率极高的模型)高2倍。我们验证了PVCNN在3D对象检测中的一般有效性:通过用PVConv替换Frustrum PointNet中的基本功能,它以1.8倍的实测加速比和1.4倍的GPU内存减少性能比Frustrum PointNet ++高出2.4%。
1. 介绍
3D深度学习由于其广泛的应用而受到越来越多的关注:例如AR / VR和自动驾驶。这些应用程序需要与人们进行实时交互,因此需要低延迟。但是,边缘设备(例如手机和VR耳机)受到硬件资源和电池的严格限制。因此,为边缘上的实时应用设计高效且快速的3D深度学习模型非常重要。
由LiDAR传感器收集的3D数据通常以点云的形式出现。传统上,研究人员将点云栅格化为体素网格并使用3D体积卷积对其进行处理[4,33]。如果分辨率较低,则在体素化期间会丢失信息:如果多个点位于同一网格中,则这些点将合并在一起。因此,需要高分辨率的表示形式来保留输入数据中的精细细节。但是,计算成本和内存要求都随着体素分辨率的增加而三次增加。因此,用高分辨率输入来训练基于体素的模型是不可行的:例如,3D-UNet [51]在64×64×64输入上需要超过10 GB的GPU内存,批处理大小为16,而大型内存占用量很难扩展到超出此分辨率。
最近,另一模型流试图直接处理输入点云[17、23、30、32]。与稀疏表示相比,这些基于点的模型比基于体素的模型所需的GPU内存低得多。但是,他们忽略了以下事实:随机存储器访问效率也很低。由于这些点以不规则的方式散布在整个3D空间中,因此对其进行处理会引入随机内存访问。大多数基于点的模型[23]都模仿3D体积卷积:它们通过聚合每个点的相邻特征来提取每个点的特征。但是,相邻点不会连续存储在点表示中。因此,索引它们需要代价高昂的最近邻居搜索。为了用时间交换空间,以前的方法会在最近的邻居搜索中为每个中心点复制整个点云,然后内存成本将为O(n2),其中n是输入点的数量。动态内核计算引入了另一项开销。由于邻居的相对位置不是固定的,因此这些基于点的模型必须基于不同的偏移量动态生成卷积内核。
设计高效的3D神经网络模型需要考虑硬件。与算术运算相比,存储器运算特别昂贵:它们消耗高两个数量级的能量,而带宽则减小两个数量级(图1a)。另一个方面是内存访问模式:随机访问将引入内存库冲突并降低吞吐量(图1b)。从硬件角度来看,常规3D模型由于内存占用量大和对内存的随机访问而效率低下。
本文提供了克服这些挑战的新颖视角。我们提出了将3D输入数据表示为点云的Point-Voxel CNN(PVCNN),以利用稀疏性减少内存占用,并利用基于体素的卷积来获得连续的内存访问模式。多项任务的广泛实验表明,PVCNN的性能优于基于体素的基线,内存消耗降低了10倍。与最新的基于点的模型相比,它还平均实现了7倍的实测加速。
2. 相关工作
硬件高效的深度学习。面向实际应用的硬件高效深度学习已得到广泛关注。例如,研究人员建议通过修剪和量化模型[7、8、9、24、39、49]或直接设计紧凑模型[11、12、14、25、34、48]来降低内存访问成本。但是,所有这些方法都是通用的,适用于任意神经网络。在本文中,我们取而代之的是根据某些特定于域的属性设计有效的图元:例如3D点云高度稀疏且空间结构化。
基于体素的3D模型。传统上,研究人员依靠体积表示法来处理3D数据[45]。例如,Maturana等。 [27]提出了vanilla volumetric CNN; Qi等 [31]将2D CNN扩展到3D,并系统地分析了3D CNN和多视图CNN之间的关系; Wang等[40]将八叉树合并为大量的CNN,以减少内存消耗。最近的研究表明,体积表示也可以用于3D形状分割[21、37、44]和3D对象检测[50]。
基于点的3D模型。 PointNet [30]利用对称函数来处理3D中的无序点集。后来的研究[17、32、43]提出了对PointNets进行分层堆叠以对邻域信息进行建模并提高模型容量的方法。代替将PointNet作为基本块堆叠,另一种类型的方法[18、23、46]使用动态生成的卷积核或学习到的邻域置换函数来抽象对称函数。其他研究,例如将2D图像SPLAT的概念自然地扩展到3D的SPLATNet [36],以及使用自组织机制并在理论上保证点顺序不变的SONet [22],也显示出巨大的潜力,以点云为输入的目标3D建模。
特殊用途的3D模型。还有针对特定任务量身定制的3D模型。例如,SegCloud [38],SGPN [42],SPGraph [19],ParamConv [41],SSCN [6]和RSNet [13]专用于3D语义/实例分割。对于3D对象检测,F-PointNet [29]基于RGB检测器和基于点的区域建议网络。 PointRCNN [35]在提取RGB检测器时遵循了类似的想法。 PointPillars [20]和SECOND [47]关注效率。
3. 动机
3D数据可以以 ![]()
的格式表示,其中pk是第k个输入点或体素网格的3D坐标,而fk是与pk对应的特征。然后可以将基于体素的卷积和基于点的卷积公式化为
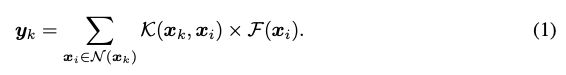
在卷积过程中,我们在整个输入上迭代中心xk。对于每个中心,我们首先在N(xk)中索引其邻居xi,然后将邻近特征F(xi)与核K(xk,xi)卷积,最后产生相应的输出yk。
3.1 基于体素的模型:大量内存占用
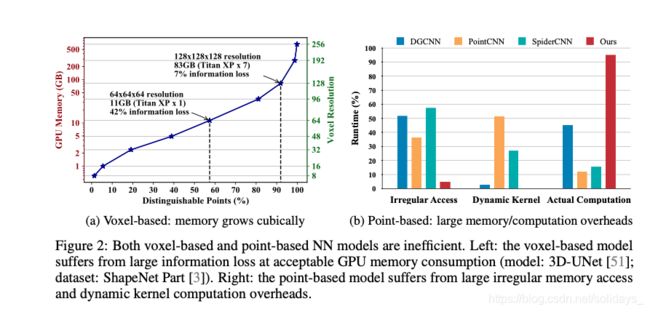
基于体素的表示形式是规则的,并且具有良好的内存局部性。但是,它需要很高的分辨率才能不丢失信息。当分辨率较低时,会将多个点存储到同一体素网格中,并且这些点将不再可区分。仅当一个点仅占据一个体素网格时才保留该点。在图2a中,我们分析了具有不同分辨率的可区分点的数量和内存消耗(在批量大小为16的训练期间)。在单个GPU(具有12 GB内存)上,可承受的最大分辨率为64,这将导致42%的信息丢失(即不可区分的点)。要保留90%以上的信息,我们需要将分辨率提高一倍至128,消耗7.2倍GPU内存(82.6 GB),这对于部署是禁止的。尽管GPU内存随着分辨率的增加而立方增加,但可区分点的数量却减少了。因此,基于体素的解决方案是不可扩展的。
3.2 基于点的模型:不规则的内存访问和动态内核开销
基于点的3D建模方法具有存储效率。最初的尝试,PointNet [30],也是计算有效的,但是它缺乏局部环境的建模功能。后来的研究[23、32、43、46]通过在点域中聚合邻域信息来提高PointNet的表达能力。但是,这将导致不规则的内存访问模式,并引入动态内核计算开销,这成为效率瓶颈。
不规则的内存访问。与基于体素的表示不同,基于点的表示中的相邻点xi∈N(xk)不会在内存中连续放置。此外,3D点散布在R3中;因此,我们需要明确标识谁在相邻集合N(xk)中,而不是通过直接索引。基于点的方法通常将N(xk)定义为坐标空间[23,46]或特征空间[43]中的最近邻居。两者都需要显式且昂贵的KNN计算。在KNN之后,收集N(xk)中的所有邻居xi需要大量随机存储器访问,这对缓存不友好。结合邻居索引和数据移动的成本,我们在图2b中总结出,基于点的模型花费了总运行时间的36%[23],52%[43]和57%[46]来构造不规则数据和随机内存访问。
动态内核计算。对于3D体积卷积,由于相邻xi的相对位置对于不同的中心xk是固定的,因此可以直接对内核K(xk,xi)进行索引:例如,坐标偏移pi-pk的每个轴只能为0,± 1表示卷积,大小为3。但是,对于基于点的卷积,点不规则地散布在整个3D空间中;因此,邻居的相对位置变得不可预测,我们将不得不动态计算每个邻居xi的核K(xk,xi)。例如,SpiderCNN [46]利用三阶泰勒展开作为核K(xk,xi)的连续逼近; PointCNN [23]使用特征转换器F(xi)将相邻点排列为标准顺序。两者都会引入额外的矩阵乘法。从经验上看,我们发现对于PointCNN,动态内核计算的开销可以超过50%(见图2b)!
总之,不规则内存访问和动态内核计算的总开销在55%(对于DGCNN)到88%(对于PointCNN)之间,这表明大多数计算都浪费在处理基于点的表示形式的不规则性上。
4. 点-体素卷积
基于对瓶颈的分析,我们介绍了一种用于3D深度学习的硬件高效构想:点体素卷积(PVConv),它结合了基于点的方法(即较小的内存占用)和基于体素的方法(即良好的数据局部性和规律性)。
我们的PVConv可以分解细粒度的特征转换和粗粒度的领域聚合,从而可以高效地实现每个分支。如图3所示,上部的基于体素的分支首先将这些点转换为低分辨率的体素网格,然后通过基于体素的卷积将相邻点聚合在一起,然后将解体素化(devoxelization)将其转换回点云。体素(evoxelization)或解体素化(deevoxelization)都需要对所有点进行一次扫描,从而降低了内存成本。基于低点的分支为每个单独的点提取特征。由于它不会汇总邻居的信息,因此可以提供非常高的分辨率。
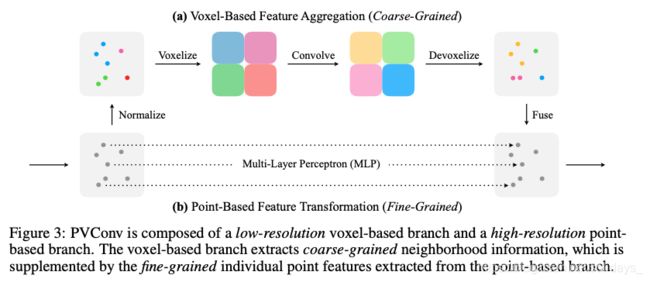
4.1 基于顶点的特征聚合
卷积的关键部分是聚集相邻信息以提取局部特征。由于其规律性,我们选择在体积域中执行此功能聚合。
归一化。不同点云的规模可能会明显不同。因此,我们在将点云转换为体积域之前将坐标{pk}归一化。首先,我们将所有点转换为以重心为原点的局部坐标系。之后,通过将所有坐标除以![]()
,将点归一化为单位球面,然后缩放并将点转换为[0,1]。注意,点特征{fk}在规范化期间保持不变。我们将归一化坐标表示为{pkˆ}。
体素化。通过将坐标为![]()
落入体素网格(u,v,w)中的所有特征fk平均,将归一化点云![]()
转换为体素网格
![]()
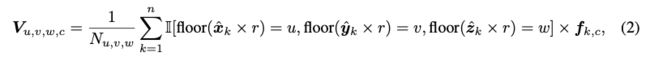
其中,r表示为体素分辨率,I[·] 是pkˆ是否属于体素网格(u,v,w)的二进制指标,![]()
表示与pkˆ相关的第c个通道特征, Nu,v,w 是归一化因子(即落在该体素网格中的点数)。由于体素分辨率r不必很大就可以在我们的公式中有效(这将在第5节中证明),因此体素化表示不会引入很大的内存占用。
特征聚合。将点转换为体素网格后,我们应用3D体积卷积堆叠来聚合特征。类似于常规3D模型,我们在每个3D卷积之后应用批归一化(batch normalization)[15]和非线性激活函数[26]。
解体素化。由于我们需要将信息与基于点的特征转换分支合并在一起,因此我们将基于体素的特征转换回点云域。体素到点映射的直接实现是最近邻插值(即,将网格的特征分配给落入网格的所有点)。但是,这将使同一体素网格中的点始终共享相同的特征。因此,我们改为利用三线性插值将体素网格转换为点,以确保映射到每个点的特征是不同的。
由于我们的体素化和解体素化都是可微的,因此可以以端到端的方式优化整个基于体素的特征聚集分支。
4.2 基于点的特征转换
基于体素的特征聚合分支以粗粒度融合邻域信息。但是,为了建模更细粒度的单个点特征,仅基于低分辨率体素的方法可能不够。为此,我们直接对每个点进行操作以使用MLP提取单个点特征。尽管很简单,但是MLP为每个点输出了不同的和具有区别性的特征。这样的高分辨率单点信息对于补充基于粗体素的信息非常关键。
4.3 特征合并
既具有单个点特征又具有聚集的邻域信息,我们可以有效地融合两个分支,并在它们提供补充信息时对其进行附加。
4.4 讨论
效率:更好的数据局部性和规则性。我们的PVConv比传统的基于点的卷积效率更高,这是因为它具有更好的数据局部性和规则性。我们建议的体素化和解体素化都需要O(n)个随机内存访问,其中n是点的数量,因为我们只需要遍历所有点一次即可将它们分散到其对应的体素网格。但是,对于常规的基于点的方法,收集所有点的邻居至少需要O(kn)个随机内存访问,其中k是邻居的数量。因此,从这个角度来看,我们的PVCNN效率提高了k倍。由于PointNet ++ [32]中k的典型值为32/64,而PointCNN [23]中k的典型值为16,因此,根据我们的设计,我们可以通过经验将不连续的内存访问次数减少16倍至64倍,并获得更好的数据局部性。此外,由于我们的卷积是在常规的体素域中完成的,因此我们的PVConv不需要KNN计算和动态内核计算,它们通常非常昂贵。
有效性:保持高分辨率。由于我们的基于点的特征提取分支被实现为MLP,因此自然的优势在于,我们能够在整个网络中维护相同数量的点,同时仍然具有对邻域信息进行建模的能力。让我们在PointNet ++ [32]中的PVConv和集合抽象(SA)模块之间进行比较。假设我们有2048个点的批次,具有64通道特征(批次大小为16)。我们考虑汇总来自每个点的125个邻居的信息,并对汇总后的要素进行变换,以输出相同大小的要素。 SA模块将需要75.2毫秒的延迟和3.6 GB的内存消耗,而我们的PVConv仅需要25.7毫秒的延迟和1.0 GB的内存消耗。 SA模块将必须下采样至685点(即约3倍的下采样),以匹配我们PVConv的延迟,而内存消耗仍将高出1.5倍。因此,在相同的延迟下,我们的PVConv能够对整个点云进行建模,而SA模块则必须积极地对输入进行下采样,这不可避免地会导致信息丢失。因此,与基于点的同行相比,我们的PVCNN更有效。
5. 实验
我们尝试了多种3D任务,包括对象部分分割,室内场景分割和3D对象检测。我们的PVCNN在所有这些任务上均实现了卓越的性能,并具有更低的测量延迟和GPU内存消耗。附录中提供了更多详细信息。
5.1 物体部分分割
设置。我们首先对大型3D对象数据集ShapeNet Parts [3]进行实验。为了公平地比较,我们遵循与Li[23]和Graham [6]等人相同的评估标准,评估指标是mean intersection-over-union(mIoU):我们首先为2874个测试模型中的每一个计算部分平均IoU,然后将这些值取平均值作为最终指标。此外,我们报告了单个GTX 1080Ti GPU上测得的延迟和GPU内存消耗,以反映效率。我们确保输入数据的大小相同,为2048点,批处理大小为8。
模型。我们通过用PVConv层替换PointNet [30]中的MLP层来构建PVCNN。我们采用PointNet [30],RSNet [13],PointNet ++ [32](具有多尺度分组),DGCNN [43],SpiderCNN [46]和PointCNN [23]作为基于点的基线(baselines)。我们将3D-UNet [51]重新实现为基于体素的基线(baseline)。请注意,大多数基准都将其实施公开发布,因此我们从其官方实施中收集统计信息。
结果。如表1所示,我们的PVCNN优于所有以前的模型。与PointNet ++相比,PVCNN直接以2.5%的开销直接提高了其骨干(PointNet)的准确性。我们还通过将通道数减少到25%(表示为0.25×C)和50%(表示为0.5×C)来设计更窄版本的PVCNN。生成的模型仅需要PointNet的53.5%的延迟,并且它仍然优于具有复杂邻域聚合的几种基于点的方法,包括RSNet,PointNet ++和DGCNN,它们的速度要慢将近一个数量级。
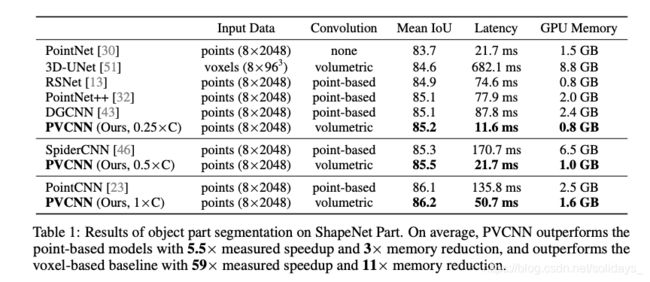
在图4中,与所有基于点的方法相比,PVCNN实现了更好的精度与延迟权衡的平衡。以相似的精度,我们的PVCNN比SpiderCNN快15倍,比PointCNN快2.7倍。与现代基于体素的基准相比,我们的PVCNN在内存折衷方面也实现了明显更高的精度。与3D-UNet相比,PVCNN具有更好的精度,可将GPU内存消耗节省10倍。
此外,我们还测量了三个边缘设备(edge devices)上PVCNN的延迟。在图5中,PVCNN在不同设备上始终通过PointNet和PointCNN实现了2倍的加速。特别是,PVCNN能够在PointNet++级精度的Jetson Nano上以每秒19.9个对象的速度运行,在PointCNN级精度的Jetson Xavier上以每秒20.2个对象的速度运行。

分析。常规的基于体素的方法会随着输入分辨率的提高而使性能达到饱和,但是内存消耗却呈三次增长。 PVCNN效率更高,并且内存以次线性方式增加(表2)。通过将分辨率从16(0.5×R)增加到32(1×R),GPU内存使用量从1.55 GB增加到1.59 GB,仅为1.03×。即使我们将体积分辨率压缩到16(0.5×R),我们的方法仍然仍然优于3D-UNet,后者具有更高的体素分辨率(96)较大幅度(1%)。由于高分辨率的基于点的分支保留了各个点的信息,因此即使在体素分支中分辨率较低的情况下,PVCNN也非常强大。我们还在表3中比较了不同的devoxelization实现。三线性插值的性能优于最近的邻域,这是因为体素边界附近的点将为梯度引入更大的波动,从而使其难以优化。

可视化。我们在图6中说明了最终PVConv的体素和点分支特征,其中较暖的颜色表示较大的幅度。我们可以看到体素分支捕获了较大的连续零件(例如,桌面,灯头),而点分支捕获了孤立的,不连续的细节(例如,桌腿,灯颈)。这两个分支提供了补充信息,并且可以用卷积运算提取具有连续性和局部性的特征这一事实来解释。

5.2 室内场景分割
设置。我们对大型室内场景分割数据集S3DIS [1、2]进行实验。我们遵循Tchapmi等[38]和李等[23]在区域1,2,3,4,6上训练模型并在区域5上对其进行测试,因为它是唯一不与任何其他区域重叠的区域。为了公平比较,数据处理和评估协议都与PointCNN [23]相同。在单个GTX 1080Ti GPU上,我们在测试时以每批32768点的方式测量延迟和内存消耗。
模型。除了PVCNN(基于PointNet)之外,我们还使用PVConv扩展PointNet ++ [32]以构建PVCNN ++。我们将两个模型与最新的基于点的模型[13、23、30、43]和基于体素的基线[51]进行比较。
结果。如表4所示,PVCNN在mIoU方面将其骨干网(PointNet)提高了13%以上,并且在准确性和延迟方面都大大优于DGCNN(涉及复杂的图形卷积)。值得注意的是,在mIoU中,我们的PVCNN ++优于最新的基于点的模型(PointCNN)1.7%,延迟降低了4倍;在mIoU中,基于体素的基线(3D-UNet)的性能比其高出4%。延迟降低8倍,GPU内存消耗降低。
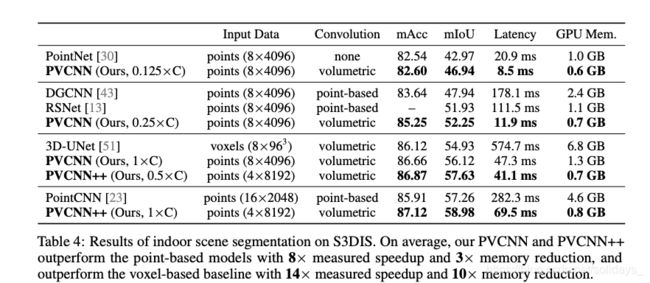
与对象部分分割类似,我们通过将PVCNN中的通道数减少到12.5%,25%和50%,将PVCNN ++的通道数减少到50%,设计紧凑模型。值得注意的是,我们的PVCNN的较窄版本在测得的加速比为15倍时优于DGCNN,在测得的加速比为9倍时优于RSNet。此外,在PointNet上,它的mIoU提升了4%,但仍比该极其有效的模型(不具有任何邻域聚合)快2.5倍。
5.3 3D对象检测
设置。最后,我们在面向驾驶的数据集KITTI [5]上进行了实验。我们遵循Qi等[29]从训练集构造值集,以便在值集中没有实例属于任何训练实例的同一视频剪辑。 val集的大小为3769,其余3711个样本需要训练。我们评估所有模型20次,并报告平均3D平均精度(AP)。
模型。我们通过使用PVConv原语替换实例细分网络中的MLP层,基于F-PointNet [29]构建F-PVCNN,并保持框提案和优化网络不变。我们将模型与F-PointNet(其骨干是PointNet ++)和F-PointNet ++(其骨干是PointNet ++)进行了比较。我们根据复制情况报告其结果。
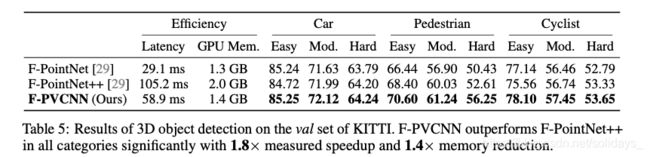
结果。在表5中,即使我们的F-PVCNN模型没有在框估计网络中汇总相邻特征,而F-PointNet ++却在所有估计值上都比后者低了1.8倍。具体而言,我们的模型在最具挑战性的行人阶层中实现了2.4%的平均mAP改善。与F-PointNet相比,我们的F-PVCNN在行人中的mAP改善高达4-5%,这表明我们提出的模型既高效又富有表现力。
6. 结论
我们建议使用Point-Voxel CNN(PVCNN)进行快速,高效的3D深度学习。我们将两全其美:体素和点,减少了内存占用和不规则的内存访问。我们用稀疏的不规则点表示有效地表示3D输入数据,并在密集的规则体素表示中有效地执行卷积。在多个任务上的大量实验一致地证明了我们提出的方法的有效性和效率。我们相信,我们的研究将打破基于体素的卷积本质上效率低下的刻板印象,并为共同设计基于体素和基于点的网络体系结构提供启示。
致谢。我们感谢麻省理工学院的智囊团,麻省理工学院的IBM Watson AI Lab,三星,Facebook和SONY对这项研究的支持。我们还感谢AWS机器学习研究奖提供的计算资源,以及NVIDIA捐赠了Jetson AGX Xavier。