三维图像分类、语义分割和重建
三维图像分类、语义分割和重建
- 引言
- 1 三维数据的深度学习原理
-
- 1.1 三维数据表示方法
- 1.2 神经网络的优势
-
- 1.2.1 三维图的构成
- 1.2.2 多视觉图像
- 1.2.3 点云
- 1.2.4 图模型
- 1.3 图像分类和语义分割
- 1.4 三维重建
-
- 1.4.1 问题陈述和分类
- 1.4.2 常用的算法介绍
- 2 案例分析
-
- 2.1 分类和分割网络
-
- 2.1.1 cycleGAN
- 2.1.2 pointNet 和pointNet++分类和语义分割
- 2.2 重建网络
- 参考文献
引言
随着自动驾驶、机器人等技术的发展,需要知道空间物体的具体三维信息:位置、形状和状态估计等,因此三维方面的深度学习具有一个较大的发展空间,下面主要对于空间三维物体识别以及重建进行简单回顾,后面会进一步更新和充实完善,希望各位大佬不惜赐教。
1 三维数据的深度学习原理
1.1 三维数据表示方法
point cloud 、Mesh、Voxel和Multi-View Images等

图 1.1 三维模型的表示方法 (来源:stanford bunny)
1.2 神经网络的优势
对于二维图像卷积网络CNN具有极大的优势,其能够高效的提取图像特征并得到非常好的结果。当图像转化为三维的时候其主要问题如下:
- 二维图像=二维矩阵,三维图像=无序的点+非结构化网络+大矩阵空间,这时候采用CNN的深度学习空间将面临训练慢,最主要是无序性导致没办法训练。且当其空间姿态变化之后,也将会引起较大的变化。
- 数据集的多样性,实际场景中物体多种多样,点云大小差距也很大,模型能否处理不同尺度的点云面临非常大的挑战,且点云数据集较二维图像少
对于这样一个复杂的问题,我们怎么发挥神经网络的优势呢,我们回顾一下神经网络具有什么优势:
| 表1.1 非线性神经元模型 |
|---|
 |
神经网络从人的神经元类似推理出来的,其具有非线性、非参数统计推断、适应性、证据响应、背景信息、容错性、VLSI实现和分析和设计的一致性。目前演变出来的学习方法都是类比于人脑的运作机制给予一个具体的数学表达,学习过程大概有:误差修正学习、给予记忆的学习、Hebb学习、竞争学习、Boltzmann学习、有教师学习、无教师学习、自适应学习、记忆、统计学习等方法,有一个较为成熟的框架,具体可以看《神经网络原理》非常经典的书。我们需要给予一个合理的模型框架,充分发挥神经网络的特长,上面提到的三维图像的问题或许就不是问题了,只是我们要合理利用神经进行一些尝试:
- 从结构构图入手,结构通常都可以认为是基本几何:圆柱、多面体和球等空间构成,基于此是否可以搭建一个较为成熟的神经网络
- 既然具有无序性,神经网络具有处理这种无序性的能力,那我们就构件一个神经网络去学习无序性,如:pointCNN
- 三维结构的点和线类似于无向图,我们可以通过图的方法去学习结构的特征,如:GNN
- 。。。。
这些方法都有在相关论文中看到,当然有很多方法,非常希望各位大佬进行补充指点。
1.2.1 三维图的构成
我们通常看到一个物体第一反映通常是其是方、圆的或者其他形状的,并能快速判断其是由什么形状进行布尔运算得到的,就像我们学习绘画设计,物体的通常都是由基本的形体拼接而成,这个问题主要问题和解决方法以及优势如下:
主要问题:

1.2.2 多视觉图像
当对于物体我们采用不同的视角采集信息,总能够将一个物体很好的分类,所以其核心思想是采用物体多视觉下的图片来表征三维物体,但其也有较明显的问题:
主要问题:
- 由于视觉的遮挡我们很难无限制的采集多视觉的信息,且对于大场景其问题更加明显
- 二维图片本身缺乏三维结构的信息
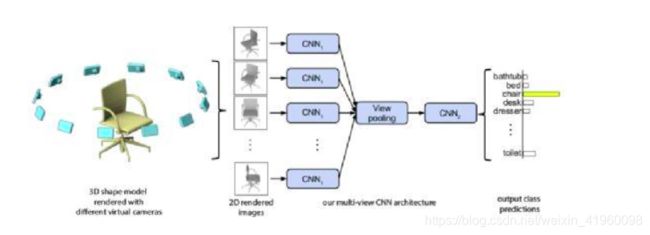
图 1.2 多视觉(来源论文Su H, Maji S, Kalogerakis E 2015)
1.2.3 点云
对于三维空间物体,我们需要得到其形状和位置信息,我们通常关注的是其外观特征,与其实体信息无关,所以只需要关注其点云信息即可。目前关于点云相关的工作也事比较多的。
主要问题:
- 点云的无序化和物体姿态变化的不变性。
1.2.4 图模型
图结构是更加进一步发展的思想,也是更加符合大脑思维处理问题的方式,我们看到一个物体很容易将其简化为具有特定拓扑关系的图结构,我们不会将其看多是复杂的点云或者体素等,需要太多存储空间,而图结构更加接近问题本质也是处理起来更加快的方法
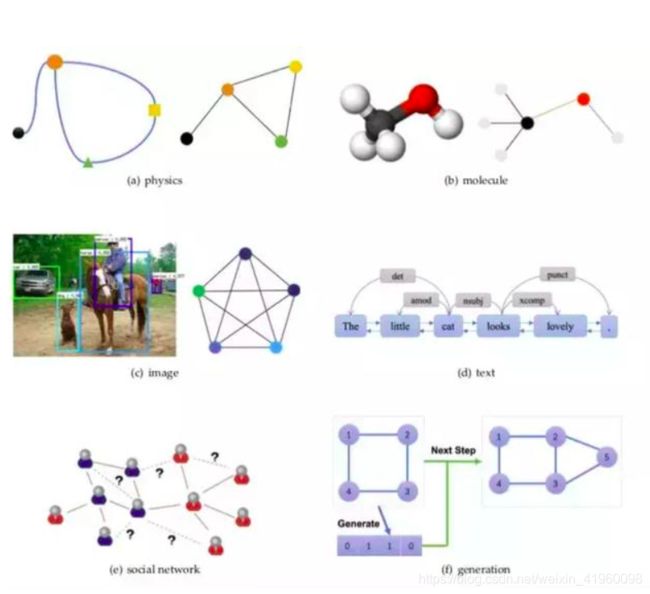
图1.3 GNN应用(来源论文 Jie Zhou et al )
1.3 图像分类和语义分割
图像分类与分割类似,分类对应的是图像整体,而分割对应是局部进行分类。
主要讲述一下
1.4 三维重建
1.4.1 问题陈述和分类
假设I={Ik,k=1,…,n}(n>1)为物体X的一张或者多张RGB图片。三维重建可以总结为一个学习预测算子f_o的过程,输入图像到该算子可得到一个和物体X相似的模型X’.因此重建的目标函数为L(I)=d(f_o,X),其中o为算子的参数,d(,)为重建结果和目标X的距离,L也称为深度学习中的损失函数,最新有篇三维重建综述link.
通常三维重建步骤如下:
- 三维点云获取(三维点云=三维空间中散点,没有结构,属性:颜色+法向量+空间坐标,能够反映场景大致结构,散乱点没有结构数据冗余,存储量要求大)
- 几何结构恢复(图形学方法,拓扑结构,点云->网格的表面重建,减少数据存储量,提升渲染逼真度)
- 场景绘制(渲染过程,知道相机参数,自动添纹理,网格贴上纹理,Autodesk,blinder)
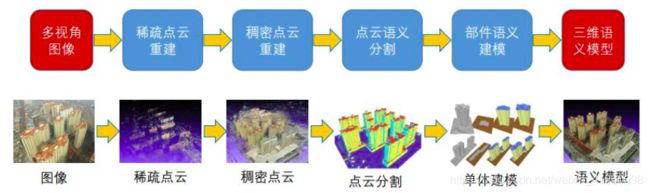

如上表所示为输入可以是单张图片,多张图片(已知/未知外参),或是视频流,即具有时间相关性的图像序列;输入也可以是描述一个或多个属于已知/未知类别的物体;还可以包括轮廓,语义标注等先验作为输入数据。输出的表示对网络结构的选择来说很重要,它影响着计算效率和重建质量,主要有三种表示方法。体积表示(Volumetric):在早期深度学习的三维重建算法中广泛采用,它可采用体素网格来参数化三维物体;这样二维卷积可以很容易扩展到三维,但是会极大消耗内存,也只有极少数方法达到亚像素精度。基于面的表示(Surface):如网格和点云,它们占用内存小,但不是规则结构,因此很难融入深度学习架构中。中间表示(Intermidiate):不直接从图像预测得到三维几何结构,而是将问题分解为连续步骤,每个步骤预测一个中间表示。实现预测算子的网络结构有很多,它的主干架构在训练和测试阶段也可能是不同的,一般由编码器h和解码器g组成,即。编码器将输入映射到称为特征向量或代码的隐变量x中,使用一系列的卷积和池化操作,然后是全连接层。解码器也称为生成器,通过使用全连接层或反卷积网络(卷积和上采样操作的序列,也称为上卷积)将特征向量解码为所需输出。前者适用于三维点云等非结构化输出,后者则用于重建体积网格或参数化表面。虽然网络的架构和它的组成模块很重要,但是算法性能很大程度上取决于它们的训练方式。本文将从三方面介绍。数据集:目前有多种数据集用于深度学习三维重建,一些是真实数据,一些是计算机图形生成的。损失函数:损失函数很大程度上影响着重建质量,同时反映了监督学习的程度。训练步骤和监督程度:有些方法需要用相应的三维模型标注真实的图像,获得这些图像的成本非常高;有些方法则依赖于真实数据和合成数据的组合;另一些则通过利用容易获得的监督信号的损失函数来避免完全的三维监督。
1.4.2 常用的算法介绍
三维几何视觉核心问题: 场景结构+相机位姿+(相机参数)
途径一: Structure from Motion (SfM) + Multiple View Stereo (MVS)
- 多视角图像
- 重建场景稀疏结构与相机位姿( off-line)
- SfM后可通过MVS获得稠密场景结构( off-line)
- SfM后可通过PnP计算相机实时位姿( on-line)
途径二: Simultaneous Localization and Mapping (SLAM) - 视频序列
- 重建场景稀疏/准稠密/稠密结构与相机位姿( on-line)
- 需要闭环检测+图优化( on-line)
基本算法介绍后期跟进
2 案例分析
场景:对于给定二维图像和三维实体模型,首先对于三维图像分类、然后根据图像进行语义分割,最终根据二维图像重建三维实体,以下分别探讨了几种模型学习结果的图像。
数据集为:
ModelNet40
KITTI
2.1 分类和分割网络
这里采用了几种常见的网络框架进行训练并进行对比
2.1.1 cycleGAN
基于cycleGan对抗网络进行分类,其中采用Wasserstein 距离算法
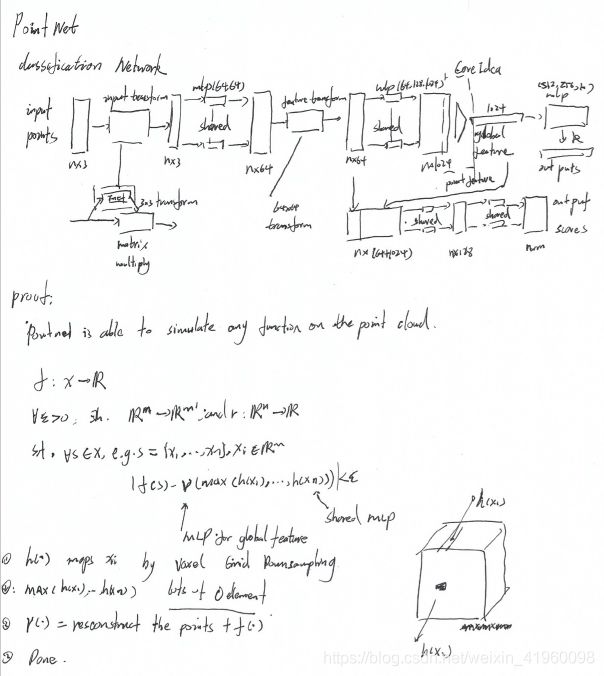
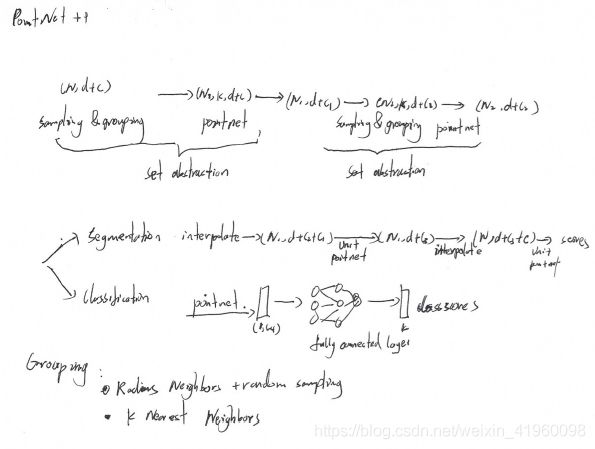
2.1.2 pointNet 和pointNet++分类和语义分割
下图为PointNet和pointNet++的网络结构,PointNet是较为广泛应用的,其作者在论文中给出了一个证明认为PointNet网络能够拟合任意点云函数,其证明过程可以详细看原文。PointNet++是对于PointNet的改进,其在处理点云网络的时候考虑了全局信息,避免落入局部信息中,其效果也较PointNet有一定的提升。
2.2 重建网络
参考文献
[1]: Xian-Feng Han, Hamid Laga, Mohammed Bennamoun Image-based 3D Object Reconstruction: State-of-the-Art and Trends in the Deep Learning Era
[2]: 神经网络原理