机器学习开篇
机器学习开篇
- 序论
- 1.1 机器学习是什么
- 1.2 机器学习的分类
-
- 1.2.1 从学习的过程分类
-
- 1. 监督学习(Supervised Learning):
- 2.无监督学习(Unsupervised Learning)
- 3.半监督学习(Semi-supervised Learning)
- 4.强化学习(Reinforcement Learning)
- 1.2.2 按完成的任务分类
-
- 1.聚类
- 2.分类
- 3.回归
- 4.标注
- 1.3 机器学习中的术语
-
- 1.3.1 数据集 训练集 验证集 测试集
- 1.3.2 实例、属性、特征、特征值、特征向量、
- 1.3.3 学习选择 TensorFlow2 还是 Pytorch
序论
准备以后有空间时间就把机器学习的知识系统的过一遍,主要参考书籍是清华大学出版社的《机器学习 python+sklearn+tensorflow2.0》。我写的内容基本都可以在书上找到,只是把书籍内容进一步的总结归纳以及添加一些其他内容、代码方面会以书籍提供的代码为主题,这样有书的同学可以再理解的基础上看书,而我会进一步对代码做出更多的注解和优化。
1.1 机器学习是什么
网上关于机器学习的定义以及如何衍生出来已经有了很多的解释:总的来说我的理解就是机器学习就是对一部分数据进行“学习”,然后对该数据的另外一个角度或者其他一些数据进行预测、判断、分类等任务
1.2 机器学习的分类
1.2.1 从学习的过程分类
从学习的过程来看,机器学习算法可以分为监督学习(Supervised Learning)、无监督学习(Unsupervised Learning)、和半监督学习(Semi-supervised Learning)
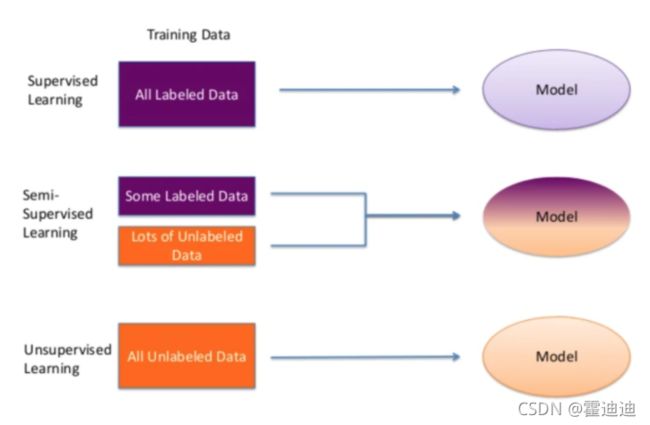
1. 监督学习(Supervised Learning):
监督学习的学习对象是有标签的训练数据,有标签数据是指已经给出明确标记的数据。监督学习利用有标签的训练数据来学习模型,目标是用该模型给未标记的测试数据打上标签。
监督学习最适合做一些分类的任务,比较经典的入门案例有莺尾花分类与波斯顿房价预测,这两个任务前者属于分类任务后者属于回归任务。
2.无监督学习(Unsupervised Learning)
与监督学习不同,无监督学习的训练数据完全没有标签,它自动从训练数据中学习知识,建立模型。无监督学习也称为无指导学习。在大多数工程应用中,事先标记大量的训练数据是一件代价较大的工作,因此,无监督学习在机器学习中具有重要作用。无监督学习需要找出数据之间的隐藏关系常用于推荐系统、异常检测。
3.半监督学习(Semi-supervised Learning)
半监督学习是监督学习和无监督学习相结合的种学习方法,它利用少量已标记样本来帮助对大量未标记样本进行标记。
4.强化学习(Reinforcement Learning)
与其他三种学习方式不一样,强化学习基于环境的反馈而行动﹐通过不断与环境的交互﹑试错、最终完成特定目的或者使得整体行动收益最大化。强化学习不需要训练数据的label,但是它需要每步行动环境给予的反馈,是奖励还是惩罚。这些反馈可以量化使得最终效益最大化。
这就是一个典型的强化学习场景:(包含的强化学习五要素:代理、目标、环境、行动、奖励)
- 机器有一个明确的小鸟角色——代理
- 需要控制小鸟飞的更远——目标
- 整个游戏过程中需要躲避各种水管——环境
- 躲避水管的方法是让小鸟用力飞一下——行动
- 飞的越远,就会获得越多的积分——奖励

当机器不断的试错之后,它将懂得控制小鸟的上下飞行来使奖励最大化。
1.2.2 按完成的任务分类
从完成的任务看,机器学习算法可以分为聚类、分类、回归和标注等模型。
1.聚类
聚类(Clustering)模型用于将训练数据按照某种关系划分为多个簇,将关系相近的训练数据分在同一个簇中。聚类属于无监督学习,它的训练数据没有标签,但经预测后的测试数据会被标记上标签,该标签是它所属簇的簇号。
2.分类
分类(Classification)是机器学习应用中最为广泛的任务,它用于将某个事物判定为属于预先设定的多个类别中的某一个。分类属于监督学习,数据的标签是预设的类别号。分类模型分为二分类和多分类。如果要预测明天是否下雨,则是一个二分类问题,如果要预测是阴、晴还是雨,则是一个三(多)分类问题。
3.回归
回归( Regression)模型预测的不是属于哪一类,而是什 么值,可以看作是将分类模型的类别数无限增加,即标签值不再只是几个离散的值了,而是连续的值。例如预测明天 的气温是多少度因为一整天的温度是一 组连续的值, 所以这是- -个回归模型要解决的问题。回归也属于监督学习。
4.标注
标注(Tagging)模型用于处理有前后关联关系的序列问题。在预测时,它的输人是-个观测序列,该观测序列的元素一.般具有前后的关联关系。它的输出是一个标签序列,也就是说,标注模型的输出是一个向量,该向量的每个元素是一个标签,标签的值是有限的离散值。标注模型常用于处理自然语言处理方面的问题,因为一个文本句子中的词出现的位置是有关联的。可以认为标注模型是分类模型的一个推广,它也属于监督学习范畴。
注意:算法的分类按学习的过程分类和按完成的任务分类并不冲突,某个算法我们可以说他是无监督学习的聚类算法
1.3 机器学习中的术语
1.3.1 数据集 训练集 验证集 测试集
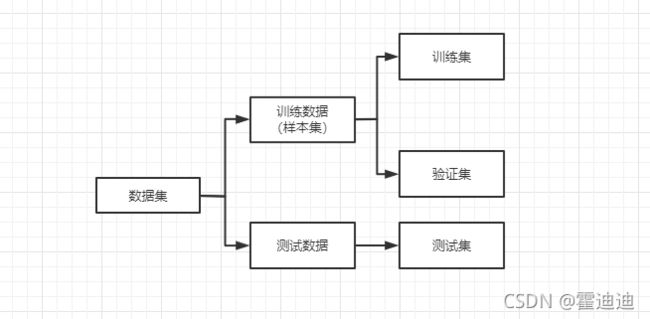
数据集(Data Set)是机器学习过程中的所有数据的集合。数据集分为训练数据和测试数据。测试数据集合即为测试集(Test Set),是需要应用模型进行预测的那部分数据,是机器学习所有工作的最终服务对象。为了防止训练出来的模型只对训练数据有效,一般将训练数据又分为训练集(Training Set)和验证集(Validation Set),训练集用来训练模型,而验证集一般只用来验证模型的有效性,不参与模型训练。它们的关系下如图所示。
在监督模型中,训练集和验证集都是事先标记好的有标签数据,测试集是无标签的数据。
在无监督模型中,训练集、验证集和测试集都是未标记的数据。
注意:数据集的如何划分也是很重要的一部分,起初最简单的做法是先打乱数据集再按某种比例划分,还有的方法需要根据自身需要做出选择例如
留出法(Hold-out)
交叉验证法(cross validation)
自助法(bootstrap)
1.3.2 实例、属性、特征、特征值、特征向量、
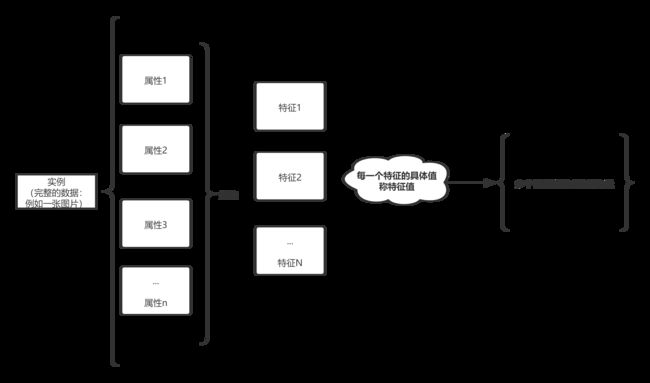
实例(Instance)是一个完整的训练或测试数据,例如一张图片、 一段文本、一条音频等。实例一般由多个属性(Attribute)表示。例如一张8X8 的图片,有64个属性,如果是黑白两色的,每个属性的取值为二维的,可设为0或1。再如段长为20个汉字的句子则有20个属性,当采用GB2312编码时,每个属性有6763个可能取值。因为实例有多个属性,因此用多维的向量来表示它,并用粗体的小写字母来标记,如xi下标i表示实例的序号(第几个样本)。
210
传统机器学习算法一般不直接对实例的属性进行处理,而是对从属性中提炼出来的特征进行处理,例如,从图片里提取出的水果长度与宽度之比的特征(Feature).从日期里提取出周几的特征等。在传统机器学习算法的应用里,提取特征是非常关键的环节,不 同的特征对预测效果有很大的影响。特征所取的具体值称为特征值(Feature Value)。具体应用到机器学习算法中时,实例通常不是由属性向量来表示。而由多个特征值组成 的特征向量(Feature Vector)来表示。用特征向量来表示实例时,也用xi(j)表示。用带括号的上标来区分实例的不同特征,如xi(j)表示第i个实例的第j维特征。因此,有m个特征的第i个实例可表示为xi=(xi(1), xi(2), xi(3), …,xi(m))。
1.3.3 学习选择 TensorFlow2 还是 Pytorch
TensorFlow2 、 Pytorch对比:
如果是⼯程师,应该优先选TensorFlow2.
如果是学⽣或者研究⼈员,应该优先选择Pytorch.
但是其实最好TensorFlow2和Pytorch都要学习掌握,现在大部分资源都比较多两个框架都是比较利于上手的。
理由如下:
1,TensorFlow官方也一直在强调TensorFlow的落地部署是非常快的,而且在⼯业界最重要的是模型落地,⽬前国内的⼤部分互联⽹企业只⽀持TensorFlow模型的在线部署,不⽀持Pytorch。 并且⼯业界更加注重的是模型的⾼可⽤性,许多时候使⽤的都是成熟的模型架构,调试需求并不⼤。
2,研究⼈员最重要的是快速迭代发表⽂章,需要尝试⼀些较新的模型架构。⽽Pytorch在易⽤性上相⽐TensorFlow2有⼀些优势,更加⽅便调试。 并且在2019年以来在学术界占领了⼤半壁江⼭,能够找到的相应最新研究成果更多。
3,TensorFlow2和Pytorch实际上整体⻛格已经⾮常相似了,学会了其中⼀个,学习另外⼀个将⽐
较容易。两种框架都掌握的话,能够参考的开源模型案例更多,并且可以⽅便地在两种框架之间切
换