基于OpenCV的垃圾分类项目的C++代码详解——学习笔记(二)
基于OpenCV C++垃圾分类项目的代码详解(工训总结)——对传入图像进行DNN网络分类
Begin
今天给大家介绍一个现成的人工神经网络——基于caffe框架的DNN(深度神经网络),这也是官方给出的例子。下面来分析一下此网络优缺点。功能、代码、细节问题、结果
一、优缺点
优点: 优点很明显,现成的,不用过多的改进网络的结构,也不需要知道网络底层是如何实现的,网络的各方面细节也不需要知道,直接拿来把接口改成自己需要的返回参数即可,适合于没学过人工神经网络和刚入门的小伙伴(也适合我)。
缺点: 缺点也很明显,因为是现成的,所以对具体问题的解决方案表现出不稳定性,往往和期望有所偏差,由于不知道网络具体的实现细节和原理,所以无法进行修改网络,只能围绕着网络的外围做一些修改和改动,以适应对具体问题的处理。(我就是围绕着网络的外围建立了新的标签文件,对原标签文件进行了容错性的处理。大神勿喷,我是小白,大佬请自动划走)。
二、功能
具体功能:对传入的图像进行分类,网络需要包含三个资源文件 :
bvlc_googlenet.caffemodel --------------训练文件
bvlc_googlenet.prototxt -------------------描述文件
synset_words.txt --------------------------- 标签文件 ,共一千个分类
三个文件的下载地址在这里,点一下就跳过去了
我们继续:对传入的图像先转化成二值图,之后进入网络进行分类处理(这里就不过多介绍了,主要就是提取特征之后进行一系列处理),我们通过 minMaxLoc();函数找到了此网络中一千个分类中相似度最大的那个结果的索引及相似度的值,通过和synset_words.txt标签文件中的一千个结果的对照,找出这张传入图片对照的具体标签,然后我们将这些信息显示在图片上,最后显示处理后的图片。
到此官方提供的例子的所有功能就结束了,但如果是具体问题的话(例如只是识别四类不同的垃圾),这个网络就会显得有些无能为力。原因是1000种分类太杂太多,对于同类垃圾会有不同的标签值,导致无法进行。
这里提供给大家一个我做比赛时的思路:由于网络提供的标签文件是1000种分类,假设我们只需要四种,那么此时我们只需要在原有标签文件的基础的外围再建立一个标签文件,将我们需要分为一类的标签写入这个外围的标签文件中并做好标记,当驱动外设时,从我们建立的外围标签文件中取出标签,根据我们所做的标记来对照分类。我称这种思路叫做------被欺骗的计算机.
这种思路下来比之前的1000种分类的效果好很多,但对于特征接近但不是一类的物品还是有些无能为力。
最好的方法肯定是精修一下 人工神经网络原理,对网络结构进行更改,这样出来的效果是最好的。或者,也可以找一个现成的网络分类的结果不是那么多的网络,再用上述的思路和计算机交流交流,效果也是挺不错的,但现成的网络分类结果的个数最好不要少于你需要的分类结果的个数(这个相信大家都懂)。
三、代码
重要到了大家期待的代码环节了。加上main()函数共有两个函数。
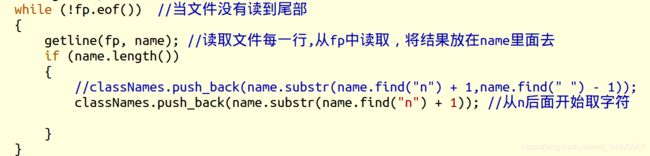
先来说说第一个函数vector< string> readClassLabels();读取标签文件中内容。这个函数实现的代码比较简单,这里就不过多解释了
vector<string> readClassLabels()
{
vector<string>classNames; //存放name
ifstream fp(labels_txt_file.c_str());//读入文件
if (!fp.is_open())
{
cout << "文件未找到!!!" << endl;
cout << "坏事了"<< endl;
exit(-1);
}
string name;
while (!fp.eof()) //当文件没有读到尾部
{
getline(fp, name); //读取文件每一行,从fp中读取,将结果放在name里面去
if (name.length())
{
classNames.push_back(name.substr(name.find("n") + 1,name.find(" ") - 1));
//classNames.push_back(name.substr(name.find(" ") + 1)); //从空格后面开始取字符
}
}
fp.close();//关闭输入输出流
return classNames;
}
这里substr()这个函数是剪切字符串的函数,后面的一堆是由于标签文件的格式原因,下面是标签文件的一部分截图:

主函数main();
int main()
{
Mat src = imread("1.3.jpg");
if (src.empty())
{
cout << "图片未找到!!!" << endl;
return -1;
}
imshow("input image", src);
vector<string> labels = readClassLabels();
Net caffe_net = readNetFromCaffe(caffe_txt_file, caffe_model_file);
if (caffe_net.empty())
{
return 0;
}
Mat inputblob = blobFromImage(src, 1.0, Size(224, 224), Scalar(104, 117, 123)); //将读进来的图像转为blob
Mat prob;
for(int i = 0; i < 10; i++)
{
caffe_net.setInput(inputblob, "data");//第一层是data
prob=caffe_net.forward("prob");
}
Mat Matprob = prob.reshape(1, 1); //维度变成1*1000
double Probability; //最大相似度
Point classindex;
minMaxLoc(Matprob, NULL, &Probability, NULL, &classindex);//此函数要求Matprob必须为单通道的一位数组
int Nameindex = classindex.x; //最大相似度对应的索引
cout<<"Probability:"<< Probability*100<<"%"<< endl;
cout << "value" << labels.at(Nameindex) << endl;
// cout << "NameValue:" << labels.at(Nameindex) << endl;
putText(src, labels.at(Nameindex), Point(20, 20), FONT_HERSHEY_SIMPLEX, 1.0, Scalar(0, 0, 255), 2, 8);
imshow("result image", src);
waitKey(0);
return 0;
}
这段代码也没有什么好解释的,一些重要的地方已经注释了,有小伙伴不懂得可以留言给我。
上面这些完成之后,我们还需要在主函数之外定义一下三个标签文件的名字:
string caffe_model_file = "bvlc_googlenet.caffemodel"; //训练文件
string caffe_txt_file = "bvlc_googlenet.prototxt"; //描述文件
string labels_txt_file = "synset_words.txt"; //标签文件
下面我们来看看.h文件
#ifndef __dnet__H
#define __dnet__H
#include 我们需要包含这些头文件,才能正常的用DNN网络。
四、细节问题
这里需要注意,安装的OpenCV的版本需要在3.4以上(在我印象里),我的是3.4.5,OpenCV3.4版本之后才兼容了dnn模块,这点很重要!!!
之后我们编译时需要在后面加上这个:
g++ dnet.cpp -o dnet `pkg-config --cflags --libs opencv`
到此,就完成了此网络的一次分类了,我们可以改变主函数的结构,进行循环多次分类,也可在外围建立新的标签文件,将需要处理的一类图像经过网络得到旧标签写入新标签并加入新的flag,之后相似的输入就被分成了同一类。这里我就不把我的具体比赛代码给大家了(很乱,哈哈哈)。
五、结果
我就将一张香蕉皮的照片分类结果放在这儿:
可以看出分类的结果的相似度为80.5459%,对应的标签文件为n07753592,这里的n被我剪切掉了,不过不重要,我们找到标签文件对照这个n07753592标签,得到了结果是
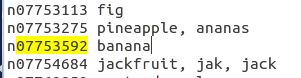
结果是正确的,对应的标签也没毛病。
我们更改源码,改变剪切字符串的那个函数:
得到的结果是:
和上面的那个的区别是把整个标签的内容放了出来。
六、终了
上述就是今天分享的所有内容了,如果对你有帮助,帮忙点个赞,我是小白,需要鼓励,嘻嘻嘻。
之后还会继续分享我的工训比赛的界面的规划,驱动等,如果有错误,请各位大佬批评指正,如果有和我一样的小白,哪里看不懂可以直接留言给我,我看到就会回复的,感谢。