深度学习数据增强工具 albumentations 的使用
简介 & 安装
- 官方文档 albumentations
albumentations 是一个给予 OpenCV的快速训练数据增强库,拥有非常简单且强大的可以用于多种任务(分割、检测)的接口,易于定制且添加其他框架非常方便。
它可以对数据集进行逐像素的转换,如模糊、下采样、高斯造点、高斯模糊、动态模糊、RGB转换、随机雾化等;也可以进行空间转换(同时也会对目标进行转换),如裁剪、翻转、随机裁剪等。
github及其示例地址如下:
- GitHub: https://github.com/albumentations-team/albumentations
- 示例:https://github.com/albumentations-team/albumentations_examples
可以通过 pip 的方式直接安装,也可以通过 pip + github 的方式,或者conda:
- pip 方式:
pip install albumentations - pip + github:
pip install -U git+https://github.com/albu/albumentations - conda方式,此方式需要先安装 imgaug,然后在安装 albumentations
conda install -c conda-forge imgaug
conda install albumentations -c albumentations最新的版本支持Python 3.5~3.7。
Keras 中也有 ImageDataGenerator 类用于数据增强,为什么还要用 alumentations 呢,真是因为 keras 中的方法并没有留有足够的空间进行定制,而在 alumentations 中我们可以按照自己的需要进行定制化的配置。
分类问题中的使用
在 albumentations 中可以用于分类问题中的操作包括:
HorizontalFlip, IAAPerspective, ShiftScaleRotate, CLAHE, RandomRotate90,
Transpose, ShiftScaleRotate, Blur, OpticalDistortion, GridDistortion, HueSaturationValue, IAAAdditiveGaussianNoise, GaussNoise, MotionBlur, MedianBlur, RandomBrightnessContrast, IAAPiecewiseAffine, IAASharpen, IAAEmboss, Flip, OneOf, Compose翻转(HorizontalFlip)
此类可以对图片进行翻转,HorizontalFlip 含有一个参数 p 表示多大概率翻转图片,如果 p=1 表示一定翻转,若p=0.5 表示有 0.5 的概率图片翻转。使用方法如下:
image = cv2.imread('./imgs/robot-running-super-tease.jpg')
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
image1 = HorizontalFlip(p=1)(image=image)['image']
plt.figure(figsize=(10, 10))
plt.imshow(image1)如下效果:

类的继承关系如下:
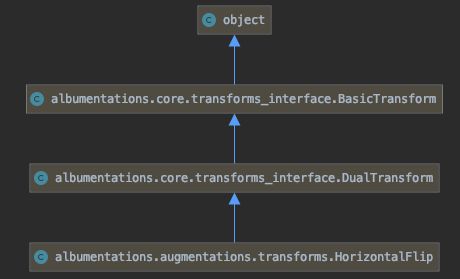
HorizontalFlip 类的初始化方法(HorizontalFlip(p=1))在 BasicTransform 中:
def __init__(self, always_apply=False, p=0.5):
self.p = p
self.always_apply = always_apply
self._additional_targets = {}
# replay mode params
self.deterministic = False
self.save_key = "replay"
self.params = {}
self.replay_mode = False
self.applied_in_replay = False而其中的 __call__ 则可以将类作为方法(HorizontalFlip(p=1)(image=image))被调用:
def __call__(self, force_apply=False, **kwargs):
if self.replay_mode:
if self.applied_in_replay:
return self.apply_with_params(self.params, **kwargs)
else:
return kwargs
if (random.random() < self.p) or self.always_apply or force_apply:
params = self.get_params()
if self.targets_as_params:
assert all(key in kwargs for key in self.targets_as_params), "{} requires {}".format(
self.__class__.__name__, self.targets_as_params
)
targets_as_params = {k: kwargs[k] for k in self.targets_as_params}
params_dependent_on_targets = self.get_params_dependent_on_targets(targets_as_params)
params.update(params_dependent_on_targets)
if self.deterministic:
if self.targets_as_params:
warn(
self.get_class_fullname() + " could work incorrectly in ReplayMode for other input data"
" because its' params depend on targets."
)
kwargs[self.save_key][id(self)] = deepcopy(params)
return self.apply_with_params(params, **kwargs)
return kwargs__call__ 最后会调用 HorizontalFlip 中的 apply() 方法,完成对图片的操作:
def apply(self, img, **params):
if img.ndim == 3 and img.shape[2] > 1 and img.dtype == np.uint8:
# Opencv is faster than numpy only in case of
# non-gray scale 8bits images
return F.hflip_cv2(img)
else:
return F.hflip(img)随机放射变换(ShiftScaleRotate)
该方法可以对图片进行平移(translate)、缩放(scale)和旋转(roatate),其含有以下参数:
shift_limit:图片宽高的平移因子,可以是一个值(float),也可以是一个元组((float, float))。如果是单个值,那么可选值得范围是 [0,1],之后该值会转换成(-shift_limit, shift_limit)。默认值为 (-0.0625, 0.0625)scale_limit:图片缩放因子,可以是一个值(float),也可以是一个元组((float, float))。如果是单个值,之后该值会转换成(-scale_limit, scale_limit)。默认值为 (-0.1, 0.1)rotate_limit:图片旋转范围,可以是一个值(int),也可以是一个元组((int, int))。如果是单个值,那么会被转换为 (-rotate_limit, rotate_limit)。默认值为(-45, 45)interpolation:OpenCV 标志,用于指定使用的差值算法,这些差值算法必须是cv2.INTER_NEAREST, cv2.INTER_LINEAR, cv2.INTER_CUBIC, cv2.INTER_AREA, cv2.INTER_LANCZOS4 中的一个。默认是 cv2.INTER_LINEARborder_mode:OpenCV 标志,用于指定使用的外插算法(extrapolation),算法必须是cv2.BORDER_CONSTANT, cv2.BORDER_REPLICATE, cv2.BORDER_REFLECT, cv2.BORDER_WRAP, cv2.BORDER_REFLECT_101中的一个,默认为 cv2.BORDER_REFLECT_101value:当border_mode的值为cv2.BORDER_CONSTANT时,进行填补的值,该值就可以时一个int或者float值,也可以是int或者 float数组mask_value:当border_mode的值为cv2.BORDER_CONSTANT时,应用到 mask 的填充值。p:使用此转换的概率,默认值为 0.5
使用方式如下:
image2 = ShiftScaleRotate(p=1)(image=image)["image"]
plt.figure(figsize=(10, 10))
plt.imshow(image2)得到如下效果:

组合变换(Compose)
变换不仅可以单独使用,还可以将这些组合起来,这就需要用到 Compose 类,该类继承自 BaseCompose。Compose 类含有以下参数:
transforms:转换类的数组,list类型bbox_params:用于 bounding boxes 转换的参数,BboxPoarams 类型keypoint_params:用于 keypoints 转换的参数, KeypointParams 类型additional_targets:key新target 名字,value 为旧 target 名字的 dict,如 {'image2': 'image'},dict 类型p:使用这些变换的概率,默认值为 1.0
如下使用:
image3 = Compose([
# 对比度受限直方图均衡
#(Contrast Limited Adaptive Histogram Equalization)
CLAHE(),
# 随机旋转 90°
RandomRotate90(),
# 转置
Transpose(),
# 随机仿射变换
ShiftScaleRotate(shift_limit=0.0625, scale_limit=0.50, rotate_limit=45, p=.75),
# 模糊
Blur(blur_limit=3),
# 光学畸变
OpticalDistortion(),
# 网格畸变
GridDistortion(),
# 随机改变图片的 HUE、饱和度和值
HueSaturationValue()
], p=1.0)(image=image)['image']
plt.figure(figsize=(10, 10))
plt.imshow(image3)运行多次会得到不同的结果:

组合与随机选择(Compose & OneOf)
使用上面的组合方式,执行的过程中会把每个在 transforms 中的转换都执行一遍,但有时候可能我们执行某一组类似操作中的一个,那么这时候就可以配合 OneOf 类来实现此功能。OneOf 类含有以下是参数:
transforms:转换类的列表p:使转换方法的概率,默认值为 0.5
如下使用:
image4 = Compose([
RandomRotate90(),
# 翻转
Flip(),
Transpose(),
OneOf([
# 高斯噪点
IAAAdditiveGaussianNoise(),
GaussNoise(),
], p=0.2),
OneOf([
# 模糊相关操作
MotionBlur(p=.2),
MedianBlur(blur_limit=3, p=0.1),
Blur(blur_limit=3, p=0.1),
], p=0.2),
ShiftScaleRotate(shift_limit=0.0625, scale_limit=0.2, rotate_limit=45, p=0.2),
OneOf([
# 畸变相关操作
OpticalDistortion(p=0.3),
GridDistortion(p=.1),
IAAPiecewiseAffine(p=0.3),
], p=0.2),
OneOf([
# 锐化、浮雕等操作
CLAHE(clip_limit=2),
IAASharpen(),
IAAEmboss(),
RandomBrightnessContrast(),
], p=0.3),
HueSaturationValue(p=0.3),
], p=1.0)(image=image)['image']
plt.figure(figsize=(10, 10))
plt.imshow(image4)每次运行得到不同的结果:

分割问题中的使用
在此示例中,需要使用到如下的类:
PadIfNeeded, HorizontalFlip, VerticalFlip, CenterCrop, Crop, Compose, Transpose, RandomRotate90, ElasticTransform, GridDistortion, OpticalDistortion, RandomSizedCrop, OneOf, CLAHE, RandomBrightnessContrast, RandomGamma此例子中使用 kaggle TGS Salt Identification Challenge 中的图片,包含了原图和mask,图片的大小为 ,如下:

填充(Padding)
在 Unet 这样的网络架构中,输入图片的尺寸需要尺寸需要能被 $2^N$ 整除,其中 $N$ 是池化层(maxpooling)的层数。在最简单的 Unet 结构中 $N$ 的值为 5,那么我们就需要将输入的图片填充到能被 $2^5=32$ 除尽的数字,应该上面图片的大小为 101,因此最接近的大小为 128。要进行此操作就需要用到 PadIfNeeded 类,其含有如下参数:
min_height:最终图片的最小高度,int 类型min_width:最终图片的最小宽度,int 类型border_mode:OpenCV 边界模式,默认值为cv2.BORDER_REFLECT_101value:如果border_mode值为cv2.BORDER_CONSTANT时的填充值,int、float或者 int、float数组类型mask_value:如果border_mode值为cv2.BORDER_CONSTANT时 mask 的填充值,int、float或者 int、float数组类型p:进行此转换的概率,默认值为 1.0
默认条件下 PadIfNeeded 会对图片和mask的四条边都进行填充,填充的类型包括零填充(zero)、常量填充(constant)和反射填充(reflection),默认为反射填充。使用方法如下:
image1 = PadIfNeeded(p=1, min_height=128, min_width=128)(image=image, mask=mask)
image11_padded = image1['image']
mask11_padded = image1['mask']
# (128, 128, 3) (128, 128)
print(image11_padded.shape, mask11_padded.shape)结果如下:
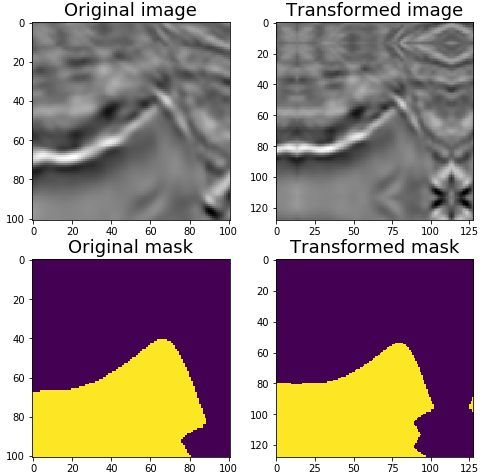
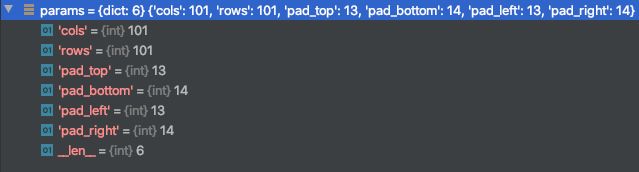
在运行的过程依据传入的不同参数 BasicTransform 的 __call__ 方法会调用 PadIfNeeded 中不同方法,image 参数会调用 applay 方法,mask 参数会调用 apply_to_mask 方法。
裁剪与中心裁剪(Crop & CenterCrop)
上面我们使用了 PadIfNeeded 对图片进行了填充,想要恢复原始的大小这时候就可以使用相关的裁剪方法:CenterCrop、Crop 等类。
先来看 CenterCrop 的使用,它主要从输入的图片中间进行裁剪,主要含有以下参数:
height:裁剪的高度,int 类型width:裁剪的宽度,int 类型p:使用此转换方法的概率,默认值为 1.0
原始的图片和mask大小为 101,因此此处设置需要裁剪的宽高(original_height/original_width)为 101,使用方法如下:
image2 = CenterCrop(p=1.0, height=original_height,
width=original_width)(image=image11_padded, mask=mask11_padded)
image22_center_cropped = image2['image']
mask22_center_cropped = image2['mask']
# (101, 101, 3) (101, 101)
print(image22_center_cropped.shape, mask22_center_cropped.shape)运行的到如下效果,可以看到将填充后的图片恢复成了原样。
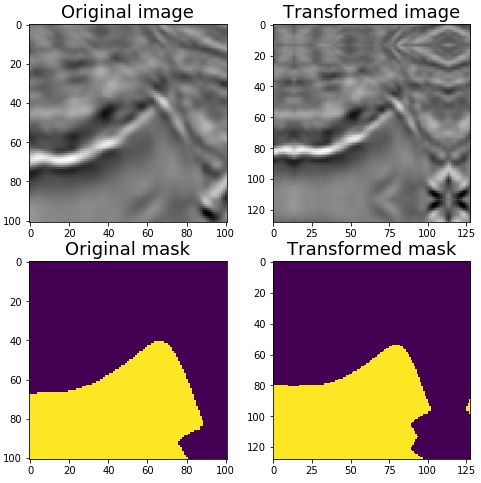
除了使用 CenterCrop 之外,还可以使用 Crop 来手动恢复原始大小,Crop 类的主要参数如下:
x_min:x轴左上的最小值,int 类型y_min:y轴左上的最小值,int 类型x_max:x轴右下的最大值,int 类型y_max:y轴右下的最大值,int 类型
使用方式如下:
# 计算需要裁剪的最大值最小值
x_min = (128 - original_width) // 2
y_min = (128 - original_height) // 2
x_max = x_min + original_width
y_max = y_min + original_height
image3 = Crop(p=1, x_min=x_min, x_max=x_max,
y_min=y_min, y_max=y_max)(image=image11_padded, mask=mask11_padded)
image_cropped = image3['image']
mask_cropped = image3['mask']
print(image_cropped.shape, mask_cropped.shape)非破坏性转换
从上面的转换操作中可以看到操作破坏了图像的空间信息,对于想卫星、航空或者医学图片我们并不希望破坏它原有的空间结构,如以下的八种操作就不会破坏原有图片的空间结构。
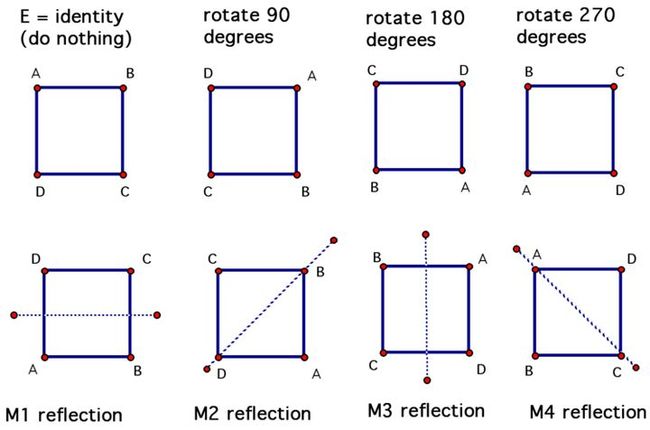
通过 HorizontalFlip, VerticalFlip, Transpose, RandomRotate90 四种操作的组合就可以得到上面的八种操作。这些操作可以参考上面《分类问题中的使用》章节。
非刚体转换
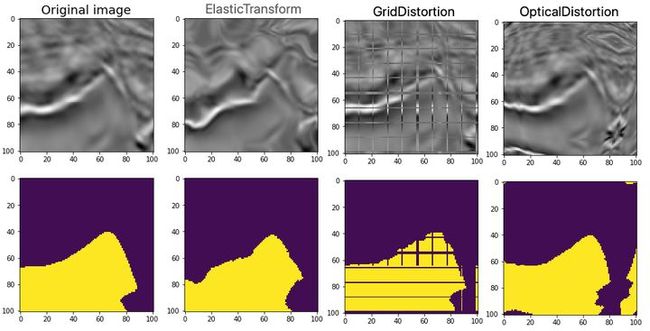
在医学影像问题中非刚体装换可以帮助增强数据。albumentations 中主要提供了以下几种非刚体变换类:ElasticTransform、GridDistortion 和 OpticalDistortion。三个类的主要参数如下:
ElasticTransform 类参数:
alpha、sigma:高斯过滤参数,float类型alpha_affine:范围为 (-alpha_affine, alpha_affine),float 类型interpolation、border_mode、value、mask_value:与其他类含义一样approximate:是否应平滑具有固定大小核的替换映射(displacement map),若启用此选项,在大图上会有两倍的速度提升,boolean类型。p:使用此转换的概率,默认值为 0.5
GridDistortion 类参数:
num_steps:在每一条边上网格单元的数量,默认值为 5,int 类型distort_limit:如果是单值,那么会被转成 (-distort_limit, distort_limit),默认值为 (-0.03, 0.03),float或float数组类型interpolation、border_mode、value、mask_value:与其他类含义一样p:使用此转换的概率,默认值为 0.5
OpticalDistortion 类参数:
distort_limit:如果是单值,那么会被转成 (-distort_limit, distort_limit),默认值为 (-0.05, 0.05),float或float数组类型shift_limit:如果是单值,那么会被转成 (-shift_limit, shift_limit),默认值为 (-0.05, 0.05),float或float数组类型interpolation、border_mode、value、mask_value:与其他类含义一样p:使用此转换的概率,默认值为 0.5
使用方式如下:
# 弹性装换
image41 = ElasticTransform(p=1, alpha=120, sigma=120 * 0.05,
alpha_affine=120 * 0.03)(image=image, mask=mask)
image_elastic = image41['image']
mask_elastic = image41['mask']
# 网格畸变
image42 = GridDistortion(p=1, num_steps=10)(image=image, mask=mask)
image_grid = image42['image']
mask_grid = image42['mask']
# 光学畸变
image43 = OpticalDistortion(p=1, distort_limit=2, shift_limit=0.5)(image=image, mask=mask)
image_optical = image43['image']
mask_optical = image43['mask']效果如下:
组合多种转换
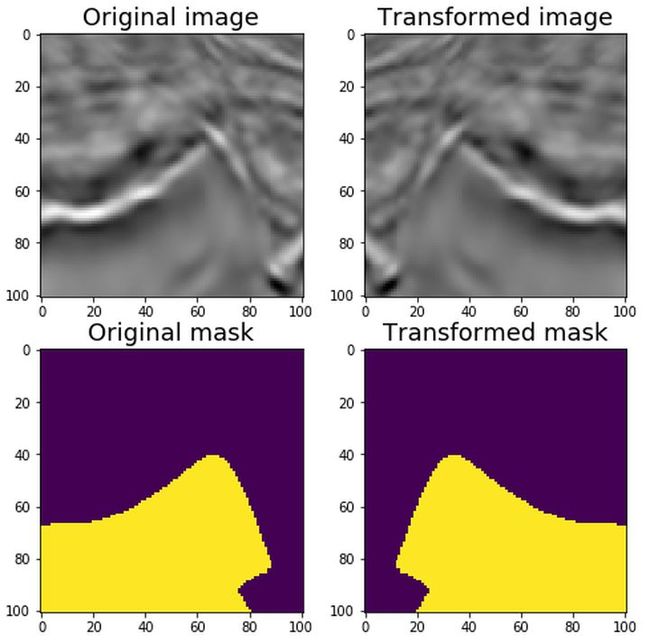
我们可以将上面的填充、裁剪、非刚体转换、非破坏性转换组合起来:
image5 = Compose([
# 非刚体转换
OneOf([RandomSizedCrop(min_max_height=(50, 101),
height=original_height, width=original_width, p=0.5),
PadIfNeeded(min_height=original_height,
min_width=original_width, p=0.5)], p=1),
# 非破坏性转换
VerticalFlip(p=0.5),
RandomRotate90(p=0.5),
# 非刚体转换
OneOf([
ElasticTransform(p=0.5, alpha=120, sigma=120 * 0.05, alpha_affine=120 * 0.03),
GridDistortion(p=0.5),
OpticalDistortion(p=1, distort_limit=2, shift_limit=0.5)
], p=0.8),
# 非空间性转换
CLAHE(p=0.8),
RandomBrightnessContrast(p=0.8),
RandomGamma(p=0.8)])(image=image, mask=mask)
image_heavy = image5['image']
mask_heavy = image5['mask']运行的效果如下:
序列化
基础序列化
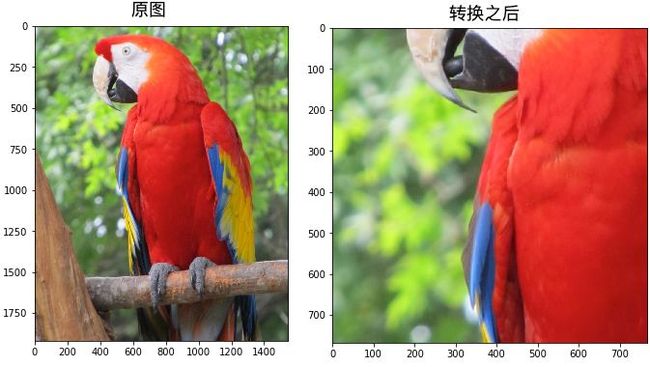
albumentations 提供了 save() 和 load() 两个方法,可以将一个装换流水线存储到文件,这样就可以将一组转换应用到不同的地方。我们首先定义如下的一个转换流水线:
# 定义一个转换流程
transform = A.Compose([
A.RandomCrop(768, 768),
A.OneOf([
A.RGBShift(),
A.HueSaturationValue()
]),
])
print(transform)上面输出上面流水线的详细设置参数,如下:
Compose([
RandomCrop(always_apply=False, p=1.0, height=768, width=768),
OneOf([
RGBShift(always_apply=False, p=0.5, r_shift_limit=(-20, 20), g_shift_limit=(-20, 20), b_shift_limit=(-20, 20)),
HueSaturationValue(always_apply=False, p=0.5, hue_shift_limit=(-20, 20), sat_shift_limit=(-30, 30), val_shift_limit=(-20, 20)),
], p=0.5),
], p=1.0, bbox_params=None, keypoint_params=None, additional_targets={})之后使用上面的转换流水线对图片进行操作,为了以后方便复现这里加上随机数种子:
image = cv2.imread('./imgs/parrot.jpg')
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# 定义随机数种子方便以后复现
random.seed(42)
augmented_image_1 = transform(image=image)['image']运行之后就可以看到如下的效果:
之后就可以将此转换流水线转成 json 格式保存起来,当使用的时候再重新加载。保存主要使用到 save 方法,参数如下:
transform:进行序列化的转换,object类型filepath:保存地址,str类型data_format:序列化的格式,必须是 json 和 yaml 的一种,默认为 json。
加载主要使用 load 方法,参数如下:
file_path:读取文件的路径,str类型data_format:序列化的格式,必须是 json 和 yaml 的一种,默认为 jsonlambda_transforms:包含 lambda (Lambda 类)转换的字典。当被恢复的流水线含有 lambda 转换的时候此字典(dict)是必须的。字典中的键(key)必须与被加载的文件中的 lambda 转换参数名字一样。
使用方法如下:
# 保存与加载
#保存
A.save(transform, '/tmp/transform.json')
#加载
loaded_transform = A.load('/tmp/transform.json')
print(loaded_transform)可以看到重新加载的转换与之前的转换一致:
Compose([
RandomCrop(always_apply=False, p=1.0, height=768, width=768),
OneOf([
RGBShift(always_apply=False, p=0.5, r_shift_limit=(-20, 20), g_shift_limit=(-20, 20), b_shift_limit=(-20, 20)),
HueSaturationValue(always_apply=False, p=0.5, hue_shift_limit=(-20, 20), sat_shift_limit=(-30, 30), val_shift_limit=(-20, 20)),
], p=0.5),
], p=1.0, bbox_params=None, keypoint_params=None, additional_targets={})下一步,我们就需要使用加载的转换对原图进行抓环境,为了复现相同的结果这是设置与之前相同的随机数种子:
random.seed(42)
augmented_image_2 = loaded_transform(image=image)['image']通过下图可以看到,重新加载的转换与之前一致:
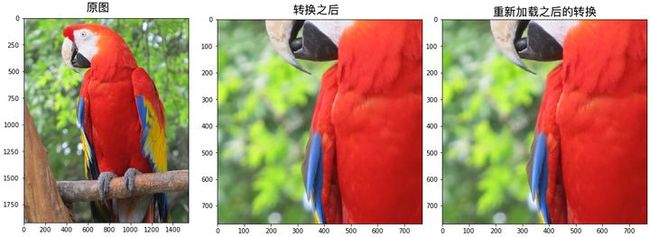
上面的转换使用的是 json 格式,也可以使用 yaml格式:
A.save(transform, '/tmp/transform.yml', data_format='yaml')
loaded_transform = A.load('/tmp/transform.yml', data_format='yaml')序列化为Python dict
使用 to_dict 和 from_dict 来序列化转换流水线为Python dict 格式。如果我们需要在序列化流水线上有更多的控制,如需要将序列的版本保存到数据库或者将其他送到另一个服务器上,那么这两给函数就非常的有用了。
to_dict 会返回一个描述流水线的python 字典,此字典只包含最原始的数据类型,如dict、list、str、int、float等。为了从字典中恢复抓换流水线只需要调用 from_dict。如下使用方式:
transform_dict = A.to_dict(transform)
loaded_transform = A.from_dict(transform_dict)
print(loaded_transform)得到如下结果:
Compose([
RandomCrop(always_apply=False, p=1.0, height=768, width=768),
OneOf([
RGBShift(always_apply=False, p=0.5, r_shift_limit=(-20, 20), g_shift_limit=(-20, 20), b_shift_limit=(-20, 20)),
HueSaturationValue(always_apply=False, p=0.5, hue_shift_limit=(-20, 20), sat_shift_limit=(-30, 30), val_shift_limit=(-20, 20)),
], p=0.5),
], p=1.0, bbox_params=None, keypoint_params=None, additional_targets={})系列化与反序列化为 lambda 抓换
Lambda 转换使用用户自定义的转换函数,对于 Lambda 转换只有管线的名字和位置会被保存。在使用 lambda_transforms 参数反序列化时,需要手动的提供所有 Lambda 转换实例。如下首先定义一个自定义的抓换:
# 定义一个用于图片转换的函数
def hflip_image(image, **kwargs):
return cv2.flip(image, 1)之后定义一个 Lambda 表达式,为了之后的序列化需要为 Lambda 表达式指定
# 定义 Lambda 表达式,为了进行序列化需要指定名字
hflip_transform = A.Lambda(name='hflip_image', image=hflip_image, p=0.5)
print(hflip_transform)输出如下:
Lambda(name='hflip_image', image=, mask=, keypoint=, bbox=, always_apply=False, p=0.5) 将其应用到图片:
random.seed(1)
flipped_image_1 = hflip_transform(image=image)['image']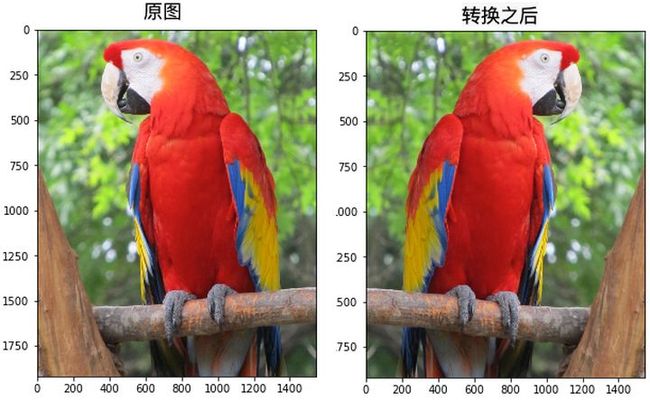
之后将其保存到 dict 中
transform_dict = A.to_dict(hflip_transform)
print(transform_dict)如下输出:
{'__version__': '0.4.4', 'transform': {'__type__': 'Lambda', '__name__': 'hflip_image'}}在进行反序列化Lambda抓换时,需要将 Lambda 转换的所有实例传入到 from_dict 中的 lambda_transforms 参数中,即我们需要将 hflip_transform = A.Lambda(name='hflip_image', image=hflip_image, p=0.5) 传入到 lambda_transforms 参数中:
如下输出:
Lambda(name='hflip_image', image=, mask=, keypoint=, bbox=, always_apply=False, p=0.5) 加载完成就可以进行接下来的抓换:
random.seed(1)
flipped_image_2 = loaded_transform(image=image)['image']
assert np.array_equal(flipped_image_1, flipped_image_2)断言没有保存,说明加载之后的转换与之前的一致。
除了使用上面的 to_dict和 from_dict 方法,我们还可以使用 save 和 load 方法组合,该方法一样需要提供 lambda_transforms 参数的值:
# 先保存
A.save(hflip_transform, '/tmp/hflip_transform.json')
# 后加载
loaded_transform = A.load('/tmp/hflip_transform.json', lambda_transforms={'hflip_image': hflip_transform})
print(loaded_transform)可以看到得到样的输出:
ambda(name='hflip_image', image=, mask=, keypoint=, bbox=, always_apply=False, p=0.5)