(CrossFormer) CROSSFORMER: A VERSATILE VISION TRANSFORMER HINGING ON CROSS-SCALE ATTENTION
文章目录
- CROSSFORMER: A VERSATILE VISION TRANSFORMER HINGING ON CROSS-SCALE ATTENTION
- 一、CROSS-SCALE EMBEDDING LAYER (CEL)
-
- 1.代码
- 二、LONG SHORT DISTANCE ATTENTION (LSDA)
-
- 1.代码
- 三、DYNAMIC POSITION BIAS (DPB)
-
- 1.代码
CROSSFORMER: A VERSATILE VISION TRANSFORMER HINGING ON CROSS-SCALE ATTENTION
- 提出一种新的patch_embedding的方法CEL,将由4个不同卷积生成的tokens按通道维度连接起来得到最终的tokens。
- 提出一种新的window-attention的计算方法LDA,window中的每点分散在特征图中。
- 提出一种新的相对位置编码的计算方法DPB,其相对位置偏执表与SWin不同。
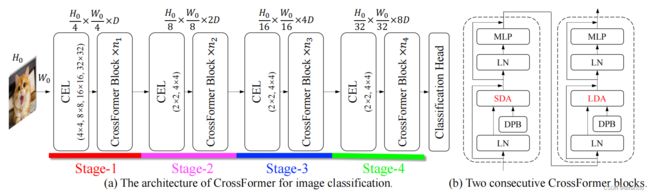
一、CROSS-SCALE EMBEDDING LAYER (CEL)
通过4个Kernel和输出dim不同,Stride相同的卷积得到4份数量相同,dim不同的token,将4份token按照dim维度cat起来得到最终的token,Kernel不等于Stride导致patch和patch之间有交叉
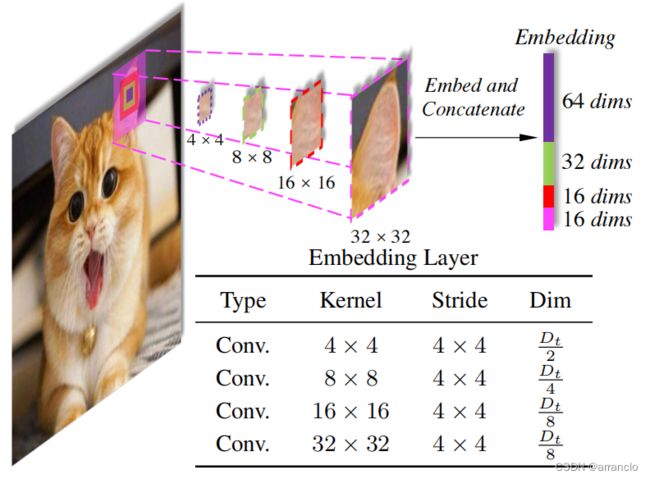
1.代码
PatchEmbed:通过4个Kernel和输出dim不同,Stride相同的卷积得到4份数量相同,dim不同的token,将4份token按照dim维度cat起来得到最终的token,Kernel不等于Stride导致patch和patch之间有交叉
class PatchEmbed(nn.Module):
r""" Image to Patch Embedding
Args:
img_size (int): Image size. Default: 224.
patch_size (int): Patch token size. Default: 4.
in_chans (int): Number of input image channels. Default: 3.
embed_dim (int): Number of linear projection output channels. Default: 96.
norm_layer (nn.Module, optional): Normalization layer. Default: None
"""
def __init__(self, img_size=224, patch_size=[4], in_chans=3, embed_dim=96, norm_layer=None):
super().__init__()
img_size = to_2tuple(img_size)
# patch_size = to_2tuple(patch_size)
patches_resolution = [img_size[0] // 4, img_size[1] // 4] # only for flops calculation
self.img_size = img_size
self.patch_size = patch_size
self.patches_resolution = patches_resolution
self.in_chans = in_chans
self.embed_dim = embed_dim
self.projs = nn.ModuleList()
for i, ps in enumerate(patch_size):
if i == len(patch_size) - 1:
dim = embed_dim // 2 ** i
else:
dim = embed_dim // 2 ** (i + 1)
stride = 4
padding = (ps - 4) // 2
self.projs.append(nn.Conv2d(in_chans, dim, kernel_size=ps, stride=stride, padding=padding))
if norm_layer is not None:
self.norm = norm_layer(embed_dim)
else:
self.norm = None
def forward(self, x):
B, C, H, W = x.shape
xs = []
for i in range(len(self.projs)):
tx = self.projs[i](x).flatten(2).transpose(1, 2) # embedding 卷积加展平
xs.append(tx) # B Ph*Pw C
x = torch.cat(xs, dim=2) # 将4份enbedding按通道维度cat起来
if self.norm is not None:
x = self.norm(x)
return x, H, W
def flops(self):
Ho, Wo = self.patches_resolution
flops = 0
for i, ps in enumerate(self.patch_size):
if i == len(self.patch_size) - 1:
dim = self.embed_dim // 2 ** i
else:
dim = self.embed_dim // 2 ** (i + 1)
flops += Ho * Wo * dim * self.in_chans * (self.patch_size[i] * self.patch_size[i])
if self.norm is not None:
flops += Ho * Wo * self.embed_dim
return flops
二、LONG SHORT DISTANCE ATTENTION (LSDA)
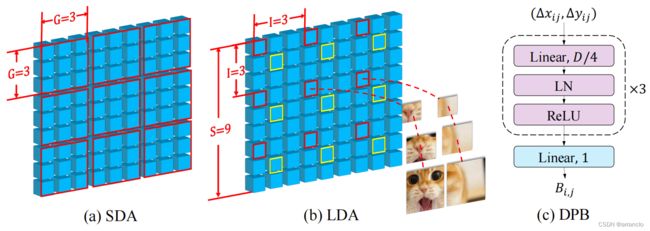
SDA即普通的window-attention,LDA提出一种新的生成window的方式,每个window由均匀散布在全局的patch组成
1.代码
CrossFormerBlock:
SDA:普通的window-attention,通过reshape和permute方法得到普通window
LDA:长距离的window-attention,通过reshape和permute方法得到长距离的window
class CrossFormerBlock(nn.Module):
r""" CrossFormer Block.
Args:
dim (int): Number of input channels.
input_resolution (tuple[int]): Input resulotion.
num_heads (int): Number of attention heads.
group_size (int): Window size.
lsda_flag (int): use SDA or LDA, 0 for SDA and 1 for LDA.
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set.
drop (float, optional): Dropout rate. Default: 0.0
attn_drop (float, optional): Attention dropout rate. Default: 0.0
drop_path (float, optional): Stochastic depth rate. Default: 0.0
act_layer (nn.Module, optional): Activation layer. Default: nn.GELU
norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
"""
def __init__(self, dim, input_resolution, num_heads, group_size=7, interval=8, lsda_flag=0,
mlp_ratio=4., qkv_bias=True, qk_scale=None, drop=0., attn_drop=0., drop_path=0.,
act_layer=nn.GELU, norm_layer=nn.LayerNorm, num_patch_size=1):
super().__init__()
self.dim = dim
self.input_resolution = input_resolution
self.num_heads = num_heads
self.group_size = group_size
self.interval = interval
self.lsda_flag = lsda_flag
self.mlp_ratio = mlp_ratio
self.num_patch_size = num_patch_size
self.norm1 = norm_layer(dim)
self.attn = Attention(
dim, num_heads=num_heads,
qkv_bias=qkv_bias, qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop,
position_bias=True)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
def forward(self, x, H, W):
B, L, C = x.shape
assert L == H * W, "input feature has wrong size %d, %d, %d" % (L, H, W)
if min(H, W) <= self.group_size:
# if window size is larger than input resolution, we don't partition windows
self.lsda_flag = 0
self.group_size = min(H, W)
shortcut = x
x = self.norm1(x)
x = x.view(B, H, W, C)
# padding
size_div = self.interval if self.lsda_flag == 1 else self.group_size
pad_l = pad_t = 0
pad_r = (size_div - W % size_div) % size_div
pad_b = (size_div - H % size_div) % size_div
x = F.pad(x, (0, 0, pad_l, pad_r, pad_t, pad_b))
_, Hp, Wp, _ = x.shape
mask = torch.zeros((1, Hp, Wp, 1), device=x.device)
if pad_b > 0:
mask[:, -pad_b:, :, :] = -1
if pad_r > 0:
mask[:, :, -pad_r:, :] = -1
# group embeddings and generate attn_mask
if self.lsda_flag == 0: # SDA 普通window-atten
G = Gh = Gw = self.group_size
x = x.reshape(B, Hp // G, G, Wp // G, G, C).permute(0, 1, 3, 2, 4, 5).contiguous() # (B, Hp // G, G, Wp // G, G, C) 把H/W切分成Hp // G个段,段长为G -> (B, Hp // G, Wp // G, G, C)
x = x.reshape(B * Hp * Wp // G**2, G**2, C) # G是window大小
nG = Hp * Wp // G**2 # window数量
# attn_mask
if pad_r > 0 or pad_b > 0:
mask = mask.reshape(1, Hp // G, G, Wp // G, G, 1).permute(0, 1, 3, 2, 4, 5).contiguous()
mask = mask.reshape(nG, 1, G * G)
attn_mask = torch.zeros((nG, G * G, G * G), device=x.device)
attn_mask = attn_mask.masked_fill(mask < 0, NEG_INF)
else:
attn_mask = None
else: # LDA 新window-atten,运用了一种新的产生window的方法
I, Gh, Gw = self.interval, Hp // self.interval, Wp // self.interval
x = x.reshape(B, Gh, I, Gw, I, C).permute(0, 2, 4, 1, 3, 5).contiguous() # (B, Gh, I, Gw, I, C) 把H/W切分成Gh/Gw个段,段长为I -> (B, I, I, Gh, Gw, C)
x = x.reshape(B * I * I, Gh * Gw, C) # Gh/Gw是window大小
nG = I ** 2
# attn_mask
if pad_r > 0 or pad_b > 0:
mask = mask.reshape(1, Gh, I, Gw, I, 1).permute(0, 2, 4, 1, 3, 5).contiguous()
mask = mask.reshape(nG, 1, Gh * Gw)
attn_mask = torch.zeros((nG, Gh * Gw, Gh * Gw), device=x.device)
attn_mask = attn_mask.masked_fill(mask < 0, NEG_INF)
else:
attn_mask = None
# multi-head self-attention
x = self.attn(x, Gh, Gw, mask=attn_mask) # nG*B, G*G, C
# ungroup embeddings
if self.lsda_flag == 0:
x = x.reshape(B, Hp // G, Wp // G, G, G, C).permute(0, 1, 3, 2, 4, 5).contiguous() # B, Hp//G, G, Wp//G, G, C
else:
x = x.reshape(B, I, I, Gh, Gw, C).permute(0, 3, 1, 4, 2, 5).contiguous() # B, Gh, I, Gw, I, C
x = x.reshape(B, Hp, Wp, C)
# remove padding
if pad_r > 0 or pad_b > 0:
x = x[:, :H, :W, :].contiguous()
x = x.view(B, H * W, C)
# FFN
x = shortcut + self.drop_path(x)
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x
def extra_repr(self) -> str:
return f"dim={self.dim}, input_resolution={self.input_resolution}, num_heads={self.num_heads}, " \
f"group_size={self.group_size}, lsda_flag={self.lsda_flag}, mlp_ratio={self.mlp_ratio}"
def flops(self):
三、DYNAMIC POSITION BIAS (DPB)
类似于swin的相对位置编码
swin中的relative_position_bias_table是通过torch.zeros初始化的可学习参数,DPB中的relative_position_bias_table是由初始shape为((2Gh-1)·(2Gw-1), 2)的biases通过4层nn.Linear得到的,最终shape为((2Gh-1)·(2Gw-1), heads)
其余的操作和swin一致
1.代码
class DynamicPosBias(nn.Module):
def __init__(self, dim, num_heads, residual):
super().__init__()
self.residual = residual
self.num_heads = num_heads
self.pos_dim = dim // 4
self.pos_proj = nn.Linear(2, self.pos_dim)
self.pos1 = nn.Sequential(
nn.LayerNorm(self.pos_dim),
nn.ReLU(inplace=True),
nn.Linear(self.pos_dim, self.pos_dim),
)
self.pos2 = nn.Sequential(
nn.LayerNorm(self.pos_dim),
nn.ReLU(inplace=True),
nn.Linear(self.pos_dim, self.pos_dim)
)
self.pos3 = nn.Sequential(
nn.LayerNorm(self.pos_dim),
nn.ReLU(inplace=True),
nn.Linear(self.pos_dim, self.num_heads) # 2Gh-1 * 2Gw-1, heads
)
def forward(self, biases):
if self.residual:
pos = self.pos_proj(biases)
pos = pos + self.pos1(pos)
pos = pos + self.pos2(pos)
pos = self.pos3(pos) # 2Gh-1 * 2Gw-1, heads
else:
pos = self.pos3(self.pos2(self.pos1(self.pos_proj(biases)))) # 2Gh-1 * 2Gw-1, heads
return pos
def flops(self, N):
flops = N * 2 * self.pos_dim
flops += N * self.pos_dim * self.pos_dim
flops += N * self.pos_dim * self.pos_dim
flops += N * self.pos_dim * self.num_heads
return flops