机器学习笔记六-----------------使用Prophet(时间序列模型)预测空气质量的数据的例程的笔记
一,源码及数据的下载链接
https://github.com/marcopeix/air-quality
二,源码解读
2.1,读入原始数据
原始数据大小【9471,17】
DATAPATH = '/home/kongxianglan/code/air-quality-master/data/AirQualityUCI.csv'
data = pd.read_csv(DATAPATH, sep=';')
data.head()
print(data)
# (9471, 17)
data.shape存在的问题,数据的.是,号

2.2,数据清洗及关键数据的提取
1,删除全为空值的行或列,删除后数据变为【9357,15】
data.dropna(axis=1, how='all', inplace=True)
data.dropna(axis=0, how='all', inplace=True)
# (9357, 15)
data.shape
data.head()2,将数据格式转换为Prophet预测模型需要的数据格式
主要是将数据转换为浮点数据,将数据的,号变为.号
# 数据加载,并将数据转换为浮点型同时将,替换成.
data['Date'] = pd.to_datetime(data['Date'])
for col in data.iloc[:, 2:].columns:
if data[col].dtypes == object:
data[col] = data[col].str.replace(',', '.').astype('float')3,将粒度为小时的数据转换为粒度为天的数据
算法将一天内每个小时的气体的浓度求均值,作为一天的
def positive_average(num):
return num[num > -200].mean()
daily_data = data.drop('Time', axis=1).groupby('Date').apply(positive_average)
4,检查每一列的NAN值是否是大于8个的
daily_data.isna().sum() > 8
5,删除nan大于8个的气体浓度的列
daily_data = daily_data.iloc[:,(daily_data.isna().sum() <= 8).values]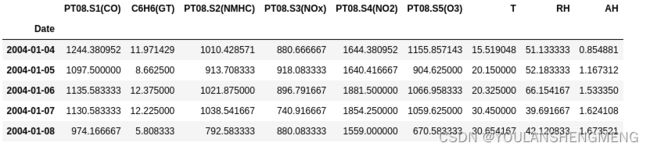
经过该数据操作后,数据的个数变为: 【391, 9】
6, 再次删除全为空值的行或列,删除后数据变为【383,9】
daily_data = daily_data.dropna()
daily_data.shape7,将数据变为粒度为周的数据
weekly_data = daily_data.resample('W').mean()
6, 再次删除全为空值的行或列,删除后数据变为【73,9】
daily_data = daily_data.dropna()
daily_data.shape7,显示剩余的9中气体的浓度含量的曲线图
def plot_data(col):
plt.figure(figsize=(17, 8))
plt.plot(weekly_data[col])
plt.xlabel('Time')
plt.ylabel(col)
plt.grid(False)
plt.show()
for col in weekly_data.columns:
plot_data(col)
8,提取空气质量预测的关键性数据
#让我们专注于预测氮氧化物的浓度。氮的氧化物会发生反应形成烟雾和酸雨,
# 而且是细颗粒物和地面臭氧形成的核心,这两种物质都与有害健康有关。
#只保留关键的氮氧化物的浓度
cols_to_drop = ['PT08.S1(CO)', 'C6H6(GT)', 'PT08.S2(NMHC)', 'PT08.S4(NO2)', 'PT08.S5(O3)', 'T', 'RH', 'AH']
weekly_data = weekly_data.drop(cols_to_drop, axis=1)
weekly_data.head()
2.3 预测及验证
1, 将数据格式转换为模型需要的格式
df = weekly_data.reset_index()
df.columns = ['ds', 'y']
df.head()
2,定义要训练的数据的截止位置
prediction_size = 30
train_df = df[:-prediction_size]3,定义模型且进行拟合
m = Prophet()
m.fit(train_df)4,指定预测的时间段
future = m.make_future_dataframe(periods=prediction_size)
forecast = m.predict(future)
forecast.head()
5,结果显示
m.plot(forecast)
6,其他分量预测的显示
m.plot_components(forecast)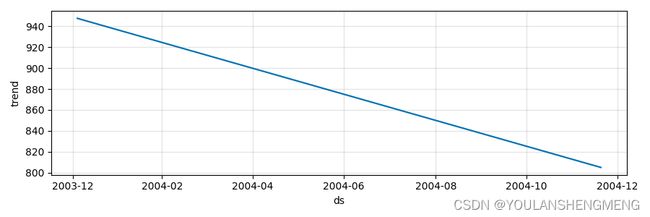
7,从结果中抽取需要的数据
可以直观的看预测和真实值之间的对比
def make_comparison_dataframe(historical, forecast):
return forecast.set_index('ds')[['yhat', 'yhat_lower', 'yhat_upper']].join(historical.set_index('ds'))
cmp_df = make_comparison_dataframe(df, forecast)
cmp_df.head()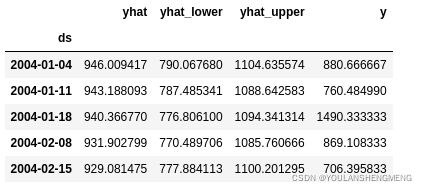
8,使用自己定义的误差计算算法计算预测的误差
def calculate_forecast_errors(df, prediction_size):
df = df.copy()
df['e'] = df['y'] - df['yhat']
df['p'] = 100 * df['e'] / df['y']
predicted_part = df[-prediction_size:]
error_mean = lambda error_name: np.mean(np.abs(predicted_part[error_name]))
return {'MAPE': error_mean('p'), 'MAE': error_mean('e')}
for err_name, err_value in calculate_forecast_errors(cmp_df, prediction_size).items():
print(err_name, err_value)![]()
9,将想要的信息显示在一张图上
plt.figure(figsize=(17, 8))
plt.plot(cmp_df['yhat'])
plt.plot(cmp_df['yhat_lower'])
plt.plot(cmp_df['yhat_upper'])
plt.plot(cmp_df['y'])
plt.xlabel('Time')
plt.ylabel('Average Weekly NOx Concentration')
plt.grid(False)
plt.show()
三,总代码
import warnings
warnings.filterwarnings('ignore')
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from fbprophet import Prophet
import logging
def positive_average(num):
return num[num > -200].mean()
#数据图像显示
def plot_data(col):
plt.figure(figsize=(17, 8))
plt.plot(weekly_data[col])
plt.xlabel('Time')
plt.ylabel(col)
plt.grid(False)
plt.show()
def make_comparison_dataframe(historical, forecast):
return forecast.set_index('ds')[['yhat', 'yhat_lower', 'yhat_upper']].join(historical.set_index('ds'))
def calculate_forecast_errors(df, prediction_size):
df = df.copy()
df['e'] = df['y'] - df['yhat']
df['p'] = 100 * df['e'] / df['y']
predicted_part = df[-prediction_size:]
error_mean = lambda error_name: np.mean(np.abs(predicted_part[error_name]))
return {'MAPE': error_mean('p'), 'MAE': error_mean('e')}
DATAPATH = '/home/kongxianglan/code/air-quality-master/data/AirQualityUCI.csv'
data = pd.read_csv(DATAPATH, sep=';')
data.head()
print(data)
# (9471, 17)
data.shape
# 删除全为空值的行或列
data.dropna(axis=1, how='all', inplace=True)
data.dropna(axis=0, how='all', inplace=True)
# (9357, 15)
data.shape
data.head()
# 数据加载,并将数据转换为浮点型同时将,替换成.
data['Date'] = pd.to_datetime(data['Date'])
for col in data.iloc[:, 2:].columns:
if data[col].dtypes == object:
data[col] = data[col].str.replace(',', '.').astype('float')
#通过取每个测量的平均值来按天汇总数据
daily_data = data.drop('Time', axis=1).groupby('Date').apply(positive_average)
daily_data.head()
print(daily_data)
#摆脱的NaN,如果需要查看有多少个NaN使用语句daily_data.isna().sum()
print("NaN的有")
daily_data.isna().sum()
daily_data.isna().sum() > 8
daily_data = daily_data.iloc[:,(daily_data.isna().sum() <= 8).values]
daily_data.head()
print("去除NaN后有")
daily_data.shape
#二次删除全为空值的行或列
daily_data = daily_data.dropna()
print("二次删除全为空值的行或列")
daily_data.shape
#将数据按周进行重采样
weekly_data = daily_data.resample('W').mean()
weekly_data.head()
print("数据按周进行重采样")
weekly_data
weekly_data = weekly_data.dropna()
weekly_data.shape
#按周显示空气中各个气体含量的数据
for col in weekly_data.columns:
plot_data(col)
#让我们专注于预测氮氧化物的浓度。氮的氧化物会发生反应形成烟雾和酸雨,
# 而且是细颗粒物和地面臭氧形成的核心,这两种物质都与有害健康有关。
#只保留关键的氮氧化物的浓度
cols_to_drop = ['PT08.S1(CO)', 'C6H6(GT)', 'PT08.S2(NMHC)', 'PT08.S4(NO2)', 'PT08.S5(O3)', 'T', 'RH', 'AH']
weekly_data = weekly_data.drop(cols_to_drop, axis=1)
weekly_data.head()
logging.getLogger().setLevel(logging.ERROR)
#真正要预测的数据的加载
df = weekly_data.reset_index()
df.columns = ['ds', 'y']
df.head()
#交叉验证的数据放后面30个数据
prediction_size = 30
train_df = df[:-prediction_size]
m = Prophet()
m.fit(train_df)
future = m.make_future_dataframe(periods=prediction_size)
forecast = m.predict(future)
forecast.head()
m.plot(forecast)
m.plot_components(forecast)
cmp_df = make_comparison_dataframe(df, forecast)
cmp_df.head()
for err_name, err_value in calculate_forecast_errors(cmp_df, prediction_size).items():
print(err_name, err_value)
plt.figure(figsize=(17, 8))
plt.plot(cmp_df['yhat'])
plt.plot(cmp_df['yhat_lower'])
plt.plot(cmp_df['yhat_upper'])
plt.plot(cmp_df['y'])
plt.xlabel('Time')
plt.ylabel('Average Weekly NOx Concentration')
plt.grid(False)
plt.show()