机器学习之线性回归:算法兑现为python代码
- 1 数据预处理
- 2 直接求解参数
- 3 梯度下降求参数
- 4 总结
前面三天推送机器学习线性回归算法之最小二乘法,从假设到原理,详细分析了直接求解和梯度下降两种算法,接下来手动编写python代码实现线性回归的算法吧。
1 数据预处理
在拿到一个数据集后,往往需要经过漫长的预处理过程,不要忽视这个看似与建立模型,求解模型无关的步骤,它其实非常重要的,为后续工作做好准备的一步。现在这节的重点不是在论述预处理的方法,所以在此不详细介绍预处理的过程,而是重点例子模拟线性回归最小二乘法的两个求解方法。
获得了数据集后,经过预处理后得到的数据前10条展示如下,其中第一列为房屋的面积,第二列为房屋使用年限,第三列为房屋的价值,是标签值,这些值都已经经过预处理了。
房屋面积 使用年限 价值
[[ 0.35291809, 0.16468428, 0.35774628],
[-0.55106013, -0.10981663, 0.25468008],
[-0.65439632, -0.71406955, 0.1061582 ],
[-0.19790689, 0.61536205, 0.43122894],
[-0.00171825, 0.66827656, 0.44198075],
[-0.2739687 , -1.16342739, 0.01195186],
[ 0.11592071, -0.18320789, 0.29397728],
[-0.02707248, -0.53269863, 0.21784183],
[ 0.7321352 , 0.27868019, 0.42643361],
[-0.76680149, -0.89838545, 0.06411818]]下面用直接求法和梯度下降法求解线性回归。
首先介绍下使用的库:
'导入numpy库'
import numpy as np
'导入pyplot'
import matplotlib.pyplot as plt
'导入时间模块'
import time本次模拟取数据集的前100条数据进行迭代计算,即 m = 100 。
做一个偏移量和2个特征的组合,这样与前面推送的理论部分衔接在一起,组合的代码
如下所示:
'偏移量 b shape=(100,1)'
b = np.array([1])
b=b.repeat(100)
'将偏移量与2个特征值组合 shape = (100,3)'
X = np.column_stack((b,X))2 直接求解参数
我们知道当我们建立线性回归的模型时,因为是线性的,并且误差项满足高斯分布,此时借助最大似然估计可以直接拿到权重参数的计算公式,如果想看下理论部分,请参考 直接求解 :
![]()
'这是一个求矩阵的逆所用到的模块'
from numpy.linalg import linalg as la
xtx = X.transpose().dot(X)
xtx = la.inv(xtx)
'直接求出参数'
theta = xtx.dot(X.transpose()).dot(y)这个解法很简单,直接套用公式,求出权重参数如下:
array([0.29348374, 0.10224818, 0.19596799])即偏移量为 0.29,第一个特征的权重参数为0.10,第二个特征的权重参数为0.195 。
下面用梯度下降法求解,这才是我们论述的重点,这个思路与机器学习的其他算法,比如逻辑回归等思路是一致的,因此有必要好好研究下。
3 梯度下降求参数
梯度下降的详细介绍,请参考梯度下降求解权重参数部分,下面我们论述如何由理论兑现为代码。
首先列举梯度下降的思路步骤,采取线性回归模型,求出代价函数,进而求出梯度,求偏导是重要的一步,然后设定一个学习率迭代参数,当与前一时步的代价函数与当前的代价函数的差小于阈值时,计算结束,如下思路:
'model' 建立的线性回归模型
'cost' 代价函数
'gradient' 梯度公式
'theta update' 参数更新公式
'stop stratege' 迭代停止策略:代价函数小于阈值法下面分别写出以上五步的具体实现代码,
'model'
def model(theta,X):
theta = np.array(theta)
return X.dot(theta)'cost'
def cost(m,theta,X,y):
'print(theta)'
ele = y - model(theta,X)
item = ele**2
item_sum = np.sum(item)
return item_sum/2/m'gradient'
def gradient(m,theta,X,y,cols):
grad_theta = []
for j in range(cols):
grad = (y-model(theta,X)).dot(X[:,j])
grad_sum = np.sum(grad)
grad_theta.append(-grad_sum/m)
return np.array(grad_theta)'theta update'
def theta_update(grad_theta,theta,sigma):
return theta - sigma * grad_theta'stop stratege'
def stop_stratege(cost,cost_update,threshold):
return cost-cost_update < threshold'OLS algorithm'
def OLS(X,y,threshold):
start = time.clock()
'样本个数'
m=100
'设置权重参数的初始值'
theta = [0,0,0]
'迭代步数'
iters = 0;
'记录代价函数的值'
cost_record=[]
'学习率'
sigma = 0.0001
cost_val = cost(m,theta,X,y)
cost_record.append(cost_val)
while True:
grad = gradient(m,theta,X,y,3)
'参数更新'
theta = theta_update(grad,theta,sigma)
cost_update = cost(m,theta,X,y)
if stop_stratege(cost_val,cost_update,threshold):
break
iters=iters+1
cost_val = cost_update
cost_record.append(cost_val)
end = time.clock()
print("OLS convergence duration: %f s" % (end - start))
return cost_record, iters,theta结果显示经过,OLS梯度下降经过如下时间得到初步收敛,OLS convergence duration: 7.456927 s,经过3万多个时步迭代,每个时步计算代价函数的取值,如下图所示:
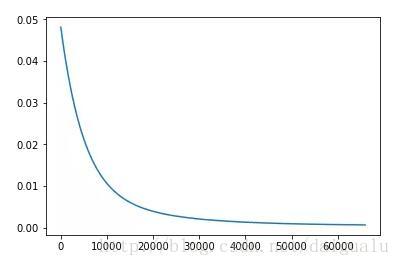
收敛时,得到的权重参数为:
array([ 0.29921652, 0.09754371, 0.1867609 ]) 可以看到梯度下降得到的权重参数与直接求出法得出的基本相似,这其中的误差是因为没有进一步再迭代。
4 总结
以上就是最小二乘法的两种解法的代码实现,至此我们已经将线性回归算法的最基本的OLS从理论,假设,到现在的代码兑现都阐述完了。让我们看一下远边的大海,和巍峨的高山,放松一下吧!

然而,有些数据集的某两列或多列存在强相关性,当面对这样的数据集,OLS还能胜任吗? 如果不能胜任,这其中的原因又是什么呢?
请看明天的推送,OLS算法的缺陷及原理。
欢迎关注「 算法channel 」
交流思想,注重分析,看重过程,包含但不限于:经典算法,机器学习,深度学习,LeetCode 题解,Kaggle 实战,英语沙龙,定期邀请专家发推。期待您的到来!
