【NLP】GRU理解(Pytorch实现)
【参考:YJango的循环神经网络——实现LSTM - 知乎】 强烈建议阅读
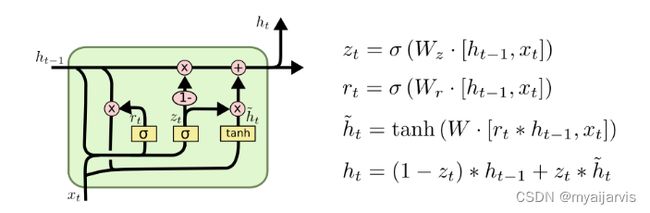

手动实现
- 重置门 r_t
- 更新门 z_t
- 候选隐藏状态 n_t
- h_t 增量更新得到当前时刻最新隐含状态

∗is the Hadamard product.(点乘) 不是矩阵相乘
矩阵元素对应位置相乘

【参考:31 - GRU原理与源码逐行实现_取个名字真难呐的博客-CSDN博客】
【参考:31、PyTorch GRU的原理及其手写复现_哔哩哔哩_bilibili】
单层单向
import torch
from torch import nn
torch.manual_seed(0) # 设置随机种子,随机函数生成的结果会相同
batch_size = 2 # 批次大小
seq_len = 3 # 输入序列长度
input_size = 4 # 输入数据特征大小
hidden_size = 5 # 隐藏层特征大小
num_layers = 1 # 层数
# random init the input
input_one = torch.randn(batch_size, seq_len, input_size) # bs,seq_len,input_size 随机初始化一个特征序列
# random init the init hidden state
h0 = torch.zeros(batch_size, hidden_size) # 初始隐含状态h_0 (bs,hidden_size) pytorch默认初始化全0
# 本来应该是(1,batch_size,hidden_size) 这里为了简便传递参数和下面的计算 因为很多时候传递的参数都是二维
# define the RNN layers
gru_layer = nn.GRU(input_size=input_size,
hidden_size=hidden_size,
num_layers=num_layers,
batch_first=True)
output_api, h_n_api = gru_layer(input_one, h0.unsqueeze(0))
# h_0 对于输入的是批次数据时维度为 (D∗num_layers,bs,hidden_size) 看官方参数
# h_prev.unsqueeze(0) h_prev:(bs,hidden_size)->(1,bs,hidden_size) 这里D为1,num_layers也是1
print(f"output.shape={output_api.shape}")
print(f"h_n.shape={h_n_api.shape}")
print(f"output={output_api}")
print(f"h_n={h_n_api}")
# 获取模型的参数
for k, v in gru_layer.named_parameters():
print(k, v.shape)
weight_ih_l0 torch.Size([15, 4])
weight_hh_l0 torch.Size([15, 5])
bias_ih_l0 torch.Size([15])
bias_hh_l0 torch.Size([15])
"""
weight_ih_l0 是 W_ir,W_iz,W_in三个拼接起来的 (3*5,4)
weight_hh_l0,bias_ih_l0,bias_hh_l0同理
"""
def custom_gru(input, h0, w_ih, w_hh, b_ih, b_hh):
"""
:param input:
:param h0:
:param w_ih: W_ir,W_iz,W_in三个拼接起来的 (3*hidden_size,input_size)
:param w_hh: W_hr,W_hz,W_hn三个拼接起来的 (3*hidden_size,hidden_size)
:param b_ih: 三个拼接起来的
:param b_hh: 三个拼接起来的
:return:
"""
# define the w_times_x
batch_size, seq_len, input_size = input.shape
hidden_size = w_ih.shape[0] // 3
# w_ih.shape=torch.Size([3*hidden_size,input_size])
# batch_w_ih.shape = torch.Size([batch_size,3*hidden_size,input_size])
batch_w_ih = w_ih.unsqueeze(0).tile([batch_size, 1, 1])
# h0.shape=prev_h.shape=torch.Size([batchsize,hidden_size])
prev_h = h0
# w_hh.shape=torch.Size([3*hidden_size,hidden_size])
# batch_w_hh=torch.Size([batch_size,3*hidden_size,hidden_size])
batch_w_hh = w_hh.unsqueeze(0).tile([batch_size, 1, 1])
output = torch.zeros([batch_size, seq_len, hidden_size])
for t in range(seq_len):
# input.shape=torch.Size([batch_size,seq_len,input_size])
# x.shape=torch.Size([batch_size,input_size])->([batch_size,input_size,1])
x = input[:, t, :].unsqueeze(-1)
# batch_w_ih.shape=torch.Size([batch_size,3*hidden_size,input_size])
# w_ih_times_x.shape=torch.Size([batch_size,3*hidden_size,1])->([batch_size,3*hidden_size])
w_ih_times_x = torch.bmm(batch_w_ih, x).squeeze(-1)
# batch_w_hh.shape=torch.Size([batch_size,3*hidden_size,hidden_size])
# prev_h.shape=torch.Size([batch_size,hidden_size])->([batch_size,hidden_size,1])
# w_hh_times_x.shape=torch.Size([batch_size,3*hidden_size,1]) ->([batch_size,3*hidden_size])
w_hh_times_x = torch.bmm(batch_w_hh, prev_h.unsqueeze(-1)).squeeze(-1)
# 重置门
r_t = torch.sigmoid(w_ih_times_x[:, :hidden_size]
+ b_ih[:hidden_size]
+ w_hh_times_x[:, :hidden_size]
+ b_hh[:hidden_size])
# 更新门
z_t = torch.sigmoid(w_ih_times_x[:, hidden_size:2 * hidden_size]
+ b_ih[hidden_size:2 * hidden_size]
+ w_hh_times_x[:, hidden_size:2 * hidden_size]
+ b_hh[hidden_size:2 * hidden_size])
# 候选状态
n_t = torch.tanh(w_ih_times_x[:, 2 * hidden_size:3 * hidden_size]
+ b_ih[2 * hidden_size:3 * hidden_size]
+ r_t
* (w_hh_times_x[:, 2 * hidden_size:3 * hidden_size] + b_hh[2 * hidden_size:3 * hidden_size]))
prev_h = (1 - z_t) * n_t + z_t * prev_h # 增量更新得到当前时刻最新隐含状态
output[:, t, :] = prev_h
return output, prev_h.unsqueeze(0)
cu_input = input_one
cu_h0 = h0
cu_w_ih = gru_layer.weight_ih_l0
cu_w_hh = gru_layer.weight_hh_l0
cu_b_ih = gru_layer.bias_ih_l0
cu_b_hh = gru_layer.bias_hh_l0
custom_output, custom_hn = custom_gru(cu_input, cu_h0, cu_w_ih, cu_w_hh, cu_b_ih, cu_b_hh)
print(f"custom_output.shape={custom_output.shape}")
print(f"custom_hn.shape={custom_hn.shape}")
print(f"custom_output={custom_output}")
print(f"custom_hn={custom_hn}")
print("output is equal ?")
print(torch.isclose(custom_output, output_api))
print("h_n is equal ?")
print(torch.isclose(custom_hn, h_n_api))
...
output is equal ?
tensor([[[True, True, True, True, True],
[True, True, True, True, True],
[True, True, True, True, True]],
[[True, True, True, True, True],
[True, True, True, True, True],
[True, True, True, True, True]]])
h_n is equal ?
tensor([[[True, True, True, True, True],
[True, True, True, True, True]]])