matplotlib数据可视化
matplotlib库主要做数据可视化。
代码举例:
from matplotlib import pyplot as plt
# 准备x轴的值
x = range(2, 26, 2)
# 准备y轴的值
y = [12, 15, 13, 33, 44, 22, 21, 21, 23, 10, 12, 13]
# 设置图片大小
plt.figure(figsize=(20, 8), dpi=80)
plt.plot(x, y)
# 保存图片
plt.savefig("./t1.png")
# 展示图片
plt.show()对手写数字降维后inverse_transform进行去除噪音与原噪音数据画图对比
x_dr_inverse = pca.inverse_transform(x_dr)
print(x_dr_inverse.shape)
fig, axes = plt.subplots(2, 10,
figsize=(8, 4),
subplot_kw={"xticks":[], "yticks":[]})
for i in range(10):
axes[0, i].imshow(noisy[i, :].reshape(8, 8), cmap="gray")
axes[1, i].imshow(x_dr_inverse[i, :].reshape(8, 8), cmap="gray")用matplotlib画出PCV学习曲线,随着PCA维度提高,查看分数有何变化,找到分数最高的点,PCA的值
scores = []
for i in range(10, 60, 10):
x_dr = PCA(i).fit_transform(X)
RFC = RandomForestClassifier(n_estimators=100, random_state=30)
once = cross_val_score(RFC, x_dr, y, cv=5).mean()
scores.append(once)
plt.figure(figsize=(10, 5))
plt.plot(range(10, 60, 10), scores)
plt.show()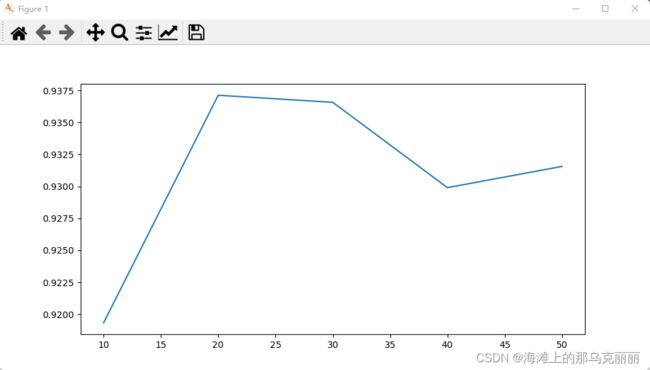
使用嵌入法进行特征选择(将维),随着逻辑回归参数重要程度的增加,使得维度不断减小,查看模型分值的变化。
lr = LogisticRegression(penalty='l2', solver='liblinear', C=0.8, random_state=30, max_iter=100, multi_class='ovr')
# print(cross_val_score(lr, X, y, cv=10).mean())
# norm_order用l1范数进行进行筛选,模型会筛选掉l1范数后为0的特征
# sfm = SelectFromModel(lr, norm_order=1).fit_transform(X, y)
# print(sfm.shape)
# print(cross_val_score(lr, sfm, y, cv=10).mean())
threshold = np.linspace(0, abs(lr.fit(X, y).coef_).max(), 20)
lbc_scores = []
sfm_scores = []
k = 0
for i in threshold:
sfm = SelectFromModel(lr, threshold=i).fit_transform(X, y)
lbc_score = cross_val_score(lr, X, y, cv=5).mean()
sfm_score = cross_val_score(lr, sfm, y, cv=5).mean()
sfm_scores.append(sfm_score)
lbc_scores.append(lbc_score)
print(threshold[k], sfm.shape[1])
k += 1
plt.figure(figsize=(15, 5))
plt.plot(threshold, sfm_scores, label='feature selection')
plt.plot(threshold, lbc_scores, label='full')
plt.xticks(threshold)
plt.legend()
plt.show()
将画图封装成函数并循环测试每种不同算法模型的效率。
# 生成子图
def plot_learning_curve(estimator, title, X, y, ax, ylim=None , cv=None, n_jobs=None):
train_sizes_abs, train_scores, test_scores = learning_curve(estimator, # 分类器名称
X, y, # 特征矩阵和标签
cv=cv, # 交叉验证
n_jobs=n_jobs) # 每次运行的时候可以开多少计算机线程,-1代表计算机所有线程
ax.set_title(title)
if ylim is not None:
ax.set_ylim(*ylim)
ax.set_xlabel("Training examples")
ax.set_ylabel("Score")
ax.grid() # 显示网格线
ax.plot(train_sizes_abs, np.mean(train_scores, axis=1), 'o-', color="r", label="Training score")
ax.plot(train_sizes_abs, np.mean(test_scores, axis=1), 'o-', color='g', label="Test score")
ax.legend(loc="best")
return ax
title = ["Naive", "DecisionTree", "SVM RBF kernel", "RandomForest", "Logistiv" ]
model = [GaussianNB(), DecisionTreeClassifier(), SVC(gamma=0.001), RandomForestClassifier(n_estimators=50), LogisticRegression(C=.1, solver="sag", max_iter=1000)]
cv = ShuffleSplit(n_splits=50, test_size=0.2, random_state=0)
fig, axes = plt.subplots(1, 5, figsize=(30, 6))
for ind, title_, estimator in zip(range(len(title)), title, model):
# times = time()
plot_learning_curve(estimator, title_, X, y, ax=axes[ind], ylim=[0.7, 1.05], n_jobs=4, cv=cv)
plt.show()
"""
# 用sklearn自带类画学习曲线
cv = ShuffleSplit(n_splits=50, # 把数据分为多少份
test_size=0.2, # 50份的20%的数据集作为测试集,大概意思就是分五十份,百分之二十是测试集,百分之八十是测试集
random_state=0)
# 交叉验证
# train_sizes_abs 每次分训练集和测试集建模之后,训练集上的样本数量
# train_scores 训练集上的分数
# test_scores 测试集上的分数
train_sizes_abs, train_scores, test_scores = learning_curve(gnb, # 分类器名称
X, y, # 特征矩阵和标签
cv = cv, # 交叉验证
n_jobs=4) # 每次运行的时候可以开多少计算机线程,-1代表计算机所有线程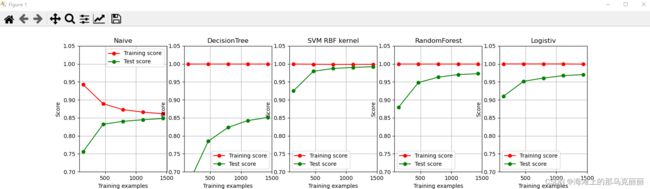
上述代码改进后的代码
# 画出学习曲线
def study_curve(estimator, X, y, cv, title, ax=None, ylim=None, n_jobs=None):
train_sizes_abs, train_score, test_score = learning_curve(estimator, X, y, cv=cv, n_jobs=n_jobs)
if ax is not None:
ax.set_title(title)
if ylim is not None:
ax.set_ylim(*ylim)
ax.set_xlabel("train_samples")
ax.set_ylabel("score")
ax.grid()
ax.plot(train_sizes_abs, np.mean(train_score, axis=1), 'o-', color='r', label="train_score")
ax.plot(train_sizes_abs, np.mean(test_score, axis=1), 'o-', color='r', label="test_score")
ax.legend()
else:
plt.title(title)
if ylim is not None:
plt.ylim(*ylim)
plt.xlabel("train_samples")
plt.ylabel("score")
plt.grid()
plt.plot(train_sizes_abs, np.mean(train_score, axis=1), 'o-', color='r', label="train_score")
plt.plot(train_sizes_abs, np.mean(test_score, axis=1), 'o-', color='g', label="test_score")
plt.legend()
cv = ShuffleSplit(n_splits=50, test_size=0.2, random_state=10)
# fig, axes = plt.subplots(1,1,
# figsize=(10,10))
# cv = KFold(n_splits=5, shuffle=True, random_state=42)
study_curve(XGBRegressor(n_estimators=100), X_train, y_train, cv, title="XGBRegressor", ax=None, ylim=[0.5, 1.2], n_jobs=-1)
plt.show()