【推荐算法】DSSM双塔模型:Deep Structured Semantic Models for Web Search using Clickthrough Data
1、DSSM背景
DSSM,全称Deep Structured Semantic Model,就是我们通常所说的双塔模型,是微软公司提出的一种基于深度神经网络的语义模型,其核心思想是将query和doc映射到到共同维度的语义空间中,通过最大化query和doc语义向量之间的余弦相似度,从而训练得到隐含语义模型,达到检索的目的。
潜在语义模型的意图是在语义级映射一个query到它的相关documents中,然而这种基于关键词的匹配经常失败。为此,一系列的新的基于深度结构的潜在语义模型被提出,这类模型能够映射query和documents到共同的低维空间中,而且给定query对应的document的相关性可以通过距离的方式计算出来。提出的DSSM模型可以通过”使用点击数据最大化给定query点击过的documents的条件概率“进行训练。为了使模型适用于更大规模的网络检索,DSSM使用了一种词哈希的方法,该方法能够有效地缩减语义模型的规模。DSSM模型通过一个真实数据集的网络文档排序实验进行了评估,结果表明DSSM模型明显优于当前阶段的其他潜在语义模型。
虽然DSSM的提出是为了解决搜索问题,但是在推荐系统领域,DSSM也表现出了强大的竞争力,其效果不错并且对工业界十分友好,所以被各大厂广泛应用于推荐系统中。通过构建user和item两个独立的子网络,将训练好的两个“塔”中的user embedding 和item embedding各自缓存到内存数据库中。线上预测的时候只需要在内存中计算相似度运算即可。DSSM双塔模型是推荐领域中非常值得掌握的一个重要模型。
论文的introduction部分首先介绍其他模型的一些不足:PLSA模型和LDA模型通过一个松散耦合的目标函数以一种无监督的方式进行训练,很难达到符合预期的表现。其次,给出了潜在语义模型的两条研究线:基于点击数据、基于深度自编码。基于点击数据的BLTM模型和DPM模型,前者在文档排序上并不能达到最佳表现,后者在训练过程中涉及一个大规模矩阵乘法问题,因此训练时间会很大。基于深度学习的模型采样的是无监督训练的方法,其表现不能过明显优于基于关键词匹配的baseline召回方法,同时这些模型也面临着同样的矩阵乘法问题。
综合上述两条研究线,解决文档排序的DSSM模型问世了。
首先,通过一个非线性投影将query和documents映射到一个共同的语义空间。其次,对于给定query和每个documents的相关性,通过语义空间下向量间的一个余弦相似度计算出。神经网络模型使用点击数据进行训练,因此给定query的点击documents的条件概率能够最大化。不同于之前的一些无监督方式学习的潜在语义模型,DSSM直接针对网络文档排序进行优化,因此得到了不错的表现。而且在处理大规模词汇表时,DSSM采用了一种词哈希的方法,在没有任何损失的情况下,将高维的queries和documents向量映射到低维letter-n-gram向量。在语义模型中增加了这一层,词哈希方法能够支持大规模词汇表,这在网络检索中尤为重要。
2、DSSM Related Work
论文的这部分主要介绍了“Latent Semantic Models and the Use of Clickthrough Data”和"Deep Learning"这两类模型,没啥干货,pass了。
3、DSSM算法细节
3.1 DNN for Computing Semantic Features
首先给出DSSM结构图:


DSSM网络结构解释:
- Term Vector:表示文本的embedding向量。
- Word Hashing:为解决term vector太大问题,对bag-of-word向量降维。
- Multi-layer nonlinear projection:表示深度学习网络的隐层。
- Semantic feature:表示query和document最终的embedding向量。
- Relevance measured by cosine similarity:表示query与document之间的余弦相似度。
- Posterior probability computed by softmax:表示通过softmax函数把query与正样本document的语义相似性转化为一个后验概率。
DSSM使用一个DNN模型将语义空间中的高维稀疏文本特征映射到低维稠密特征。第一个隐藏层包含30k个神经元,用于词哈希操作。词哈希特征然后经过多层非线性映射,最后一层的神经元生成了DNN模型的语义空间特征。
DNN模型的输入(raw text features)是一个高维term vector,即一个query或者是一个未经标准化的document,DNN模型的输出是一个低维语义特征空间中的概念向量。
这样的DNN模型可以用于网络文档排序:
- 匹配term vector到对应的语义概念向量
- 计算query和document之间的相关性打分(通过对应的语义概念向量的cosine相似度)
假设:
- x是输入的term向量;
- y是输出向量;
 表示中间的隐藏层,i=1,2,... ,N-1;
表示中间的隐藏层,i=1,2,... ,N-1; 表示第i个权重矩阵;
表示第i个权重矩阵; 是第i个偏置项。
是第i个偏置项。
于是,结合神经网络的结构,可以得到:
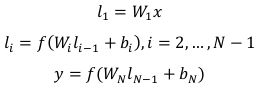
在输出层和隐藏层![]() 使用tanh作为激活函数,这样一个query和一个document的语义相关性打分可以通过下面的公式计算得到:
使用tanh作为激活函数,这样一个query和一个document的语义相关性打分可以通过下面的公式计算得到:

这里,![]() 和
和![]() 分别表示query和document的概念向量。这样的话,在网页检索任务中,给定一个query,documents可以被计算出来的语义相关性打分排序。
分别表示query和document的概念向量。这样的话,在网页检索任务中,给定一个query,documents可以被计算出来的语义相关性打分排序。
激活函数tanh的公式和曲线:

![]()

Term vector的大小,通常被当作信息检索领域的原始词袋特征,其规模通常非常大。因此,当使用term vector作为输入时,输入层神经网络的规模对于计算和模型训练来说都变得难以处理。为了解决这个问题,DSSM针对DNN的第一层提出了一个“word hashing”的方法,这一层只由线性隐层单元(不需要学习大规模的权重矩阵)组成。
3.2 Word Hashing
word hashing方法意在减少词袋term vector的维度,word hashing是在字母n-gram的基础上为DSSM提出的一种新的方法:word hashing。word hashing方法优点是可以降低term vector的维度,缺点是存在一定的冲突问题。
word hashing方法:给定一个词,以单词good为例,首先在该单词上添加开始和结束标记:#good#。然后将其转换成字母n-gram的形式:letter trigrams: #go, goo, ood, od#。最后,这个词将通过一个字母n-gram向量表示。
这样的方法可能存在两个不同的词语有着相同的字母n-gram向量表示的问题,也就是冲突问题。与原始的one-hot向量表示相比,word hashing方法可以使用一个更低维度的向量来表示一个query或者一个document。
如果词汇表的规模是40k,那么使用letter trigrams方法每个词可以被一个10306维度的向量表示,四倍的维度减少。通常,词汇表的规模越大,维度减少的意义越大。举个列子,如果词汇表的规模是500k,那么其中的每个词可以被一个30621维度的向量表示,这是一个16倍的维度减少。然而,发生冲突的概率仅仅是0.0044%。
word hashing方法可以映射相同单词的变种到letter n-gram空间中的近似的点上。当一个单词在训练数据集中从未出现时,基于word的表示word hashing总会带来一些问题,其原因不在于使用了基于letter n-gram的向量表示。唯一的风险在于冲突问题。基于word hashing的letter n-gram方法对于词汇表之外的单词也能表现出一定的鲁棒性,这允许我们可以降低DNN的规模,
基于word hashing的letter n-gram方法可以被当作是一种固定的线性变换,通过这个线性变换,输入层的一个term vector可以被映射成一个网络中下一层的letter n-gram向量。由于letter n-gram向量的维度通常很低,这就可以使得DNN模型能够有效地学习。
补充说明:DSSM模型的输入层主要的作用就是把文本映射到低维向量空间转化成向量提供给深度学习网络。然而在NLP领域里中英文的差异比较大,在输入层处理方式也不同。
英文的输入层可以通过word hashing方法处理,该方法基于字母的n-gram,主要作用是减少输入向量的维度。
中文输入层和英文有很大差别,首先要面临的是分词问题。如果要分词推荐jieba或者北大 pkuseg,不过现在很多模型已经不进行分词了,比如BERT中文的预训练模型就直接使用单字作为最小粒度了。
3.3 Learning the DSSM
点击日志通常由一系列queries和点击的documents组成。
假设一个query对应的点击过的documents是相关的。为了最大化给定query对应的点击的documents的条件概率,DSSM提出了一个有监督训练的方法去学习模型参数,模型参数即神经网络中的权重矩阵和偏置向量。
首先,我们根据query和document的语义相关性打分通过一个softmax函数来计算给定query的document的后验概率:

这里,
 是softmax函数的平滑因子,通常在held-out数据集上经验设置;
是softmax函数的平滑因子,通常在held-out数据集上经验设置;- D表示待排序的候选documents,理想状态下,D应该包含所有可能的documents;
- Q表示一个query,
 表示被点击过的document;
表示被点击过的document; - (Q,)表示query、clicked-document对。
DSSM估计D通过被点击过的document和4个随机选择的未被点击过的documents(![]() )。实验表明,选择未被点击过documents的采样策略并不会影响训练结果。
)。实验表明,选择未被点击过documents的采样策略并不会影响训练结果。
模型参数的训练都是在训练集上最大化给定查询queries的被点击documents的概率来获得,也即我们需要最小化下面的损失函数:

这里, 表示神经网络
表示神经网络![]() 的参数,其学习过程采用了一种基于梯度的数学优化算法。
的参数,其学习过程采用了一种基于梯度的数学优化算法。
3.4 Implementation Details
为了确定训练参数并防止过拟合,实验将点击数据分成不重叠的两部分:训练集和验证集。实验过程中,模型在训练集上训练,训练参数在验证集上进行优化。
DNN模型使用了3个隐藏层的结构。
第一个隐层是word hashing层,包含30k个结点,即letter-trigrams的大小是30k。
接下来的两个隐藏层分别有300个隐藏结点。
输出层有128个结点,即输出层的维度是128维。
word hashing是基于一个固定的投影矩阵,输出层的维度是128维,128维向量用来计算相似性。在训练阶段,模型的训练采用的是基于SGD的mini-batch方法,每个mini-batch包含1024个训练样本。实验表明,DNN模型通常在整个数据集上迭代20轮之内达到收敛。
4、 DSSM模型在推荐召回环节的应用
DSSM模型的最大特点就是Query和Document是两个独立的子网络,后来这一特色被移植到推荐算法的召回环节,即对用户端(User)和物品端(Item)分别构建独立的子网络塔式结构。
DSSM双塔模型结构图:

双塔模型两侧分别对(用户,上下文)和(物品)进行建模,并在最后一层计算二者的内积。
其中:
 为(用户,上下文)的特征,
为(用户,上下文)的特征, 为(物品)的特征。
为(物品)的特征。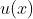 表示(用户,上下文)最终的embedding向量表示,
表示(用户,上下文)最终的embedding向量表示, 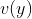 表示(物品)最终的 embedding向量表示。
表示(物品)最终的 embedding向量表示。- <,>表示(用户,上下文)和(物品)的余弦相似度。
当模型训练完成时,item的embedding是可以保存成词表的,线上应用的时候只需要查找对应的 embedding 可。因此线上只需要计算 (用户,上下文) 一侧的embedding,基于Annoy或Faiss 技术索引得到用户偏好的候选集。
DSSM双塔召回流程:
DSSM模型首先将原始的文本特征映射到低维的语义空间。query和document
假设:query = 苹果手机 价格, document = Iphone Xs 最低 售价 11399 元 Iphone X 价格 6999 元。
- 首先将query和document表示为词频向量,该向量由每个单词出现的词频组成。
构建词汇表:
苹果手机 Iphone x Xs 价格 最低 售价 6999 11399 元得到query向量和document向量:

- 然后将
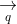 和
和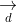 分别映射到低维语义空间,分别得到query
分别映射到低维语义空间,分别得到query的语义向量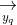 和document
和document的语义向量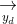 。
。 - 计算和的相似度:

-
给定query,计算所有document与它的相似度,并截取topK个document即可得到召回结果。
5、DSSM小结
DSSM在推荐、搜索和广告领域都取得了广泛的应用,模型首先的一个用处即为Embedding化user和item,方便实时推荐计算,即通过两个DNN,将user和item的特征各自输入,训练出两个k维的向量u(x)和v(y),存入到redis这样的缓存数据库中,线上系统开始推荐时,获取用户的embedding,直接与各个item的embedding进行计算,得到对应的推荐序列。为了取得更好的推荐效果,很多公司都对模型结构进行了一些改进(这里只给出网络结构图不做详细介绍):
百度的双塔模型:

谷歌的双塔模型:

6、参考资料
- DSSM论文
- OPPO互联网技术:推荐系统中不得不说的DSSM双塔模型
- 公众号:推荐系统中不得不说的DSSM双塔模型