MyDLNote-Transformer: 局部和全局的 Transformer - Transformer in Transformer
Transformer in Transformer

https://arxiv.org/pdf/2103.00112v1.pdf
https://github.com/NZ99/transformer_in_transformer_flax
https://github.com/huawei-noah/noah-research/tree/ master/TNT
目录
Abstract
Introduction
Approach
Experiments
Abstract
Transformer is a type of self-attention-based neural networks originally applied for NLP tasks. Recently, pure transformer-based models are proposed to solve computer vision problems. These visual transformers usually view an image as a sequence of patches while they ignore the intrinsic structure information inside each patch.
In this paper, we propose a novel Transformer-iN-Transformer (TNT) model for modeling both patch-level and pixel-level representation.
In each TNT block, an outer transformer block is utilized to process patch embeddings, and an inner transformer block extracts local features from pixel embeddings. The pixel-level feature is projected to the space of patch embedding by a linear transformation layer and then added into the patch. By stacking the TNT blocks, we build the TNT model for image recognition.
Experiments on ImageNet benchmark and downstream tasks demonstrate the superiority and efficiency of the proposed TNT architecture. For example, our TNT achieves 81.3% top-1 accuracy on ImageNet which is 1.5% higher than that of DeiT with similar computational cost.
研究对象/背景/motivation(前三句):Transformer / 纯 Transformer 开始用在计算机视觉领域中 / 这些 TiV 将分割的图像 patch 看作序列,但忽略了每个 patch 内部的内在结构信息。
本文核心内容:一句话浓缩本文的研究精髓,本文提出 TNT,同时对 patch-level 和 pixel-level 的表示建模。
方法具体介绍:1)1 个 TNT block 包括 1 个 outer transformer block 用于处理 patch embeddings,和 1 个 inner transformer block 用于从 pixel embeddings 提取局部特征。2)pixel-level 的局部特征通过线性变换层映射为 patch embedding。3)通过 TNT block 堆叠,构建了图像识别网络。
实验结果:结论就是比另一个 transformer 模型 DeiT 要强。
Introduction
Transformer is a type of neural network mainly based on self-attention mechanism [34]. Transformer is widely used in the field of natural language processing (NLP), e.g., the famous BERT [9] and GPT3 [4] models. Inspired by the breakthrough of transformer in NLP, researchers have recently applied transformer to computer vision (CV) tasks such as image recognition [10, 31], object detection [5, 39], and image processing [6]. For example, DETR [5] treats object detection as a direct set prediction problem and solve it using a transformer encoder-decoder architecture. IPT [6] utilizes transformer for handling multiple low-level vision tasks in a single model. Compared to the mainstream CNN models [20, 14, 30], these transformer-based models have also shown promising performance on visual tasks [11].
研究背景:Transformer 在 NLP 中产生巨大影响,现在开始进军 CV 领域,例如 DETR 和 IPT。
CV models purely based on transformer are attractive because they provide an computing paradigm without the image-specific inductive bias, which is completely different from convolutional neural networks (CNNs). Chen et.al proposed iGPT [7], the pioneering work applying pure transformer model on image recognition by self-supervised pre-training. ViT [10] views an image as a sequence of patches and perform classification with a transformer encoder. DeiT [31] further explores the data-efficient training and distillation of ViT. Compared to CNNs, transformer-based models can also achieve competitive accuracy without inductive bias, e.g., DeiT trained from scratch has an 81.8% ImageNet top-1 accuracy by using 86.4M parameters and 17.6B FLOPs.
研究进展:主要介绍了 Ttransformer 在 CV 中的优势是什么,以及早期的 ViT 方法,如 iGPT,ViT,DeiT。
In ViT [10], an image is split into a sequence of patches and each patch is simply transformed into a vector (embedding). The embeddings are processed by vanilla transformer block. By doing so, ViT can process images by a standard transformer with few modifications. This design also affects the subsequent works including DeiT [31], ViT-FRCNN [2], IPT [6] and SETR [38]. However, these visual transformers ignore the local relation and structure information inside the patch which is important for visual recognition [22, 3]. By projecting the patch into a vector, the spatial structure is corrupted and hard to learn.
提出动机:这一段清晰的讲述了提出动机的逻辑。传统的 ViT 方法将图片 split 成几个 image patch,这些 patches 被简单地当作 embedding 作为传统 Transformer 的输入,甚至 Transformer 的结构都可以不用改变。这种方法用在了很多 ViT 模型当中,如 DeiT, ViT-FRCNN, IPT and SETR。但注意到,这种方法只是计算了 patch 之间的长距离建模,并没有考虑到 patch 内部的局部关系和结构信息,但这些信息对于视觉识别还是很重要的。通过简单的将 patch 映射到 vector,会损失空间结构,很难学习有效信息。
In this paper, we propose a novel Transformer-iN-Transformer (TNT) architecture for visual recognition as shown in Fig. 1. Specifically, an image is split into a sequence of patches and each patch is reshaped to (super) pixel sequence. The patch embeddings and pixel embeddings are obtained by a linear transformation from the patches and pixels respectively, and then they are fed into a stack of TNT blocks for representation learning.
In the TNT block, there are two transformer blocks where the outer transformer block models the global relation among patch embeddings, and the inner one extracts local structure information of pixel embeddings. The local information is added on the patch embedding by linearly projecting the pixel embeddings into the space of patch embedding. Patch-level and pixel-level position embeddings are introduced in order to retain spatial information. Finally, the class token is used for classification via a MLP head. Through the proposed TNT model, we can model both global and local structure information of the images and improve the representation ability of the feature.
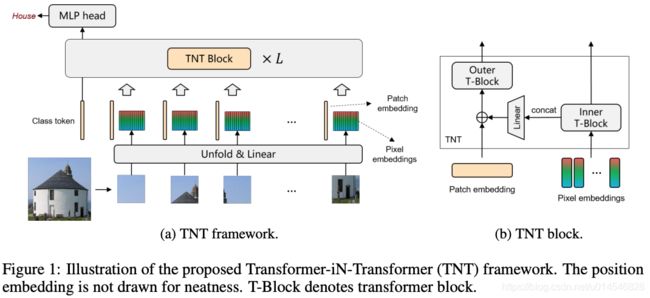
算法介绍:根据上述动机,本文提出了 TNT。具体过程:
1)embedding 提取:
1. 图像 split 成 patch 序列,再 reshape 到 pixel 序列;
2. 然后这些 patch 序列和 pixel 序列经过线性变换,得到 patch embedding 和 pixel embedding;这些 embeddings 将输入到 TNT blocks 中,进行表征学习;
2)TNT block:
3. TNT block 包括 outer transformer block(负责建模 patch 间到全局关系)和 inner transformer block(负责提取 pixel embedding 到局部结构信息;
4. pixel embedding 通过线性映射到 patch embedding 空间,得到的局部信息将与 patch embedding 相加;
5. 为了保留空间信息,引入了 patch-level 和 pixel-level 的 position embedding;
6. 通过多层感知器 head,class token 用于图像分类。
通过 TNT 模型,可以同时对全局和局部结构信息建模,并且提高特征的表征能力。
Approach
Preliminaries
We first briefly describe the basic components in transformer [34], including MSA (Multi-head Self-Attention), MLP (Multi-Layer Perceptron) and LN (Layer Normalization).
Transformer 的三个基本成分:多头自注意力 MSA,多层感知器 MLP,层归一化 LN。很基础的 transformer 结构,懂的可以直接跳过本小节。
- MSA
In the self-attention module, the inputs
are linearly transformed to three parts, i.e., queries
, keys
and values
where n is the sequence length, d, dk, dv are the dimensions of inputs, queries (keys) and values, respectively. The scaled dot-product attention is applied on Q, K, V :
(1)
Finally, a linear layer is used to produce the output.
Multi-head self-attention splits the queries, keys and values for h times and perform the attention function in parallel, and then the output values of each head are concatenated and linearly projected to form the final output.
MSA:对于每一个 SA,首先,输入X 经过三个线性变换得到 Q,K,V;然后进行 scaled 点积注意力,再经过线性映射得到当前输出;对于 MSA,包含 h 个 SA,每个 SA 的输出 concatenated 后,经过线性映射得到最终输出。
- MLP
The MLP is applied between self-attention layers for feature transformation and non-linearity:
(2)
where
are weights of the two fully-connected layers respectively,
are the bias terms, and σ(·) is the activation function such as GELU [15].
MLP:应用于自注意层之间,用于特征变换和引入非线性。
两个全连接层,最后激活层为 GELU。
- LN
Layer normalization [1] is a key part in transformer for stable training and faster convergence. LN is applied over each sample x ∈ R d as follows:
where
are the mean and standard deviation of the feature respectively, ◦ is the element-wise dot, and
are learnable affine transform parameters.
LN:层归一化[1]是 transformer 稳定训练和快速收敛的关键部分。
Transformer in Transformer
Given a 2D image, we uniformly split it into n patches
, where (p, p) is the resolution of each image patch. ViT [10] just utilizes a standard transformer to process the sequence of patches which corrupts the local structure of a patch, as shown in Fig. 1(a). Instead, we propose Transformer-iN-Transformer (TNT) architecture to learn both global and local information in an image. In TNT, each patch is further transformed into the target size (p ' , p' ) with pixel unfold [26], and with a linear projection, the sequence of patch tensors is formed as
where
, and c is the number of channels.
In particular, we view each patch tensor
as a sequence of pixel embeddings:
where
embedding 生成的基本形式就是:input - split - transformed - reshape
图像 - patch - target size (p ' , p' ) - embeddings
In TNT, we have two data flows in which one flow operates across the patch and the other processes the pixels inside each patch.
在 TNT 中,有两个数据流,其中一个是跨 patch 处理,另一个 patch 内的像素处理。
- For the pixel embeddings
we utilize a transformer block to explore the relation between pixels:
(6)(7)
where l = 1, 2, · · · , L is index of the l-th layer, and L is the total number of layers. All patch tensors after transformation are
. This can be viewed as an inner transformer block, denoted as Tin. This process builds the relationship among pixels by computing interactions between any two pixels. For example, in a patch of human face, a pixel belonging to the eye is more related to other pixels of eyes while interacts less with forehead pixels.
对于 pixel embedding,用 transformer block 挖掘 pixel 之间的关系。这个很容易理解,其实就是对每个 image patch 做自注意力。
- For the patch level
we create the patch embedding memories to store the sequence of patch-level representations:
where Zclass is the classification token similar to ViT [10], and all of them are initialized as zero.
In each layer, the patch tensors are transformed into the domain of patch embeddings by linear projection and added into the patch embeddings:
(8)
where
flattens the input to a vector, and
are the weights and bias respectively. We use the standard transformer block for transforming the patch embeddings:
(9) (10)
This outer transformer block Tout is used for modeling relationship among patch embeddings.
1. pixel embaddings 通过 Vec() 拉伸成向量,经过线性变换到与 patch embedding 相同尺度;再与 bias 和输入 patch embedding 相加;即得到了融合 patch 和 pixel 的 embedding;
2. 新的 embedding 再经过传统的 transformer block,来建模 patch 之间的关系。
In summary, the inputs and outputs of the TNT block include the pixel embeddings and patch embeddings as shown in Fig. 1(b), so the TNT can be formulated as
综上所述,TNT 块的输入输出包括 pixel 和 patch embeddings。
In our TNT block, the inner transformer block is used to model the relationship between pixels for local feature extraction, and the outer transformer block captures the intrinsic information from the sequence of patches. By stacking the TNT blocks for L times, we build the transformer-in-transformer network. Finally, the classification token serves as the image representation and a fully-connected layer is applied for classification.
本文中,TNT block 有 L 层。最后,分类输出采用全连接层。
- Position encoding
Spatial information is an important factor in image recognition. For patch embeddings and pixels embeddings, we both add the corresponding position encodings to retain spatial information as shown in Fig. 2. The standard learnable 1D position encodings are utilized here. Specifically, each patch is assigned with a position encodings:
where
are the patch position encodings. As for the pixels in a patch, a pixel position encoding is added to each pixel embedding:
where
are the pixel position encodings which are shared across patches. In this way, patch position encoding can maintain the global spatial information, while pixel position encoding is used for preserving the local relative position.
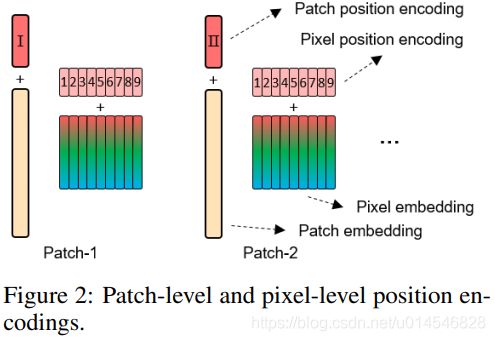
在图像识别中,位置信息是很重要的。为了保持位置信息,需要在 patch 和 pixel embedding 上加上 position encoding。本文的方法也很简单,就是分别在两种 embedding 上加上相应的 position encoding,和传统方法一样。这样就同时保持了全局空间信息和局部空间信息。
Complexity Analysis
- 标准 Transformer 情况
A standard transformer block includes two parts, i.e., the multi-head self-attention and multi-layer perceptron. The FLOPs of MSA are
, and the FLOPs of MLP are
where r is the dimension expansion ratio of hidden layer in MLP. Overall, the FLOPs of a standard transformer block are
(14)
Since r is usually set as 4, and the dimensions of input, key (query) and value are usually set as the same, the FLOPs calculation can be simplified as
The number of parameters can be obtained as
(16)
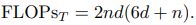
先解读一下(14)怎么算出来的:
1. 看公式(1)上面那段,输入 X 变换到 Q、K、V 时,FLOPs 分别为 ![]() ,
, ![]() ,和
,和 ![]() ;
;
2. 公式(1)的 FLOPs 为 ![]() (QK 点积) +
(QK 点积) +![]() (和 V 的点积);
(和 V 的点积);
3. (1)的输出是 ![]() 维的,需要经过线性变换到与输入相同的维度,此时的 FLOPs 为
维的,需要经过线性变换到与输入相同的维度,此时的 FLOPs 为 ![]()
4. 公式 (2)两次线性变换,分别为 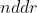 和
和 ![]() 即
即 ![]() 。
。
- 本文 TNT 情况
Our TNT block consists of three parts: an inner transformer block Tin, an outer transformer block Tout and a linear layer. The computation complexity of Tin and Tout are
and
respectively. The linear layer has FLOPs of nmcd. In total, the FLOPs of TNT block are
Similarly, the parameter complexity of TNT block is calculated as
本文的算法的 FLOPs 主要包括三个部分:Tout,Tin,和二者结合后的线性变换的融合部分。
Tout:和传统 Transformer 是一样的;
Tin:在这里,c 对应 Tout 中的 d,m 对应 Tout 中的 n;所以,对于一个 Tin,FLOPs 应该是 ![]() (类似公式 (15))。n 个 Tin 就是
(类似公式 (15))。n 个 Tin 就是 ![]() ;
;
融合:即公式(8),需要 FLOPs 是 ![]() 。
。
- 对比
Although we add two more components in our TNT block, the increase of FLOPs is small since
in practice. For example, in the ViT-B/16 configuration, we have d = 768 and n = 196. We set c = 12 and m = 64 in our structure of TNT-B correspondingly. From Eq. 15 and Eq. 17, we can obtain that
and
. The FLOPs ratio of TNT block over standard transformer block is about 1.09×. Similarly, the parameters ratio is about 1.08×. With a small increase of computation and memory cost, our TNT block can efficiently model the local structure information and achieve a much better trade-off between accuracy and complexity as demonstrated in the experiments.
看似 TNT 的 FLOPs 和参数量都比传统的 Transformer 加了东西,但实际加的东西很小,因为 ![]() 。最后的结论是:
。最后的结论是:
TNT 的 FLOPs 是传统 Transformer 的 1.09 倍;参数量是 1.08 倍。
【本文的方法目的并不是降低计算复杂度,而是在引入非常轻量级的模块时,显著提高性能】
Network Architecture
We build our TNT architectures by following the basic configuration of ViT [10] and DeiT [31]. The patch size is set as 16×16. The unfolded patch size p’ is set as 4 by default, and other size values are evaluated in the ablation studies. As shown in Table 1, there are two variants of TNT networks with different model size, namely, TNT-S and TNT-B. They consist of 23.8M and 65.6M parameters respectively. The corresponding FLOPs for processing a 224×224 image are 5.2B and 14.1B respectively.
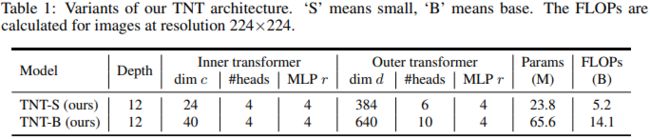
S 和 B 的区别包括通道维度、注意力 head 个数上的不同。
- Operational optimizations.
Inspired by squeeze-and-excitation (SE) network for CNNs [17], we propose to explore channel-wise attention for transformers. We first average all the patch (pixel) embeddings and use a two-layer MLP to calculate the attention values. The attention is multiplied to all the embeddings. The SE module only brings in a few extra parameters but is able to perform dimension-wise attention for feature enhancement.
本文在获得 patch 和 pixel embedding 后,对它们做了 channel attention,在维度上做注意力学习,实现特征增强。
Experiments
Implementation Details

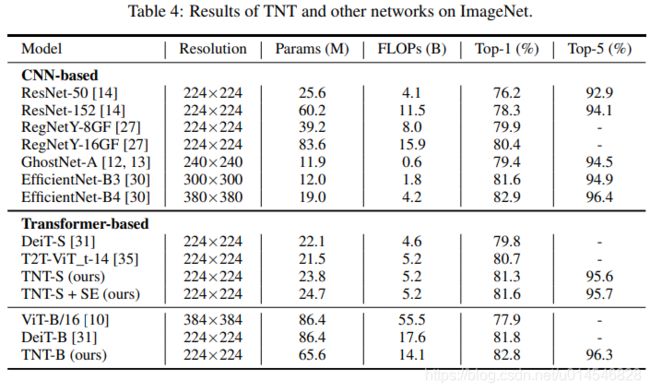
TNT on ImageNet
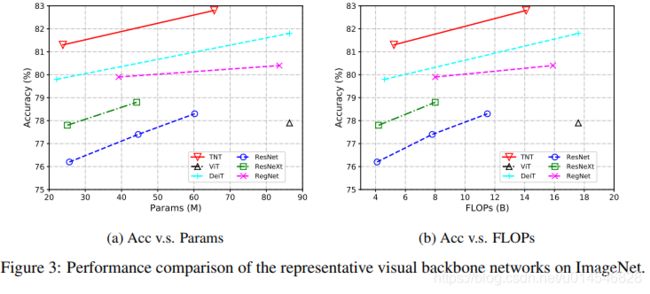
Ablation Studies
- Effect of position encodings
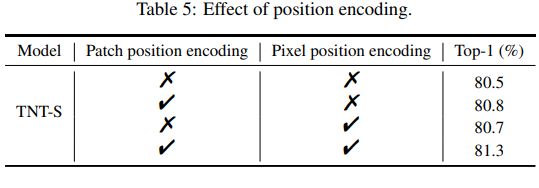
- Number of #heads

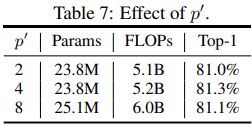
- Transformed patch size (p' , p' )
Visualization
We visualize the learned features of DeiT and TNT to further understand the effect of the proposed method. For better visualization, the input image is resized to 1024×1024. The feature maps are formed by reshaping the patch embeddings according to their spatial positions. The feature maps in the 1-st, 6-th and 12-th blocks are shown in Fig. 4(a) where 12 feature maps are randomly sampled for these blocks each. In TNT, the local information are better preserved compared to DeiT. We also visualize all the 384 feature maps in the 12-th block using t-SNE [33] (Fig. 4(b)). We can see that the features of TNT are more diverse and contain richer information than those of DeiT. These benefits owe to the introduction of inner transformer block for modeling local features.

本文将学习到的 DeiT 和 TNT 特征可视化,以进一步理解提出的方法的效果。为了更好地显示,输入图像的大小调整为10241024。根据其空间位置对斑块嵌入进行重塑,形成特征映射。第1个、第6个和第12个 block 的特征图如图 4(a) 所示,每个块随机抽取 12 个特征图。TNT 比 DeiT 更能保存本地信息。本文还使用 t-SNE 可视化了第 12 block 的所有 384 个特征图 (图4(b))。可以看到,TNT 的特征比 DeiT 更多样化,包含的信息更丰富。这些好处归功于引入内部变压器块来建模局部特征。
In addition to the patch-level features, we also visualize the pixel embeddings of TNT in Fig. 5. For each patch, we reshape the pixel embeddings according to their spatial positions to form the feature maps and then average these feature maps by the channel dimension. The averaged feature maps corresponding to the 14×14 patches are shown in Fig. 5. We can see that the local information is well preserved in the shallow layers, and the representations become more abstract gradually as the network goes deeper.

除了 patch-level 特征外,还在图 5 中可视化了 TNT 的像素嵌入。对于每个 patch,根据其空间位置重塑像素嵌入形成特征映射,然后用通道维数对这些特征映射进行平均。14x14 个斑块对应的平均特征图如图 5 所示。可以看到,局部信息在较浅的层中保存得很好,并且随着网络的深入,表示也逐渐变得抽象。