Datawhale & 天池 二手车价格预测(4.12-4.20)
Task1 赛题理解(4.12-4.14)打卡
一、赛题概况
赛题以预测二手车的交易价格为任务,数据集报名后可见并可下载,该数据来自某交易平台的二手车交易记录,总数据量超过40w,包含31列变量信息,其中15列为匿名变量。为了保证比赛的公平性,将会从中抽取15万条作为训练集,5万条作为测试集A,5万条作为测试集B,同时会对name、model、brand和regionCode等信息进行脱敏。
二、数据概况
训练集train.csv
- SaleID - 销售样本ID
- name - 汽车编码
- regDate - 汽车注册时间
- model - 车型编码
- brand - 品牌
- bodyType - 车身类型
- fuelType - 燃油类型
- gearbox - 变速箱
- power - 汽车功率
- kilometer - 汽车行驶公里
- notRepairedDamage - 汽车有尚未修复的损坏
- regionCode - 看车地区编码
- seller - 销售方
- offerType - 报价类型
- creatDate - 广告发布时间
- price - 汽车价格
- v_0’, ‘v_1’, ‘v_2’, ‘v_3’, ‘v_4’, ‘v_5’, ‘v_6’, ‘v_7’, ‘v_8’, ‘v_9’, ‘v_10’, ‘v_11’, ‘v_12’, ‘v_13’,‘v_14’ 【匿名特征,包含v0-14在内15个匿名特征】
数字全都脱敏处理,都为label encoding形式,即数字形式
三、预测指标
本赛题的评价标准为MAE(Mean Absolute Error):

其中 yi代表第 i 个样本的真实值,其中 ^yi代表第i个样本的预测值

四、环境配置
1、anaconda 新建环境
conda create -n tianchi
2、配置环境
- 切换到环境天池
conda activate tianchi
- 下载jupyter可以调整环境的包
conda install ipykernel
python -m ipykernel install --tianchi
- 下载环境包
conda install numpy
conda install pandas
同样方法下载其他包,其中xgboost需要用pip下载
pip install xgboost
建议配置一下pip的清华源
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple/
环境配置完毕之后可以导几个包简单试一试
## 基础工具
import numpy as np
import pandas as pd
import warnings
import matplotlib
import matplotlib.pyplot as plt
import seaborn as sns
from scipy.special import jn
from IPython.display import display, clear_output
import time
warnings.filterwarnings('ignore')
%matplotlib inline
## 模型预测的 from sklearn import linear_model
from sklearn import preprocessing
from sklearn.svm import SVR
from sklearn.ensemble import RandomForestRegressor,GradientBoostingRegressor
## 数据降维处理的 from sklearn.decomposition import PCA,FastICA,FactorAnalysis,SparsePCA
import lightgbm as lgb
import xgboost as xgb
## 参数搜索和评价的 from sklearn.model_selection import GridSearchCV,cross_val_score,StratifiedKFold,train_test_split
from sklearn.metrics import mean_squared_error, mean_absolute_error
#导入数据
Train_data = pd.read_csv('data/used_car_train_20200313.csv', sep=' ')
TestA_data = pd.read_csv('data/used_car_testA_20200313.csv', sep=' ')
## 输出数据的大小信息
print('Train data shape:',Train_data.shape)
print('TestA data shape:',TestA_data.shape)

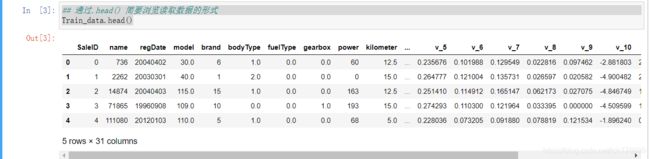
## 通过.head() 简要浏览读取数据的形式
Train_data.head()
## 通过 .info() 简要可以看到对应一些数据列名,以及NAN缺失信息
Train_data.info()

这一小节就完毕啦
五、赛题理解
| Field | Description |
|---|---|
| SaleID | 交易ID,唯一编码 |
| name | 汽车交易名称,已脱敏 |
| regDate | 汽车注册日期,例如20160101,2016年01月01日 |
| model | 车型编码,已脱敏 |
| brand | 汽车品牌,已脱敏 |
| bodyType | 车身类型:豪华轿车:0,微型车:1,厢型车:2,大巴车:3,敞篷车:4,双门汽车:5,商务车:6,搅拌车:7 |
| fuelType | 燃油类型:汽油:0,柴油:1,液化石油气:2,天然气:3,混合动力:4,其他:5,电动:6 |
| gearbox | 变速箱:手动:0,自动:1 |
| power | 发动机功率:范围 [ 0, 600 ] |
| kilometer | 汽车已行驶公里,单位万km |
| notRepairedDamage | 汽车有尚未修复的损坏:是:0,否:1 |
| regionCode | 地区编码,已脱敏 |
| seller | 销售方:个体:0,非个体:1 |
| offerType | 报价类型:提供:0,请求:1 |
| creatDate | 汽车上线时间,即开始售卖时间 |
| price | 二手车交易价格(预测目标) |
| v系列特征 | 匿名特征,包含v0-23在内24个匿名特征 |
- 此题为传统的数据挖掘问题,通过数据科学以及机器学习深度学习的办法来进行建模得到结果。
- 此题是一个典型的回归问题。
- 主要应用xgb、lgb、catboost,以及pandas、numpy、matplotlib、seabon、sklearn、keras等等数据挖掘常
用库或者框架来进行数据挖掘任务。 - 通过EDA来挖掘数据的联系和自我熟悉数据。
六、分类指标评价计算
(1)
import pandas as pd
import numpy as np
## 相对路径,代码文件与data同级
path = './data/'
Train_data = pd.read_csv(path+'used_car_train_20200313.csv', sep=' ')
Test_data = pd.read_csv(path+'used_car_testA_20200313.csv', sep=' ')
print('Train data shape:' , Train_data.shape)
print('TestA data shape:' , Test_data.shape)
Train data shape: (150000, 31)
TestA data shape: (50000, 30)
(2)
## 通过head简要浏览数据的形式
Train_data.head()

(3)
## 分类指标计算评价
## accuracy(准确性)
from sklearn import metrics
from sklearn.metrics import accuracy_score
import numpy as np
from sklearn.metrics import roc_auc_score
y_pred = [0, 1, 0, 1]
y_true = [0, 1, 1, 1]
y_true = np.array([0, 0, 1, 1])
y_scores = np.array([0.1, 0.4, 0.35, 0.8])
print('Precision',metrics.precision_score(y_true, y_pred))
print('Recall',metrics.recall_score(y_true, y_pred))
print('F1-score:',metrics.f1_score(y_true, y_pred))
print('ACC:',accuracy_score(y_true, y_pred))
print('AUC socre:',roc_auc_score(y_true, y_scores))
Precision 0.5
Recall 0.5
F1-score: 0.5
ACC: 0.5
AUC socre: 0.75