LSTM电力预测 ~期末大作业~
LSTM预测电力消耗:
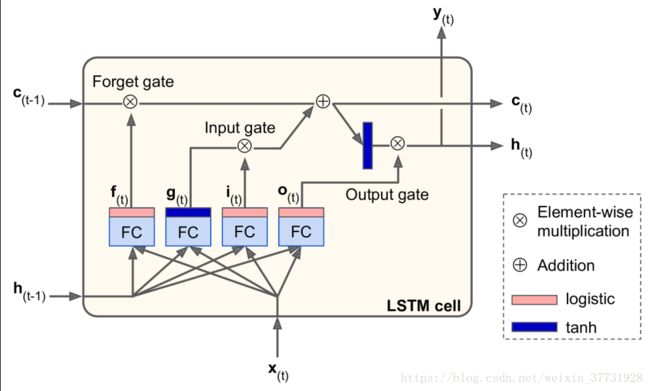
如果有不清楚LSTM的,可以看下我的这张珍藏了多年的老图,简单明了!
今天看到了深度学习课程期末大作业要求,要提交一个RNN预测电力消耗的程序,作为一个攻克生,下意识地百度了一下,发现要不就是版本太老,要不就是代码有问题。。。于是今天动手写了一个,以解大家燃眉之急!仅给刚接触的小白参考用,大神勿喷,时间仓促,写的时候没有做注释,谅解~~
作业的要求是基于20个已知的数据,预测1个未知的数据,数据CSV的格式为第一列为时间,第二列为温度,第三列为电力消耗,电力预测下需要用到时间参数,温度参数,以及历史电力消耗
用的tensorflow版本为1.8.0, python版本为3.6
转载请注明出处哦~
这里把tensorflow程序分成了3部分,第一部分为PP_inference (LSTM模型), 第二部分为PP_train(训练程序),第三部分为PP_eval(测试程序),这样把程序分成3部分可以使程序可读性大大提高~
1.PP_inference :
定义神经网络结构,这里采用2层LSTM的简单结构+1层全链接(relu)+1个输出,HIDDEN_SIZE大小为500,这里设置了dropout,在训练过程中,dropout概率设置为0.9,测试时dropout概率设置为1(需在PP_train和eval中设置)
具体代码如下:
import tensorflow as tf HIDDEN_SIZE = 500 NUM_LAYERS = 2 def lstm_model(x,dropout_keep_prob): lstm_cells = [ tf.nn.rnn_cell.DropoutWrapper( tf.nn.rnn_cell.BasicLSTMCell(HIDDEN_SIZE), output_keep_prob=dropout_keep_prob) for _ in range(NUM_LAYERS)] cell = tf.nn.rnn_cell.MultiRNNCell(lstm_cells) print("cell_created") outputs, _ = tf.nn.dynamic_rnn(cell, x, dtype=tf.float32) output = outputs[:,-1,:] predictions01 = tf.contrib.layers.fully_connected(output, 100,activation_fn= tf.nn.relu) predictions = tf.contrib.layers.fully_connected(predictions01, 1, activation_fn=None) return predictions
2.PP_train :
下为训练程序。 这里首先设置了一些参数,
比如由于用20个点预测1个点,这里timestep为20
batchsize我调了好久。。。最终感觉100的时候loss比较稳定,收敛值也可以接受
inputsize为输入值的维度,这里为3
学习率设置为0.01,decay为0.9
用了50000个样本进行训练
具体代码如下:
import numpy as np import tensorflow as tf import pandas as pd import PP_inference TIMESTEPS = 20 TRAINING_STEPS = 10000 BATCH_SIZE = 100 INPUT_SIZE = 3 LEARNING_RATE_BASE = 0.01 LEARNING_RATE_DECAY = 0.9 NUM_EXAMPLES = 50000 f=open('BSE.csv') df=pd.read_csv(f) data=df.iloc[:,0:3].values MODEL_SAVE_PATH = "model_saved/" MODEL_NAME = "model.ckpt" LSTM_KEEP_PROB = 0.9 def variable_summaries(var, name): with tf.name_scope('summaries'): tf.summary.histogram(name, var) mean = tf.reduce_mean(var) tf.summary.scalar('mean/'+name, mean) stddev = tf.sqrt(tf.reduce_mean(tf.square(var-mean))) tf.summary.scalar('stddev/'+name, stddev) def get_train_data(time_step,train_begin,train_end): # 数据预处理过程,由于为了避免改变温度的分布规律,这里仅减了均值,温度与电力做了归一化处理 # 其实应该用BN的!真的懒了,大家可以试试,无脑上BN肯定没错的。。。 data_time = data[train_begin:train_end,0] data_temp = data[train_begin:train_end,1] data_power = data[train_begin:train_end,2] mdt = np.mean(data_time,axis=0) print(mdt) mdtp = np.mean(data_temp,axis=0) print(mdtp) stddtp = np.std(data_temp,axis=0) print(stddtp) mdtpower = np.mean(data_power,axis=0) print(mdtpower) stddtpower = np.std(data_power,axis=0) print(stddtpower) normalized_data_time = data_time-mdt normalized_data_time = np.array(normalized_data_time).reshape(-1,1) print(normalized_data_time.shape) normalized_data_temp = (data_temp-mdtp)/stddtp normalized_data_temp = np.array(normalized_data_temp).reshape(-1, 1) normalized_data_power = (data_power-mdtpower)/stddtpower normalized_data_power = np.array(normalized_data_power).reshape(-1, 1) normalized_train_data=np.concatenate((normalized_data_time,normalized_data_temp,normalized_data_power),axis=1) print(normalized_train_data.shape) data_labels = data[train_begin:train_end,1:3] train_x=[] train_y=[] for i in range(len(normalized_train_data)-time_step): train_x.append([normalized_train_data[i:i + time_step, :3]]) train_y.append([data_labels[i+time_step,1]]) print("get_train_data_finished") train_x=np.array(train_x).reshape(-1,TIMESTEPS,INPUT_SIZE) train_y=np.array(train_y).squeeze() train_y=np.array(train_y).reshape(-1,1) print(np.array(train_x, dtype=np.float32).shape) print(np.array(train_y, dtype=np.float32).shape) return np.array(train_x, dtype=np.float32), np.array(train_y, dtype=np.float32) def train(train_x, train_y): global_step = tf.Variable(0, trainable=False) ds = tf.data.Dataset.from_tensor_slices((train_x,train_y)) ds = ds.repeat().shuffle(100000).batch(BATCH_SIZE) X, y = ds.make_one_shot_iterator().get_next() predictions = PP_inference.lstm_model(X,LSTM_KEEP_PROB) print(predictions) loss = tf.losses.mean_squared_error(labels=y,predictions=predictions) tf.summary.scalar('loss',loss) learning_rate = tf.train.exponential_decay( LEARNING_RATE_BASE, global_step, NUM_EXAMPLES / BATCH_SIZE, LEARNING_RATE_DECAY ) train_op = tf.train.AdamOptimizer(learning_rate).minimize(loss, global_step=global_step) print("All paras are setted") saver = tf.train.Saver() merged = tf.summary.merge_all() train_writer = tf.summary.FileWriter("log/log", tf.get_default_graph()) with tf.Session() as sess: tf.global_variables_initializer().run() for i in range(TRAINING_STEPS): if i % 100 == 0: run_options = tf.RunOptions( trace_level = tf.RunOptions.FULL_TRACE) run_metadata = tf.RunMetadata() summary, _, l, step = sess.run([merged, train_op, loss, global_step],options=run_options,run_metadata=run_metadata) train_writer.add_run_metadata(run_metadata,'step%02d' % i) train_writer.add_summary(summary, i) print("train step is %s loss is %s " % (str(step), str(l))) saver.save(sess, "model_saved/model.ckpt") print("model has been saved") else: summary, _, l, step = sess.run([merged, train_op, loss, global_step]) train_writer.add_summary(summary, i) train_writer.close() def main(argv=None): train_x, train_y = get_train_data(TIMESTEPS, 0, NUM_EXAMPLES) train(train_x, train_y) if __name__ == '__main__': tf.app.run()
3.PP_eval:
测试测试集数据!这里按照老师的要求,预测第12月份的电力值,注意,对数据做归一化处理时用的训练时求得的均值标准差
具体代码如下:
import tensorflow as tf import matplotlib.pyplot as plt import PP_inference import PP_train import pandas as pd import numpy as np TIMESTEPS = 20 INPUT_SIZE = 3 LSTM_KEEP_PROB = 1 f = open('BSE.csv') df = pd.read_csv(f) data = df.iloc[:,0:3].values def get_test_data(time_step,test_begin,test_end): data_time = data[test_begin:test_end, 0] data_temp = data[test_begin:test_end, 1] data_power = data[test_begin:test_end, 2] mdt=[12.49888] mdt = np.array(mdt,dtype=np.float32) mdtp = [50.94878] mdtp = np.array(mdtp,dtype=np.float32) stddtp = [18.223719612406246] stddtp = np.array(stddtp,dtype=np.float32) mdtpower = [14916.97936] mdtpower = np.array(mdtpower,dtype=np.float32) stddtpower = [2938.1257186400294] stddtpower = np.array(stddtpower,dtype=np.float32) normalized_data_time = data_time - mdt normalized_data_time = np.array(normalized_data_time).reshape(-1, 1) print(normalized_data_time.shape) normalized_data_temp = (data_temp - mdtp) / stddtp normalized_data_temp = np.array(normalized_data_temp).reshape(-1, 1) normalized_data_power = (data_power - mdtpower) / stddtpower normalized_data_power = np.array(normalized_data_power).reshape(-1, 1) normalized_test_data = np.concatenate((normalized_data_time, normalized_data_temp, normalized_data_power), axis=1) test_x = [] test_y = [] data_test=data[test_begin:test_end] for i in range(len(normalized_test_data)-time_step): test_x.append([normalized_test_data[i:i + time_step, :3]]) test_y.append([data_test[i + time_step, 1:3]]) print("get_test_data_finished") test_x = np.array(test_x).reshape(-1,TIMESTEPS,INPUT_SIZE) print(len(test_y)) test_y = np.array(test_y,dtype=np.float32).squeeze() return np.array(test_x,dtype=np.float32),np.array(test_y,dtype=np.float32) def run_eval(test_x, test_y): ds = tf.data.Dataset.from_tensor_slices((test_x, test_y)) ds = ds.batch(1) X,y = ds.make_one_shot_iterator().get_next() pred = PP_inference.lstm_model(X,LSTM_KEEP_PROB) predictions = [] label = [] realtemp=[] saver = tf.train.Saver(tf.global_variables()) with tf.Session() as sess: ckpt = tf.train.get_checkpoint_state( PP_train.MODEL_SAVE_PATH) if ckpt and ckpt.model_checkpoint_path: saver.restore(sess, ckpt.model_checkpoint_path) print("checkpoint finded") else: print("No checkpoint finded") for i in range(len(test_y)): predget,yy =sess.run([pred,y]) yy=np.array(yy).squeeze() print(i) print(yy) predget=np.array(predget).squeeze() predictions.append(predget) label.append(yy[1]) realtemp.append(yy[0]) predictions = np.array(predictions).squeeze() predictionstwo = np.array(label).squeeze() realtemp = np.array(realtemp).squeeze() print(predictions) plt.figure() plt.plot(predictions, label='predictions') plt.plot(predictionstwo, label='real') plt.legend() plt.show() plt.figure() plt.plot(realtemp,label='realtemp') plt.legend() plt.show() def main(argv=None): test_x, test_y = get_test_data(TIMESTEPS, 50492,51192) run_eval(test_x,test_y) if __name__ == '__main__': tf.app.run()
代码全部搞定,下面看下结果如何~
损失收敛情况:(用tensorboard看),可见在将整体数据训练到15轮后,电力预测的MSE误差收敛到1.2209e+5,不要看这个很大,其实可以拉,因为电力的都是20000+,预测出错个几百不是问题~~认为可以满足需求,为避免过拟合,这里选用训练第15轮的模型

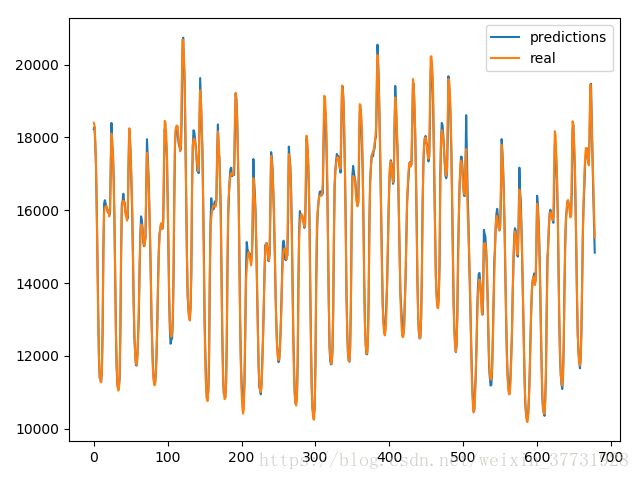
预测结果:其实本来20个已知预测一个位置就没啥实际意义,这个图就看看把
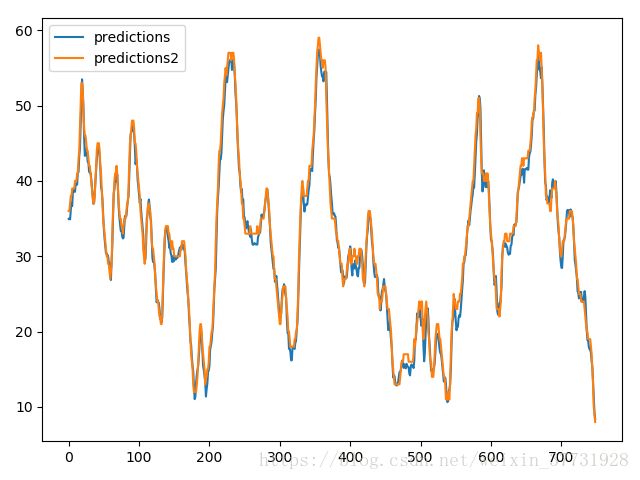
另外,由于想未来基于预测的温度,时间,预测的电力对未来的电力消耗进行预测,这里又用了同样的模型训练以下预测了温度,本来之前想一起预测温度与电力的,但是效果很不好,单独预测的话效果一般般把,如下:
这样,大作业就完成了。。。希望写的这些能给刚入门RNN的童鞋带来帮助,大家有什么不懂的或者指正的可以留言,我会一一回复的~
转载请注明出处~
github链接: 点击打开链接