Python数据挖掘入门与实践 第二章2.1 cross_val_score函数
cross_val_score函数
填写的第二个坑:cross_val_score函数,即交叉验证的原理是怎样的?
我们可以翻阅 scikit-learn官方文档
其中,下面这个图我么们可以看到,All Data可以分为n个Fold。
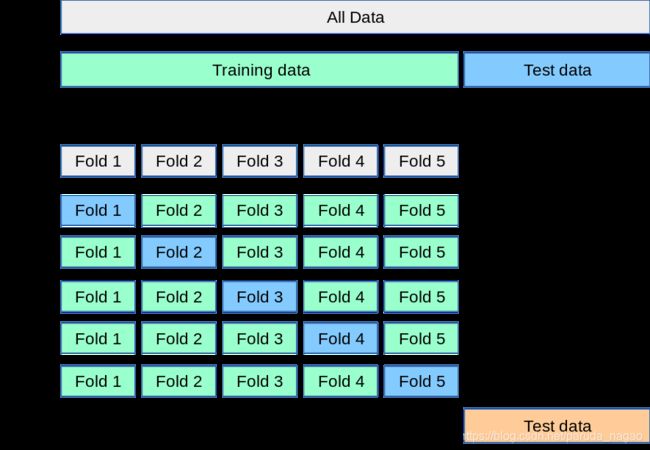
官方的图例中,n=5。
当n1用来做为test _data的时候,剩下的n2,n3,n4,n5即train_data。
当n2用来做为test _data的时候,剩下的n1,n3,n4,n5即train_data。
…省略…
当n5用来做为test _data的时候,剩下的n1,n2,n3,n4即train_data。
这样就会有5个准确度,而这5个准确度的平均值,即为最终的交叉验证准确度。
回顾之前书本的内容,代码为截取部分:
from sklearn.cross_validation import cross_val_score
scores = cross_val_score(estimator, X, y, cv=3, scoring='accuracy')
average_accuracy = np.mean(scores) * 100
print("The average accuracy is {0:.1f}%".format(average_accuracy))
print(scores,type(scores))
The average accuracy is 82.3%
[0.82051282 0.78632479 0.86324786]
接下来验证,按照官方文档的图例,来操作后,
是否会得到和cross_val_score一样的结果。
首先,需要进行矩阵的分切。
即,按照图例分切成3等分:
X1,X2,X3 = np.split(X,3,axis=0)
y1,y2,y3 = np.split(y,3,axis=0)
X1,X2,X3分别为test数组,当X1为test的时候,X2+X3为train
矩阵的纵向(vertical)合并函数为:np.vstack((A,B))
矩阵的横向(horizontal)合并函数为:np.hstack((A,B))
X1_train = np.vstack((X2,X3))
y1_train = np.hstack((y2,y3))
同理,X2,X3也可以计算得到各自的准确率。
整理到目前为止的代码:
import numpy as np
import csv
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import cross_val_score
from matplotlib import pyplot as plt
data_filename = r'下载地址\ionosphere.data'
X = np.zeros((351, 34), dtype='float')
y = np.zeros((351,), dtype='bool')
with open(data_filename, 'r') as input_file:
reader = csv.reader(input_file)
for i, row in enumerate(reader):
data = [float(datum) for datum in row[:-1]]
X[i] = data
y[i] = row[-1] == 'g'
estimator = KNeighborsClassifier(n_neighbors=5)
scores = cross_val_score(estimator, X, y, cv=3, scoring='accuracy')
average_accuracy = np.mean(scores) * 100
print("The average accuracy is {0:.1f}%".format(average_accuracy))
print(scores)
##分割成三等分:
X1,X2,X3 = np.split(X,3,axis=0)
y1,y2,y3 = np.split(y,3,axis=0)
X1_train = np.vstack((X2,X3))
y1_train = np.hstack((y2,y3))
estimator.fit(X1_train, y1_train)
y1_predicted = estimator.predict(X1)
accuracy1 = np.mean(y1 == y1_predicted)
print('X1的准确率为:',accuracy1)
X2_train = np.vstack((X1,X3))
y2_train = np.hstack((y1,y3))
estimator.fit(X2_train, y2_train)
y2_predicted = estimator.predict(X2)
accuracy2 = np.mean(y2 == y2_predicted)
print('X2的准确率为:',accuracy2)
X3_train = np.vstack((X1,X2))
y3_train = np.hstack((y1,y2))
estimator.fit(X3_train, y3_train)
y3_predicted = estimator.predict(X3)
accuracy3 = np.mean(y3 == y3_predicted)
print('X3的准确率为:',accuracy3)
accuracy = (accuracy1+accuracy2+accuracy3)/3
print('准确率平均值为:',accuracy)
运行的结果是:
The average accuracy is 82.3%
[0.82051282 0.78632479 0.86324786]
X1的准确率为: 0.7264957264957265
X2的准确率为: 0.7692307692307693
X3的准确率为: 0.9401709401709402
准确率平均值为: 0.8119658119658121
结果对不上啊。。。。
(沉默,思考。。。)
仔(粗)细(略)翻看官方文档:
只提到了:
When the cv argument is an integer, cross_val_score uses the KFold or
StratifiedKFold strategies by default,
然后再翻翻书,提到了:
cross_val_score默认使用Stratified K Fold方法切分数据集,
它大体上保证切分后得到的子数据集中类别分布相同,
以避免某些子数据集出现类别分布失 衡的情况。
这个默认做法很不错,现阶段就不再把它搞复杂了。
果然看书很重要!要吃透一本书,一定要多看多练反复读。。。
(也是写博客的原因,逼着自己慢下节奏思考问题)
也就是可以理解为:Stratified K Fold方法,可以把y的True or False的比例,
在3个小的fold里面,都保持差不多的百分比!
书里不搞复杂,我来尝试搞复杂一下:
StratifiedKFold 官方文档
按照官方的例子,依样画葫芦:
from sklearn.model_selection import StratifiedKFold
拆分为3个fold,且之前无论运行几次都是一样的结果,所以猜测是不洗牌的。
skf = StratifiedKFold(n_splits=3,random_state=None,shuffle=False)
拆分的方法为:split(X, y[, groups]) Generate indices to split data into training and test set.
因此可以按照下面的方法拆分:
for skf_fold in skf.split(X, y):print(skf_fold)
from sklearn.model_selection import StratifiedKFold
skf = StratifiedKFold(n_splits=3,random_state=None,shuffle=False)
for skf_fold in skf.split(X, y):print(skf_fold)
整理一下目前的代码,并且运行下看看的话,可以得到如下结果:
截取部分是第一个fold对应的train_data,刚好234个数据,
(array([ 85, 87, 89, 91, 93, 95, 98, 100, 102, 104, 106, 108, 110,
112, 114, 116, 118, 120, 122, 124, 126, 128, 130, 132, 134, 136,
138, 140, 142, 144, 146, 148, 149, 150, 151, 152, 153, 154, 155,
156, 157, 158, 159, 160, 161, 162, 163, 164, 165, 166, 167, 168,
169, 170, 171, 172, 173, 174, 175, 176, 177, 178, 179, 180, 181,
182, 183, 184, 185, 186, 187, 188, 189, 190, 191, 192, 193, 194,
195, 196, 197, 198, 199, 200, 201, 202, 203, 204, 205, 206, 207,
208, 209, 210, 211, 212, 213, 214, 215, 216, 217, 218, 219, 220,
221, 222, 223, 224, 225, 226, 227, 228, 229, 230, 231, 232, 233,
234, 235, 236, 237, 238, 239, 240, 241, 242, 243, 244, 245, 246,
247, 248, 249, 250, 251, 252, 253, 254, 255, 256, 257, 258, 259,
260, 261, 262, 263, 264, 265, 266, 267, 268, 269, 270, 271, 272,
273, 274, 275, 276, 277, 278, 279, 280, 281, 282, 283, 284, 285,
286, 287, 288, 289, 290, 291, 292, 293, 294, 295, 296, 297, 298,
299, 300, 301, 302, 303, 304, 305, 306, 307, 308, 309, 310, 311,
312, 313, 314, 315, 316, 317, 318, 319, 320, 321, 322, 323, 324,
325, 326, 327, 328, 329, 330, 331, 332, 333, 334, 335, 336, 337,
338, 339, 340, 341, 342, 343, 344, 345, 346, 347, 348, 349, 350]),
85, 87, 89, 91, 93, 95, 98, 100, 102, 104, 106, 108, 110,112, 114, 116,
这几个数据,正好是之前三等分的时候,分到第一组数据的test里面的!!
有兴趣的可以自己看看,其他2组序号分别是多少。
似乎快要破案了??继续写下去!
for train_index, test_index in skf.split(X, y):
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
这样就能得到,每一个fold的train和test数据了。
然后进行训练并且计算正确值,然后整理代码:
skf = StratifiedKFold(n_splits=3,random_state=None,shuffle=False)
## for skf_fold in skf.split(X, y): print(skf_fold) 这里可以不打印了。
for train_index, test_index in skf.split(X, y):
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
estimator = KNeighborsClassifier()
estimator.fit(X_train, y_train)
y_predicted = estimator.predict(X_test)
accuracy = np.mean(y_test == y_predicted)
print(print(accuracy))
运行后的结果为:
The average accuracy is 82.3%
[0.82051282 0.78632479 0.86324786]
0.8205128205128205
0.7863247863247863
0.8632478632478633
啊!!!一摸一样!
看来, cross_val_score函数直接整合了StratifiedKFold的默认函数~
最后,把所有代码都汇总一下:
import numpy as np
import csv
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import cross_val_score
from matplotlib import pyplot as plt
from sklearn.model_selection import StratifiedKFold
data_filename = r'C:\JIN SIYUN\A_python\Python数据挖掘入门与实践\PythonDataMining-master\data\ionosphere.data'
X = np.zeros((351, 34), dtype='float')
y = np.zeros((351,), dtype='bool')
with open(data_filename, 'r') as input_file:
reader = csv.reader(input_file)
for i, row in enumerate(reader):
data = [float(datum) for datum in row[:-1]]
X[i] = data
y[i] = row[-1] == 'g'
## 交叉检验
estimator = KNeighborsClassifier(n_neighbors=5)
scores = cross_val_score(estimator, X, y, cv=3, scoring='accuracy')
average_accuracy = np.mean(scores) * 100
print("The average accuracy is {0:.1f}%".format(average_accuracy))
print(scores)
skf = StratifiedKFold(n_splits=3,random_state=None,shuffle=False)
## for skf_fold in skf.split(X, y): print(skf_fold)
for train_index, test_index in skf.split(X, y):
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
estimator = KNeighborsClassifier()
estimator.fit(X_train, y_train)
y_predicted = estimator.predict(X_test)
accuracy = np.mean(y_test == y_predicted)
print(accuracy)
参考文献:
1.https://scikit-learn.org/stable/modules/cross_validation.html#multimetric-cross-validation
2.https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.StratifiedKFold.html