利用随机森林预测股票大盘涨跌
本文仅从实战角度去观察,利用机器学习算法中,随机森林模型预测股票市场指数涨跌的准确率。
适合入门玩家
首先,我们导入所需要的模块
import numpy as np
import pandas as pd
import talib as ta #金融数据计算
import datetime,pickle
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import mean_absolute_error,mean_squared_error,r2_score,accuracy_score,roc_auc_score
from sklearn.ensemble import RandomForestClassifier #随机森林分类模型然后读取指数数据,这里所使用的数据为个人付费购买数据,本文所使用的数据可以从文末联系方式获取。
关于数据,如果仅做ML、DL学习使用,可以选择量化平台获取、tushare接口获取、爬虫获取等方式,但如果是做模拟交易或者实盘交易,请尽量购买券商提供的数据,否则在数据清洗方面,哪怕是团队也需要耗费大量的人力物力。
with open(r'D:\history_data_22\indexs.pkl','rb') as f:
index_data = pickle.load(f)然后将index_data 打印出来,我们可以得到这样的数据:
code – 指数代码(string)
date – 日期(int)
open – 开盘价(float)
close – 收盘价(float)
low – 最低价(float)
high – 最高价(float)
vol - 成交量(float)
money – 成交额(float)
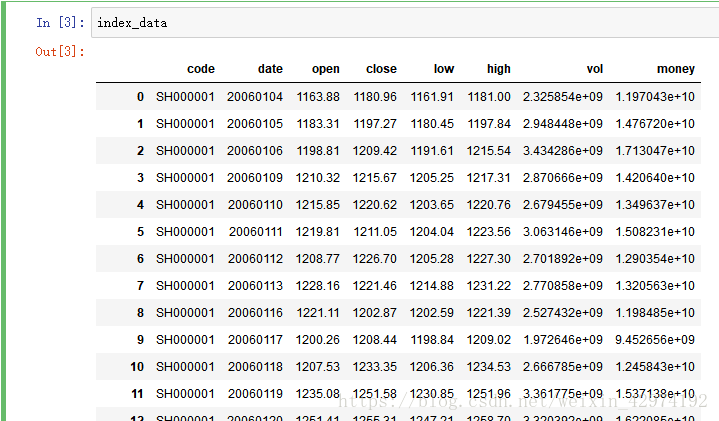
因为指数包括了很多,如上证50、沪深300、中证500等等,这里我们仅用上证指数为例
所以选择code代码为SH000001的数据
df = index_data[index_data['code'] == "SH000001"]现在我们添加一些简单的技术指标
np_close = np.array(df['close'])
diff, dea, macd = ta.MACD(np_close, fastperiod=12, slowperiod=26,signalperiod=9)
df['MA5'] = ta.MA(np_close,timeperiod=5)
df['MA10'] = ta.MA(np_close,timeperiod=10)
df['DIFF'] = diff
df['DEA'] = dea
df['MACD'] = macd此时,我们的dataframe应该是这样的
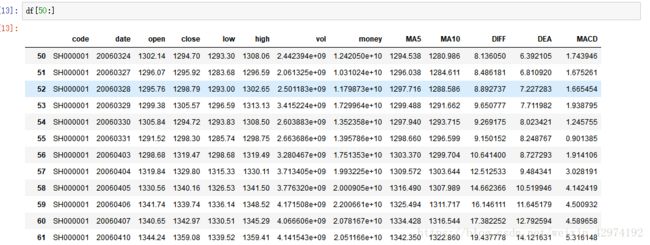
那么,特征值(feature)为Open到MACD。
我们想要机器通过feature预测出明日大盘的涨跌情况,那么这时需要来定义一下label,即告诉机器你想要预测什么。
我们在本文中采用二分类作为测试,涨为1,跌为0。
def num_config(x):
if x > 0 :
return 1
else:
return 0df["(t+1)-(t)"] = df['close'].shift(-1) - df['close']
df['label'] = df["(t+1)-(t)"].map(num_config) 再次打印df,我们应该得到如下的数据
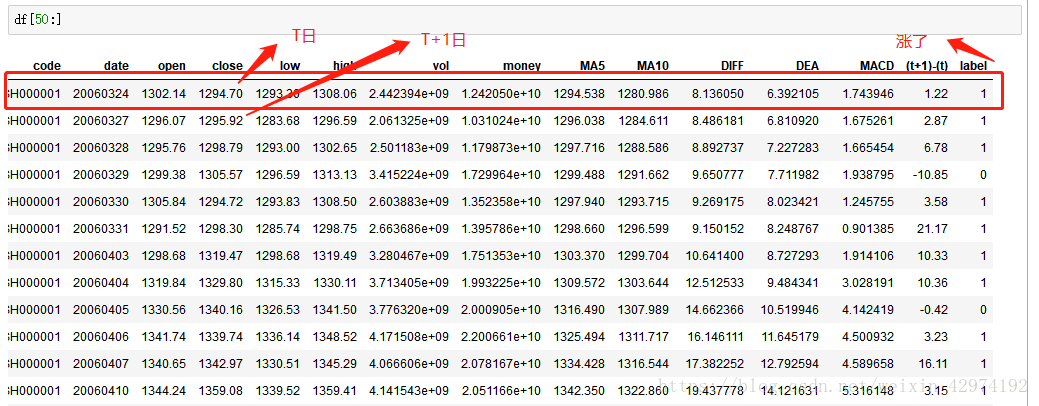
这时,特征值和标签,我们都应该搞定了。
现在,我们来划分一下训练集和测试集,因为此文仅做测试使用,大家可以根据个人兴趣,添加验证集,用网格搜索、交叉验证,寻找最优参数,然后再作用于测试集。
因为股票数据是一个典型的时间序列数据(后面会写一篇LSTM运用),所以尽量不要用随机切分。因为随机切分很可能导致你的训练集里面含有未来函数,即X里存在Y,进而导致准确率极其的高。
我们将2017年以前的数据用来做训练,用2017年以后的数据用来做测试。
df = df.dropna() #剔除缺失值
df['time'] = pd.to_datetime(df['date'],format='%Y%m%d')
train_data = df[df['time']<"2017-01-01"]
test_data = df[df['time']>="2017-01-01"]
train_X = train_data.ix[:,'open':"MACD"].values
train_y = train_data['label'].values
test_X = test_data.ix[:,'open':"MACD"].values
test_y = test_data['label'].values所有数据均已准备完毕,下面开始调用sklearn中随机森林模型进行测试
clf = RandomForestClassifier(max_depth=3,n_estimators=20)
clf.fit(train_X,train_y)
print(accuracy_score(train_y,clf.predict(train_X)))
print(accuracy_score(test_y,clf.predict(test_X)))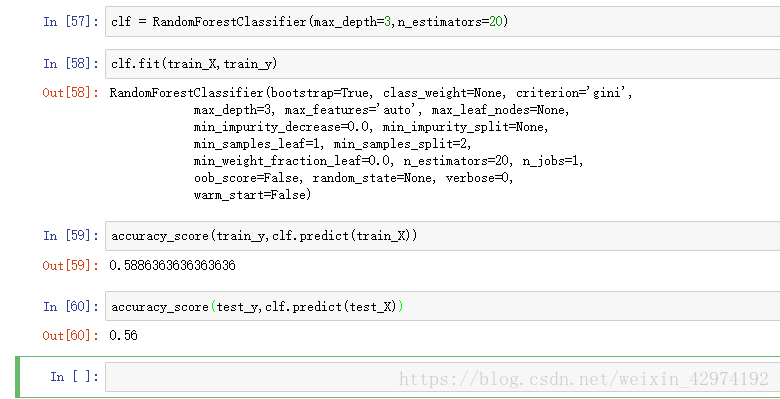
此时我们看到,该模型在训练集上有58.86%的胜率,在测试集上也拥有56%的胜率。
毫无疑问,这当然是值得庆幸的事情,56%的胜率已经要比50%高出很多,如果按盈亏均为1:1的情况下,长此以往的跑下去,是很恐怖的事情,这简直比赌场里某些游戏的胜率还要高。
但在股票市场里,真的是这样吗?
我们思考一下真实情况,该模型仅是猜涨跌,简单的二分类问题。那假设该模型只是猜跌比较厉害,而猜涨很瓜皮呢?
我们查看一下召回率

发现概率是51%,该模型并没有过多的偏袒涨跌其中的一方。
那么这个模型就可以用了吗?不是的,我们在以前的主观交易到后来的量化交易,发现很多趋势追踪策略的胜率可能只有35%-40%,但仍然可以取得不俗的盈利,原因是趋势追踪策略在盘整或者下跌阶段,有不停的试错,而上涨阶段则是一直处于持仓状态,没有频繁的换仓。于是胜率虽然低,但一口波段也能吃个胖子。
反观我们的56%模型,会不会存在虽然胜率高,但是每次赚的少,而亏一次就亏个大的这样的状况存在呢。
毕竟大A股,暴跌总比暴涨的次数多,对吧。
这里仅抛砖引玉
1、我们是否可以通过回归方法来解决上述问题
2、我们是否可以通过多分类问题来解决上述问题
总结:机器学习对于预测股票市场是存在一定作用的,但该文所涉及的模型仅对第二天的涨跌情况起辅助效果,并不能作为决策的依据!
文中所涉及代码及其付费数据集可以通过下面联系方式索取
注:该文属个人原创,转载请联系
Email:[email protected]
VX:gq454001240