sklearn笔记9 KNN参数cross_val_score调参
完整代码 sklearn代码5 5-KNN参数的筛选
模型包含:
算法
参数
import numpy as np
from sklearn.neighbors import KNeighborsClassifier
from sklearn import datasets
# model_selection:模型选择
# cross_val_score:交叉 validation:验证
# 交叉验证
from sklearn.model_selection import cross_val_score

什么是交叉验证
保留其中一个作为验证数据 其余 作为测试数据,测试完后,取其平均值,是结果更具说服力
凡见到val就可知其中有用于验证的部分

X,y = datasets.load_iris(True)
X.shape
150**0.5 # 样本数量的开平方
# K值选择时从1到13 大概是其开平方的数值,只是用于参考

cross_val_score() 函数的参数选择
Signature: cross_val_score(estimator(算法), X, y=None, groups=None,
scoring(评分标准)=None, cv=None, n_jobs=1, verbose=0, fit_params=None,
pre_dispatch=‘2*n_jobs’) Docstring: Evaluate a score by
cross-validation

查看评估的标准有哪些
可以到官网上去查看相应的信息
SCikit-learn中文社区
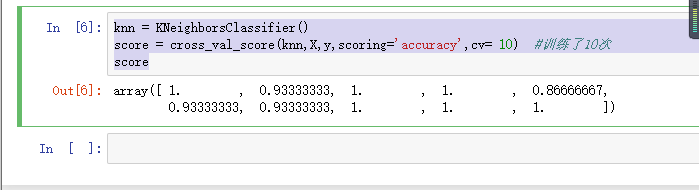
knn = KNeighborsClassifier()
score = cross_val_score(knn,X,y,scoring='accuracy',cv= 10) #训练了10次
score
knn = KNeighborsClassifier()
score = cross_val_score(knn,X,y,scoring='accuracy',cv= 10) #训练了10次
score.mean()

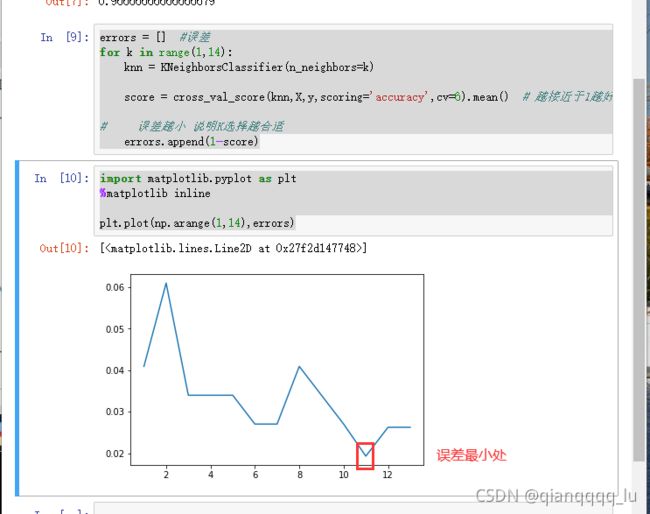
errors = [] #误差
for k in range(1,14):
knn = KNeighborsClassifier(n_neighbors=k)
score = cross_val_score(knn,X,y,scoring='accuracy',cv=6).mean() # 越接近于1越好
# 误差越小 说明K选择越合适
errors.append(1-score)
import matplotlib.pyplot as plt
%matplotlib inline
plt.plot(np.arange(1,14),errors)
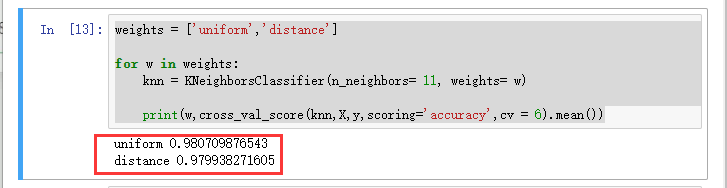
weights = ['uniform','distance']
for w in weights:
knn = KNeighborsClassifier(n_neighbors= 11, weights= w)
print(w,cross_val_score(knn,X,y,scoring='accuracy',cv = 6).mean())
模型如何去筛选最合适参数
result = {}
for k in range(1,14):
for w in weights:
knn = KNeighborsClassifier(n_neighbors=k,weights=w)
sm = cross_val_score(knn,X,y,scoring='accuracy',cv=6).mean()
result[w+str(k)] =sm
result

取出最大值
np.array(list(result.values())).argmax()
list(result)[20]
