XML解析(一) DOM解析
XML解析技术主要有三种:
(1)DOM(Document Object Model)文档对象模型:是 W3C 组织推荐的解析XML 的一种方式,即官方的XML解析技术。
(2)SAX(Simple Api for XML)产生自 XML 社区,几乎所有的 XML 解析器都支持它。
(3)StAX(Stream Api for XML)一种拉模式处理XML文档的API。
DOM解析技术:
DOM解析XML的做法是将整个XML 加载内存中,形成以树形结构存储的文档对象,所有对XML的操作都对内存中文档对象进行。
DOM解析的特点是要将整个XML文档加载到内存中,若文档比较大,则会占用很大的内存空间,但是由于整个文档都在内存中,可以方便地进行修改回写操作。
SAX解析技术:
当XML 文档非常大时,将整个文档加载到内存中进行解析,可能会造成内存溢出,而且很多时候只是对文档中的部分节点进行操作,加载整个文档会导致工作效率的低下。SAX的思想是一边解析XML,然后对解析的部分进行相关处理,然后释放已处理完成的部分所占用的内存资源。SAX是一种推模式XML解析方式,由服务端主导,向客户端推送数据。
StAX解析技术:
基本同SAX,不同之处在于,StAX是一种拉模式的XML解析技术,由客户端主导,从服务端拉取要解析的数据。Android系统中内置使用该种方式解析XML。
SAX与StAX的相同之处在于:相比DOM是一种更为轻量级的方案,采用串行方法读取 --- 文件输入流(字节、字符)读取,但是会导致编程较为复杂,且无法在读取过程中修改XML数据。
常见的XML解析开发包:
JAXP 是sun官方推出实现技术,同时支持DOM、 SAX、 StAX。
DOM4j 是开源社区开源框架,支持DOM解析方式。
XML PULL是 Android 移动设备内置xml 解析技术,支持StAX解析方式。
XML的DOM解析方式:
直接使用JDK自带的JAXP进行xml解析,所用到的相关类都存放在以下几个包中:
javax.xml.parsers 存放 DOM 和 SAX 解析器
javax.xml.stream 存放 STAX 解析相关类
org.w3c.dom 存放DOM解析时的数据节点类
org.xml.sax 存放SAX解析相关工具类
(一)加载解析XML文档:
要解析一个XML文档,首先需要加载该文档:
javax.xml.parsers中的DocumentBuilderFactory工厂类可以获取生成 DOM 对象树的解析器。
获得该类实例的方法是,调用该类的newInstance()方法。之后通过调用工厂类对象的newDocumentBuilder()方法便可以获取了DocumentBuilder这个DOM的XML解析器。
调用DocumentBuilder的parse()方法,便可以将XML文件解析为Document对象。
如:新建一个DomXmlParser类,添加一个loadFromFile方法:

1 public class DomXmlParser {
2
3 public static Document loadFromFile(String filename) throws Exception{
4
5 DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
6
7 DocumentBuilder builder = factory.newDocumentBuilder();
8
9 Document document = builder.parse(filename);
10
11 return document;
12
13 }
14
15 }
注意,Document导包时,一定要是org.w3c.dom。
Document 接口表示整个 HTML 或 XML 文档。从概念上讲,它是文档树的根,并提供对文档数据的基本访问。
常用方法:
NodeList getElementsByTagName(String tagname):按文档顺序返回包含在文档中且具有给定标记名称的所有Element的NodeList。
Element getElementById(String elementId):返回具有带给定值的 ID 属性的 Element。注意,该方法只有在XML文档具有约束时才可以使用,所以一般没有带有约束的不会用到该方法。
NodeList 接口提供对节点的有序集合的抽象,没有定义或约束如何实现此集合。DOM 中的 NodeList 对象是活动的,删除某个元素时,会导致后续元素向前移动,即下标减一。NodeList 中的项可以通过从 0 开始的整数索引进行访问。
常用方法:
int getLength():列表中的节点数。
Node item(int index):返回集合中的第 index 个元素。
Node 接口是整个文档对象模型的主要数据类型。它表示该文档树中的单个节点。
几个主要的子接口:
Document:上面已然提到
Element:表示 HTML 或 XML 文档中的一个元素。
Attr :表示 Element 对象中的属性。
Text :并且表示 Element 或 Attr 的文本内容(在 XML 中称为字符数据)。
Comment:表示注释的内容
如有下面xml文档:
1 <?xml version="1.0" encoding="UTF-8"?> 2 3 <students> 4 5 <student id="001"> 6 7 <name>zhangsan</name> 8 9 <gender>male</gender> 10 11 <age>23</age> 12 13 </student> 14 15 <student id="002"> 16 17 <name>lisi</name> 18 19 <gender>male</gender> 20 21 <age>24</age> 22 23 </student> 24 25 <student id="003"> 26 27 <name>xiaoqiao</name> 28 29 <gender>female</gender> 30 31 <age>18</age> 32 33 </student> 34 35 <student id="004"> 36 37 <name>diaochan</name> 38 39 <gender>female</gender> 40 41 <age>23</age> 42 43 </student> 44 45 </students>
各个节点的类型就是Element,节点的属性id就是Attr,节点中的值如femal、lisi等就是Text。
Node接口中提供了获取Node各种属性的方法,以及通过相对位置获取其他Node的方法,具体可以查看API帮助手册。
常用的有这么几个:
NodeList getChildNodes():包含此节点的所有子节点的 NodeList。
Node getFirstChild():此节点的第一个子节点。
Node getLastChild():此节点的最后一个节点。
Node getNextSibling():直接在此节点之后的节点。
Node getParentNode():此节点的父节点。
Node getPreviousSibling():直接在此节点之前的节点。
String getTextContent():此属性返回此节点及其后代的文本内容。
如,要输出所有学生的姓名:
DomXmlParser类:
1 public class DomXmlParser {
2
3 protected static Document document = null;
4
5 public static Document loadFromFile(String filename) throws Exception{
6
7 DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
8
9 DocumentBuilder builder = factory.newDocumentBuilder();
10
11 document = builder.parse(filename);
12
13 return document;
14
15 }
16
17 }
StudentParser类:
1 public class StudentParser extends DomXmlParser {
2
3 public static String[] getAllNames(){
4
5 NodeList students = document.getElementsByTagName("student");
6
7 String[] names = new String[students.getLength()];
8
9 for (int i = 0; i < students.getLength(); i++) {
10
11 Element stu = (Element) students.item(i);
12
13 names[i] = stu.getChildNodes().item(1).getTextContent();
14
15 }
16
17 return names;
18
19 }
20
21 }
getChildNodes()方法用于获取所有的子元素,返回一个NodeList对象。
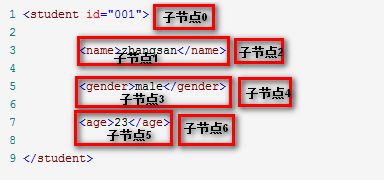
如果对当前xml文档中的每一个student节点调用该方法获取子元素,会发现返回的NodeList中元素数目为7。
1 <student id="001"> 2 3 <name>zhangsan</name> 4 5 <gender>male</gender> 6 7 <age>23</age> 8 9 </student>
这是因为:每个回车换行被当做Text节点。一个student节点有4个回车换行节点以及<name>、<gender>、<age>这3个Element节点,所以总共有7个节点。
而对于<name>节点来说,则只有一个子节点,该节点是Text节点。
(二)修改回写:
当完成了对XML的相关处理工作后,可以将修改写回到xml文档中,与加载解析相似,回写也需要相应的工厂类,相应的转换类。
1 //获取Transformer工厂类实例
2
3 TransformerFactory transformerFactory = TransformerFactory.newInstance();
4
5 //通过工厂类获取Transformer实例
6
7 Transformer transformer = transformerFactory.newTransformer();
8
9 //选择要回写的内存中的document对象
10
11 DOMSource domSource = new DOMSource(document);
12
13 //要回写的目标文件
14
15 StreamResult result = new StreamResult(new File("students_bak.xml"));
16
17 //将内存DOM对象回写到文件中
18
19 transformer.transform(domSource, result);
例如:
在DomXmlParser类中添加方法:
1 public static boolean saveAs(String filename) throws Exception{
2
3 TransformerFactory factory = TransformerFactory.newInstance();
4
5 transformer = factory.newTransformer();
6
7 DOMSource source = new DOMSource(document);
8
9 StreamResult target = new StreamResult(new File(filename));
10
11 transformer.transform(source, target);
12
13 return true;
14
15 }
调用:
1 public static void main(String[] args) {
2
3 // TODO Auto-generated method stub
4
5 try {
6
7 StudentParser.loadFromFile("students.xml");
8
9 String[] names = StudentParser.getAllNames();
10
11 for (int i = 0; i < names.length; i++) {
12
13 System.out.println(names[i]);
14
15 }
16
17 StudentParser.saveAs("students_bak.xml");
18
19 } catch (Exception e) {
20
21 // TODO Auto-generated catch block
22
23 e.printStackTrace();
24
25 }
26
27 }
使用DOM解析XML实现完整的增删改查操作示例:
首先需要一个Student类:
1 package cn.csc.bean;
2
3 public class Student {
4
5 private String id = null;
6
7 private String name = null;
8
9 private String gender = null;
10
11 private int age = 0;
12
13 public String getId() {
14
15 return id;
16
17 }
18
19 public void setId(String id) {
20
21 this.id = id;
22
23 }
24
25 public String getName() {
26
27 return name;
28
29 }
30
31 public void setName(String name) {
32
33 this.name = name;
34
35 }
36
37 public String getGender() {
38
39 return gender;
40
41 }
42
43 public void setGender(String gender) {
44
45 this.gender = gender;
46
47 }
48
49 public int getAge() {
50
51 return age;
52
53 }
54
55 public void setAge(int age) {
56
57 this.age = age;
58
59 }
60
61 public Student(String id, String name, String gender, int age) {
62
63 super();
64
65 this.id = id;
66
67 this.name = name;
68
69 this.gender = gender;
70
71 this.age = age;
72
73 }
74
75 public Student() {
76
77 super();
78
79 }
80
81 public String toString() {
82
83 return "[id:"+id+",name:"+name+",gender:"+gender+",age"+age+"]";
84
85 }
86 }
1)通过id获取学生信息:
在StudentParser类中添加getStudentById(String id)方法:
1 public static Student getStudentById(String id){
2
3 Student student = null;
4
5 NodeList students = document.getElementsByTagName("student");
6
7 for(int i=0; i<students.getLength(); i++){
8
9 Element stu = (Element) students.item(i);
10
11 if(stu.getAttribute("id").equals(id)){
12
13 student = new Student();
14
15 student.setName(((Element)stu.getElementsByTagName("name").item(0)).getTextContent());
16
17 student.setGender(((Element)stu.getElementsByTagName("gender").item(0)).getTextContent());
18
19 String age = ((Element)stu.getElementsByTagName("age").item(0)).getTextContent();
20
21 student.setAge(Integer.parseInt(age));
22
23 student.setId(id);
24
25 return student;
26
27 }
28
29 }
30
31 return student;
32
33 }
调用该方法:
1 StudentParser.loadFromFile("students.xml");
2
3 System.out.println(StudentParser.getStudentById("001"));
输出结果:
[id:001,name:zhangsan,gender:male,age23]
2)通过性别查找学生:
在StudentParser类中添加getStudentsByGender(String gender)方法:
1 public static List<Student> getStudentsByGender(String gender){
2
3 List<Student> stus = new ArrayList<Student>();
4
5 Student tmp = null;
6
7 NodeList students = document.getElementsByTagName("student");
8
9 for(int i=0; i<students.getLength(); i++){
10
11 Element stu = (Element) students.item(i);
12
13 Element gen = (Element)stu.getElementsByTagName("gender").item(0);
14
15 if(gen.getTextContent().equals(gender)){
16
17 tmp = new Student();
18
19 tmp.setGender(gender);
20
21 Element name = (Element) gen.getPreviousSibling().getPreviousSibling();
22
23 tmp.setName(name.getTextContent());
24
25 Element age = (Element) gen.getNextSibling().getNextSibling();
26
27 tmp.setAge(Integer.parseInt(age.getTextContent()));
28
29 tmp.setId(stu.getAttribute("id"));
30
31 stus.add(tmp);
32
33 }
34
35 }
36
37 return stus;
38
39 }
注意:回车换行作为Text节点的问题是上面连着调用两次getNextSibling()和getPreviousSibling()的原因所在。
调用:
1 StudentParser.loadFromFile("students.xml");
2
3 List<Student> students = StudentParser.getStudentsByGender("female");
4
5 for (int i = 0; i < students.size(); i++) {
6
7 System.out.println(students.get(i));
8
9 }
输出结果:
[id:003,name:xiaoqiao,gender:female,age18]
[id:004,name:diaochan,gender:female,age23]
3)添加一条学生信息:
1 public static boolean insert(Student stu){
2
3 Element root = (Element) document.getElementsByTagName("students").item(0);
4
5 Element student = document.createElement("student");
6
7 student.setAttribute("id", stu.getId());
8
9 Element name = document.createElement("name");
10
11 name.setTextContent(stu.getName());
12
13 Element gender = document.createElement("gender");
14
15 gender.setTextContent(stu.getGender());
16
17 Element age = document.createElement("age");
18
19 age.setTextContent(stu.getAge()+"");
20
21 student.appendChild(name);
22
23 student.appendChild(gender);
24
25 student.appendChild(age);
26
27 root.appendChild(student);
28
29 try {
30
31 saveAs("students.xml");
32
33 } catch (Exception e) {
34
35 // TODO Auto-generated catch block
36
37 e.printStackTrace();
38
39 return false;
40
41 }
42
43 return true;
44
45 }
添加之后,一定要记得回写。
调用:
1 StudentParser.loadFromFile("students.xml");
2
3 StudentParser.insert(new Student("005","dqrcsc","male",25));
4)根据id修改学生信息:
1 public static boolean update(String id, Student stu){
2
3 NodeList stus = document.getElementsByTagName("student");
4
5 for(int i=0; i<stus.getLength(); i++){
6
7 Element tmp = (Element) stus.item(i);
8
9 if(tmp.getAttribute("id").equals(id)){
10
11 tmp.setAttribute("id", stu.getId());
12
13 tmp.getChildNodes().item(1).setTextContent(stu.getName());
14
15 tmp.getChildNodes().item(3).setTextContent(stu.getGender());
16
17 tmp.getChildNodes().item(5).setTextContent(stu.getAge()+"");
18
19 try {
20
21 saveAs("students.xml");
22
23 } catch (Exception e) {
24
25 // TODO Auto-generated catch block
26
27 e.printStackTrace();
28
29 return false;
30
31 }
32
33 return true;
34
35 }
36
37 }
38
39
40
41 return false;
42
43 }
调用:
1 StudentParser.update("001", new Student("000","zhangsan22","female",26));
5)根据年龄删除学生信息:
1 public static int deleteStudentsOlderThan(int age){
2
3 int cnt = 0;
4
5 NodeList stus = document.getElementsByTagName("student");
6
7 Element root = document.getDocumentElement();
8
9 for(int i = stus.getLength()-1; i>=0; i--){
10
11 Element tmp = (Element) stus.item(i);
12
13 String str = tmp.getChildNodes().item(5).getTextContent();
14
15 int a = Integer.parseInt(str);
16
17 if(a>=age){
18
19 root.removeChild(tmp);
20
21 cnt++;
22
23 }
24
25 }
26
27 try {
28
29 saveAs("students_bak.xml");
30
31 } catch (Exception e) {
32
33 // TODO Auto-generated catch block
34
35 e.printStackTrace();
36
37 }
38
39 return cnt;
40
41 }
调用:
1 System.out.println(StudentParser.deleteStudentsOlderThan(22));