后门防御阅读笔记,Neural Cleanse Identifying and Mitigating Backdoor Attacks in Neural Networks
论文标题:Neural Cleanse Identifying and Mitigating Backdoor Attacks in Neural Networks
论文单位:UC Santa Barbara,University of Chicago
论文作者:Bolun Wang, Yuanshun Yao,Shawn Shan
收录会议:2019 IEEE Symposium on Security and Privacy (S&P)
开源代码:https://github.com/bolunwang/backdoor
神经网络中识别和缓解后门攻击的神经清洗(防御)
简单总结
第一个适用于DNN后门攻击的鲁棒和普遍的检测和缓解系统。(防御)
-
先前的防御没有提出检测是否为带后门的模型的方法,这篇论文是第一篇提出对模型进行检测识别,并且提出了缓解后门的3种办法。
-
场景:防御者可以访问训练后的DNN,以及有一组正确标记的样本
-
针对防御的攻击方法:BadNets、Trojaning attack
-
特点:首先,通过模型逆向推断触发器位置、形状,然后判断是否存在后门;其次,利用逆向触发器和实际触发器对神经元激活的相似影响,去进行缓解后门攻击。
-
提出了两个重要方法:1.检测后门 2.缓解后门
- 检测后门:针对该模型的每个标签,使用大量该标签的干净样本,通过梯度下降优化提出的目标函数(目标函数需保证攻击成功,且修改量要小)生成对应的逆向触发器,然后通过离群点异常值检测,即对所有标签生成对应的触发器的修改量大小检测是否存在异常值,检测出是否存在后门(如果有某一类的逆向触发器的修改量远远少于其他类的逆向触发器说明存在后门),存在即可获得对应的攻击目标标签和该标签对应的逆向触发器。
- 缓解后门:上述获得的逆向触发器和攻击者使用的触发器对模型的神经元激活效果相似,基于此原理,提出了输入过滤、神经元剪枝和unlearning三种方法去缓解后门,输入过滤是观察神经元对对抗性输入的激活与正常样本的激活比较,从而过滤掉带后门的输入;神经元剪枝是对对抗性输入的激活与正常样本的激活差异较大的神经元的输出置0;unlearning则是使用带逆向触发器的样本对模型进行重新训练,使其预测为正确标签。
-
在论文的最后,也是总结了后门攻击的更先进的变体,该论文的方法可以解决其中的一部分,另一部分就是将来可以开展的工作了。
值得做的点(仅从本文出发)
-
19年的四大的文章,可以改进的点在20、21年的文章也有体现,还是得先多看看新的文章再做总结。
-
比如论文最后总结的一类后门攻击先进的变体:源标签专用(部分)后门。在论文《Input-aware dynamic backdoor attack》中实现了这一类攻击,并且生成的触发器不仅仅针对源标签,而是针对每一张不同的图片生成不同的触发器。也说明了该类攻击的防御也是目前值得做的一个方向。
abstract
- 提出了第一种适用于DNN后门攻击的鲁棒和普遍的检测和缓解系统。
- 该方法可以识别后门和重建可能的触发器,通过输入过滤、神经元剪枝和unlearning来识别多种缓解技术。
- 针对先前的两种后门注入方法证明该方法的有效性。
1.introduction
给定一个经过训练的DNN模型,该工作确定是否有一个输入触发器,当添加到输入中时,会产生错误分类的结果,该触发器是什么样子,以及如何减轻,即从模型中移除它。(在该论文的其余部分,作者将添加了触发器的输入称为对抗输入。)
贡献
-
提出了一种新的和可推广的检测技术,和嵌入深度神经网络的逆向工程隐藏触发器。
-
在各种神经网络应用上实现和验证了我们的技术,包括手写数字识别、交通标志识别、大量标签的面部识别和使用转移学习的面部识别。
-
通过详细的实验开发和验证了三种缓解方法:(一)对抗输入的早期过滤器,该过滤器用已知的触发器识别输入,二)基于神经元剪枝的模型修补算法,以及一种基于unlearning的模型修补算法。
-
总结了后门攻击的更先进的变体,实验评估它们对我们的检测和缓解技术的影响。
2.background
以前的攻击
- BadNets
- Trojaning attack
以前的防御
- Fine-Pruning
- 一个花费较大且仅针对Mnist的防御
3.overview
A.Attack Model
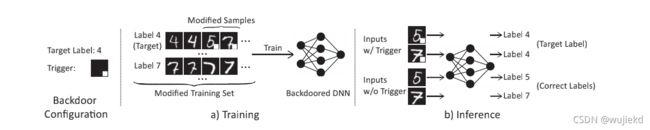
针对BadNets和Trojaning attack攻击后生成的模型,如下图所示,非常直观的一个后门攻击的例子
B.Defense Assumptions and Goals
-
假设:防御者可以访问训练后的DNN,以及有一组正确标记的样本
-
目标:
- Detecting backdoor:判定一个训练好的DNN是否有后门,并且该后门攻击的目标标签是什么
- Identifying backdoor:识别出后门攻击所使用的触发器
- Mitigating Backdoor:使后门攻击无效,通过两种互补的方法,一种是过滤掉攻击者提供的对抗性输入,另一种是修补DNN去移除后门。
C.Defense Intuition and Overview
Detecting Backdoors
直觉:受攻击的模型,需要更少的修改量就可以造成误分类。
具体实现算法有3个步骤:
- 对于一个给定的标签,认为是潜在的后门攻击的目标标签,设计一个优化方案去寻找从其他类到该目标类误分类的最小化的触发器。
- 以上给定的标签,将有输出标签的个数决定,N分类问题,即可输出N个最小化的触发器。
- 在计算了N个潜在的触发器后,评估每个触发器的大小(通过每个触发器修改的像素点个数进行统计)。运行离群点检测算法来检测是否有任何一个触发候选显著小于其他候选。一个显著的离群点代表一个真实的触发器,而那个触发器的标签匹配就是后门攻击的目标标签。
Identifying Backdoor Triggers
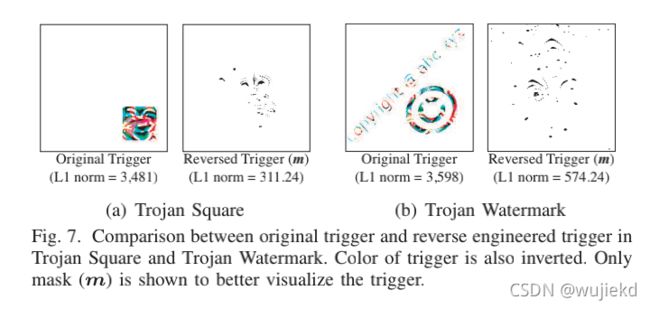
通过上面的算法,得到的这个触发器是“逆向工程触发器”,作者比较了该触发器和攻击者真实使用的触发器的视觉差异。
Mitigating Backdoors
这个逆向工程触发器可以帮助我们了解到哪一个神经元对触发器更加敏感,利用这些知识构建了一个主动过滤器,可以检测和过滤掉激活后门相关神经元的所有对抗性输入。 并且设计了两种方法,可以从感染模型中去除后门相关的神经元/权重,并将感染模型修补为抵抗对抗性图像的鲁棒性。
4.DETAILED DETECTION METHODOLOGY
Reverse Engineering Triggers
定义一个通用的触发器:

A ( ⋅ ) A(·) A(⋅)表示将触发器加到原图, △ \triangle △是这个触发器模式, m m m是掩码,先前攻击所使用的掩码取值0 or 1,该掩码是从0到1连续的形式,所以更加通用。
优化这个触发器有两个目标,一个是使图像误分类到目标类,另一个是需要简洁,即仅修改图像的有限部分。
针对这两个目标,给出多目标优化函数:

其中 ∣ m ∣ |m| ∣m∣是 L 1 L1 L1范数, λ \lambda λ是超参数,控制后门攻击的有效性。
使用Adam优化器去优化上述目标函数,找到每个目标类对应的最优的逆向工程触发器。
Detect Backdoor via Outlier Detection
通过以上方法,可以获得每个目标类对应的逆向工程触发器,和它们的 L 1 L1 L1范数。
识别在分布中显示为具有较小 L 1 L1 L1范数的异常值的触发器
为了检测异常值,使用了一种基于绝对中位差(Median Absolute Deviation)的简单技术,该技术在多个异常值存在时具有弹性。它首先计算所有数据点与中位数之间的绝对偏差。这些绝对偏差的中位数称为MAD。然后将数据点的异常指数定义为数据点的绝对偏差除以MAD(一个常数估计(1.4826)被应用于规范化异常指数)。任何异常指数大于2的数据点有> 95%的概率是离群值。我们将任何异常指数大于2的标签标记为离群点,只关注分布末端较小的离群点(低L1范数表示标签更脆弱,即更容易攻击)。
该方法优于常规的最大最小归一化,存在离群点时也可使用,详细证明可参考论文:Data Normalization using Median & Median Absolute Deviation (MMAD) based Z-Score for Robust Predictions vs. Min – Max Normalization
Detecting Backdoor in Models with a Large Number of Labels.
可以看到,该方法都每一个输出的标签都需要重建一个逆向工程触发器,当模型的输出类别非常多,这就要花费巨大的设备资源。
作者提出了一种低花费的检测方法,在对式子(3)优化几次得到近似解后,接下来就采用剩余的迭代微调触发器。因此,我们可以对上述的近似触发器进行筛选,挑选出来的可疑的触发器进行完整的优化,再使用异常检测。
5. EXPERIMENTAL VALIDATION
Experiment Setup
- Against BadNets:
- Model and dataset:
- (1) Hand-written Digit Recognition (MNIST)
- (2) Traffific Sign Recognition(GTSRB)
- (3) Face Recognition with large number of labels(YouTube Face)
- (4) Face Recognition using a complex model (PubFig)
- Model and dataset:

- Against BadNets:
- Model and dataset:
- Trojan Square and Trojan Watermark(two already infected Face Recognition models used in the original work and shared by authors)
- Model and dataset:
该方法优化得到的逆向触发器与原来的触发器相比,找到了一种更“紧凑”的后门触发器形式。
具体实验配置不展开,如若复现,再具体察看。
Similarity in Neuron Activations

先给结论:逆向触发器和原始触发器的输入在网络层内部层具有相似的神经元激活。
输入大量的干净图像、带逆向触发器图像、正常带触发器图像,对该三类在神经网络中的每一个神经元输出值进行平均然后讨论。
具体来说,检查第二层到最后一层的神经元。通过测量神经元激活程度的差异来对它们进行排序(对抗性输入每个神经元的激活与干净输入对应神经元的激活的差值从大到小)。作者发现前1%的神经元足以使后门,即保持前1%的神经元,并掩盖剩余的(设置为零),攻击仍然有效。
表三显示了在输入1000个随机选择的清洁和对抗性图像时,前1%神经元的平均神经元激活。 在所有测试的模型下,在对抗性图像中,神经元激活的值比干净图像高得多,从3x到7x不等。
6. MITIGATION OF BACKDOORS
提出了两种互补的技术去移除后门。
-
首先,我们为对抗性输入创建一个过滤器,该过滤器识别和拒绝任何带有触发器的输入,给我们时间修补模型。 根据应用程序的不同,这种方法也可以用于将“安全”输出标签分配给对抗性输入,而不会被拒绝。
-
其次,我们修补DNN,使其对检测到的后门触发器没有响应。 我们描述了两种修补方法,一种是使用神经元剪枝,另一种是基于unlearning。
A. Filter for Detecting Adversarial Inputs
我们建立了基于神经元激活剖面的逆向触发过滤器。 这是测量的平均神经元激活的前1%的神经元在第二层到最后一层。 给定一些输入,过滤器将潜在的对抗性输入标识为激活配置文件高于一定阈值的输入。 激活阈值可以使用干净输入(已知没有触发器的输入)的测试来校准)。
B. Patching DNN via Neuron Pruning
建议从DNN中剪除后门相关的神经元,即在推理过程中将这些神经元的输出值设置为0。 我们再次针对神经元进行排序,根据干净输入和对抗性输入之间的差异(使用逆向触发器)。 我们再次瞄准第二层到最后一层,并按最高等级第一的顺序修剪神经元(即优先考虑那些显示干净和对抗性输入之间最大激活差距的输入)。 为了尽量减少对干净输入对分类精度的影响,当修剪模型不再响应于逆向触发器时,我们停止修剪。
C. Patching DNNs via Unlearning
第二种修补方法是重新训练该DNN来解除原始触发器。 我们可以使用逆向触发器来训练感染的DNN来识别正确的标签。
7. ROBUSTNESS AGAINST ADVANCED BACKDOORS
讨论了5种特定类型的高级后门攻击,每种攻击都挑战了当前防御设计中的假设或限制。
-
复杂触发器
-
作者提出的问题:我们的检测方案依赖于优化过程的成功。 更复杂的触发器会使我们的优化函数收敛更具挑战性吗
-
攻击具体实现:触发器的每个像素被分配一个随机颜色,并测试了其他形状的触发器
-
解决情况:所有检测和缓解技术都按预期工作
-
-
更大的触发器
-
作者提出的问题:通过增加触发器大小,攻击者可以迫使逆向工程过程收敛到具有较大范数的大触发器。
-
攻击具体实现:触发器的大小从4×4增加至16×16
-
解决情况:一般来说,大的触发器对于肉眼来说看起来效果会更好,但在检测和缓解技术中,实现的效果都并不是很好。
-
-
多个感染标签与多个触发
- 作者提出的问题:多个后门针对不同的标签被插入到一个模型,并评估可以检测到感染标签的最大数量。 太多的后门会降低分类性能,模型的后门应该有一个上限。
- 攻击具体实现:生成具有互斥色彩模式的独特触发器,每个触发器触发不同的后门,即攻击到不同的目标。
- 解决情况:异常值检测方法在此场景中失败,但逆向工程方法仍然有效。对于所有受感染的标签,我们成功地逆转了正确的触发器。
-
单一感染标签与多个触发器
-
作者提出的问题:多个触发器针对同一标签。在这种情况下,该方法可能只能检测和修补其中的一种后门。
-
攻击具体实现:设计多个触发器,每个触发器触发相同的后门,即攻击同一个的目标。9个不同的触发器,触发器具有相同的形状和颜色,但位于图像的不同位置, 即四个角,四个边,和中心。
-
解决情况:检测技术的一次运行只识别和修补一个注入的触发器。 但是,运行检测和修补算法3次迭代后能够依次降低所有触发器的成功率
-
-
源标签专用(部分)后门
- 作者的检测方案旨在检测导致任意输入错误分类的触发器。一个不太强大的 “部分”后门可以被设计成只触发错误分类时,应用于属于源标签子集的输入,而当应用于其他输入时什么也不做。 其实指的是触发器在A类图片中,可攻击成功到C类,但放在B类中,却攻击不成功。
- 解决情况:未能解决,因为该论文方法的提出有一个关键假设:触发器应用在任何一类都应该攻击成功,即分类至指定目标类。