神经清洗——识别与去除后门:Neural Cleanse: Identifying and Mitigating Backdoor Attacks in Neural Networks
Neural Cleanse: Identifying and Mitigating Backdoor Attacks in Neural Networks
2019 IEEE Symposium on Security and Privacy
论文地址
深度神经网络黑盒的一个基本问题是:无法详尽地测试他的行为。因为神经网络的输入是极高维度的,其输入样本空间非常非常大。这使得神经网络的后门攻击成为可能。
这篇论文就是为了判断一个给定的DNN中是否存在一个触发器,会导致错误的输出。以及该触发器是什么样子的,已经如何从模型中减轻或删除后门。
- 提出一种新的可推广的技术,用于检测,以及反向工程获得隐藏在DNN中的后门触发器。
- 提出三种方法1、对抗输入的过滤器,用于识别存在未知触发器的输入;2、基于神经元剪枝的模型补丁算法;3、基于unlearning的模型补丁算法。
- 识别了后门攻击的高级变体。
后门对模型预测的影响的一种直观解释:
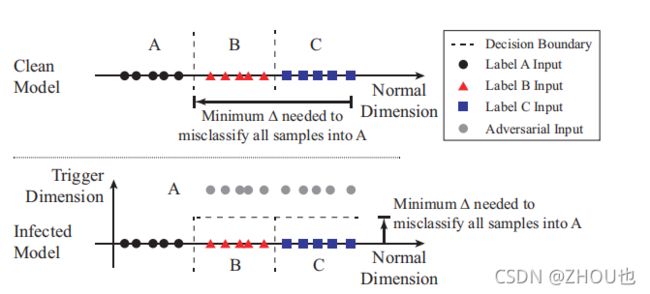
后门对模型预测影响的一种直观解释。图片上方是一个干净的模型。下方是插入了后门之后的模型。插入后门之后,改变了决策边界,使得正常输入只需要更少的修改就可以变为目标类。
后门检测与识别
其关键点是:在一个被感染的模型中,它需要更少的改变,来导致样本误分类到目标标签,相比其他没有被感染的标签。
所以后门检测的方法分为三步:
- 对于一个给定的标签,将其视为后门攻击的潜在标签,设计一个最优化的方案,以找到最小的触发器,将其他标签的样本错误分类到该标签。
- 反复步骤1,得到每个标签对应的触发器。
- 测量每个触发器的大小。根据触发器替换的像素来判断是否为后门触发器。
这个触发器就是通过反向工程构建的。通过反向工程获得的触发器很可能与真实的触发器不同。
首先定义一个后门触发器的通用格式
A ( x , m , Δ ) = x ′ A(x,m,\Delta)=x^\prime A(x,m,Δ)=x′
x i , j , k ′ = ( 1 − m i , j ) . x i , j , c + m i , j . Δ i , j , c x^\prime_{i,j,k}=(1-m_{i,j}).x_{i,j,c}+m_{i,j}.\Delta_{i,j,c} xi,j,k′=(1−mi,j).xi,j,c+mi,j.Δi,j,c
优化的目标有两个,一个是找到一个触发器,一个是找到一个尽可能简洁的优化器。
最终的优化格式如下:
m i n m , Δ l ( y t , f ( A ( x , m , Δ ) ) ) + λ . ∣ m ∣ min_{m,\Delta} l(y_t,f(A(x,m,\Delta)))+\lambda.|m| minm,Δl(yt,f(A(x,m,Δ)))+λ.∣m∣
f o r x ∈ X for\ x\in X for x∈X
通过这种方式能够获得每个触发器。
使用Median Absolute Deviation检测触发器中的异常值。
下图是使用反向工程获得的触发器的样式。


一个比较关键的点是,反向工程构建的后门触发器和原始后门触发器之间的神经元激活是否相似。
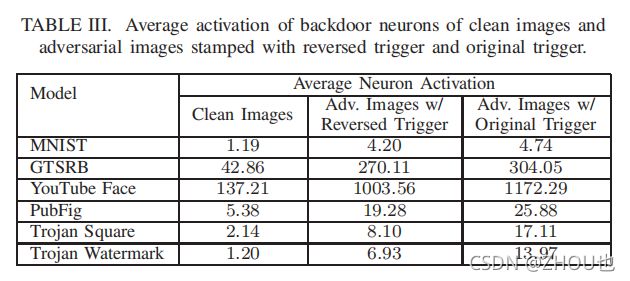
本文设计了一个实验,将1000张相似的图片输入到神经网络,并测量其激活值。干净输入的激活值较小。而添加原始触发模式和反向工程触发模式的图片激活的是相似的神经元。
答案是,相似。通过保留触发的前1%的神经元,能够发现攻击仍然有效。
缓解后门
本文设计了两种方法。
A,设计一种过滤器来过滤后门输入。
神经元激活是一种更好的方式,用于衡量原始输入和后门输入之间的相似性,因此这种方式就是基于神经元激活,测量倒数第二层神经元的激活的前1%。给定一个阈值,过滤器将会过滤掉潜在的后门攻击样本。
B,修补DNN,使其对后门触发器没有反应。
通过神经元剪枝实现。
使用反向触发器帮助识别DNN中的后门相关的组件,比如神经元,然后直接删除。对比干净输入和后门输入之间激活神经元的不同,对神经元进行排序。删除神经元,在不影响模型性能的前提下。
不过有些触发器依赖的神经元与正常预测依赖的神经元之间存在重合,删减这部分神经元会导致性能的下降。
C, 通过Unlearning实现
第二种方式是通过训练DNN来取消学习原来的触发器。
通过使用反向触发器来训练被感染的DNN模型,使之能够识别正确的标签,即使触发器已经存在。
unlearning的方式允许模型通过训练的方式来决定那些权重是有问题的,并进行更新。

从实验来看,unlearning效果不错。
结论
本文的核心思想是:受感染的标签比未受感染的标签更加脆弱。
本文还是有一些局限性的。
比如对于更加复杂的触发模式,可能无法很好地通过反向工程实现。文中对应的触发模式都是固定的。而一些触发模式,可能是通过一些扭曲、隐写术来实现的,其触发器构建更加复杂,一图一形式。
此外,其假设也是构建在:触发模式与原始输入独立的前提。这也使得在进行剪枝时,能够减少对模型性能的影响。