PyTorch深度学习(18)网络结构LeNet、AlexNet
CNN(Convolutional Neural Network)
目标分类 Classification 图像属于哪一类
目标检索 Retrieval 相同种类归为一类
目标检测 Detection 框选且框内是什么,概率是多少
图像分割 Segmentation 图像分为不同区域
无人驾驶 self-driving cars
图像描述 Image Captioning
图像风格迁移 某些图像特征可视化,不同风格应用到类似图中
雏形:LeCun的LeNet(1998)网络结构
Pytorch Tensor的通道顺序:[batch,channel,height,wight]
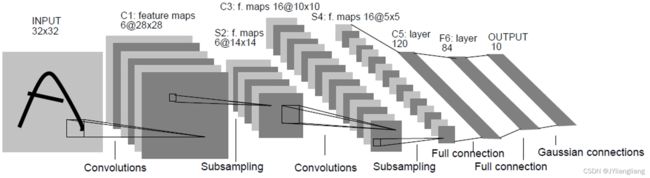
(1)LeNet
import torch
import torch.nn as nn
import torch.nn.functional as F
class LeNet(nn.Module):
def __init__(self):
super(LeNet, self).__init__()
self.conv1 = nn.Conv2d(3, 16, 5)
self.pool1 = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(16, 32, 5)
self.pool2 = nn.MaxPool2d(2, 2)
self.fc1 = nn.Linear(32*5*5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = F.relu(self.conv1(x)) # input(3, 32, 32) output(16, 28, 28)
x = self.pool1(x) # output(16, 14, 14)
x = F.relu(self.conv2(x)) # output(32, 10, 10)
x = self.pool2(x) # output(32, 5, 5)
x = x.view(-1, 32*5*5) # output(32*5*5)
x = F.relu(self.fc1(x)) # output(120)
x = F.relu(self.fc2(x)) # output(84)
x = self.fc3(x) # output(10)
return x
input1 = torch.rand([32, 3, 32, 32])
model = LeNet()
print(model)
output = model(input1)
(2)Train Phase
import torch
import torchvision
import torch.nn as nn
from LeNet import LeNet
import torch.optim as optim
import torchvision.transforms as transforms
import numpy as np
import torch.utils.data.dataloader
import matplotlib.pyplot as plt
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
# 50000张训练图片
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=False, transform=transform)
# 10000张测试图片
testset = torchvision.datasets.CIFAR10(root='./data', train=False, download=False, transform=transform)
# 加载数据
trainLoader = torch.utils.data.DataLoader(trainset, batch_size=36, shuffle=True, num_workers=0)
testLoader = torch.utils.data.DataLoader(testset, batch_size=10000, shuffle=True, num_workers=0)
# 迭代器
test_data_iter = iter(testLoader)
test_image, test_label = test_data_iter.next()
classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
net = LeNet()
loss_function = nn.CrossEntropyLoss()
optim = optim.Adam(net.parameters(), lr=0.001)
# 官方显示图片代码
# def imshow(img):
# img = img / 2 + 0.5 # unnormalize
# npimg = img.numpy()
# plt.imshow(np.transpose(npimg, (1, 2, 0)))
# plt.show()
#
# # print label
# print(' '.join('%5s' % classes[test_label[j]] for j in range(4)))
# # show image
# imshow(torchvision.utils.make_grid(test_image))
for epoch in range(5):
running_loss = 0.0
for step, data in enumerate(trainLoader, start=0):
# get the inputs; data is a list of [inputs, labels]
inputs, labels = data
# zero the parameter gradients
optim.zero_grad()
# forward + backward + optimize
outputs = net(inputs)
loss = loss_function(outputs, labels)
loss.backward()
optim.step()
# print statistics
running_loss += loss.item()
if step % 500 == 499: # print every 500 mini-batches
with torch.no_grad():
outputs = net(test_image) # [batch, 10]
predict_y = torch.max(outputs, dim=1)[1]
accuracy = (predict_y == test_label).sum().item() / test_label.size(0)
print('[%d, %5d] train_loss: %.3f test_accuracy:%.3f' %
(epoch + 1, step + 1, running_loss / 500, accuracy))
running_loss = 0.0
print('Finished Training')
save_path = './Lenet.pth'
torch.save(net.state_dict(), save_path)# GPU训练
import torchvision
import torch
from LeNet import LeNet
from torchvision import transforms
import torch.utils.data.dataloader
import matplotlib.pyplot as plt
import numpy as np
import torch.optim as opt
classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
net = LeNet()
net.to(device)
loss_function = torch.nn.CrossEntropyLoss()
optimizer = opt.Adam(net.parameters(), lr=0.001)
def main():
print('---%s' % device)
train_data = torchvision.datasets.CIFAR10(root='../dataset/cifar_data', train=True, transform=transform, download=False)
test_data = torchvision.datasets.CIFAR10(root='../dataset/cifar_data', train=False, transform=transform, download=False)
train_loader = torch.utils.data.DataLoader(train_data, batch_size=32, shuffle=True, num_workers=0)
test_loader = torch.utils.data.DataLoader(test_data, batch_size=10000, shuffle=True, num_workers=0)
test_iter = iter(test_loader)
test_images, test_labels = test_iter.next()
for epoch in range(5):
running_loss = 0.0
for step, data in enumerate(train_loader, start=0):
inputs, labels = data
optimizer.zero_grad()
inputs = inputs.to(device)
labels = labels.to(device)
outputs = net(inputs)
loss = loss_function(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
if step % 500 == 499:
with torch.no_grad():
test_images = test_images.to(device)
test_labels = test_labels.to(device)
outputs = net(test_images)
predict_y = torch.max(outputs, dim=1)[1]
accuracy = (predict_y == test_labels).sum().item() / test_labels.size(0)
print('%d %3d summary loss=%.3f accuracy=%.3f' % (epoch + 1, step + 1, running_loss, accuracy))
save_pth() # 保存路径
def imshow(img):
img = img / 2 + 0.5 # normalize
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0)))
plt.show()
def save_pth():
save_path = './Lenet.pth'
torch.save(net.state_dict(), save_path)
if __name__ == '__main__':
main()
(3)Test Phase
import torch
import torchvision.transforms as transforms
from PIL import Image
from LeNet import LeNet
transform = transforms.Compose(
[transforms.Resize((32, 32)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
net = LeNet()
net.load_state_dict(torch.load('Lenet.pth'))
im = Image.open('image name')
im = transform(im) # [C, H, W]
im = torch.unsqueeze(im, dim=0) # [N, C, H, W]
with torch.no_grad():
outputs = net(im)
predict = torch.max(outputs, dim=1)[1].data.numpy()
predict = torch.softmax(outputs, dim=1)
print(classes[int(predict)])AlexNet
2012年ISLVRC2012(ImageNet Large Scale Visual Recognition Challenge)竞赛冠军网络,分类准确率由传统的70%+提升到80%+。由Hinton和其学生Alex Krizhevsky设计的。
ISLVRC 用于数据分类
- ISLVRC 2012
- 训练集:1281167张已标注图片
- 验证集:50000张已标注图片
- 测试集:100000张未标注图片
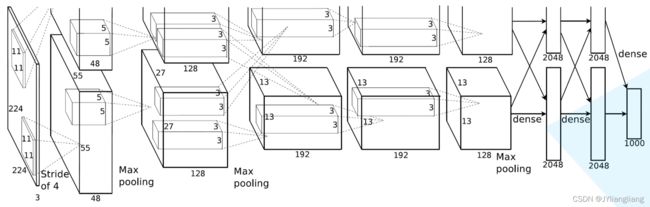
亮点:
- 首次利用GPU进行网络加速训练
- 使用了ReLU激活函数,而不是传统Sigmoid激活函数及Tanh激活函数
- 使用了LRN局部响应归一化
- 在全连接层的前两层中使用了Dropout随机失活神经元操作,减少过拟合
| layer_name | kernel_size | kernel_num | padding | stride |
| Conv1 | 11 | 96 | [1, 2] | 4 |
| Maxpool1 | 3 | None | 0 | 2 |
| Conv2 | 5 | 256 | [2, 2] | 1 |
| Maxpool2 | 3 | None | 0 | 2 |
| Conv3 | 3 | 384 | [1, 1] | 1 |
| Conv4 | 3 | 384 | [1, 1] | 1 |
| Conv5 | 3 | 256 | [1, 1] | 1 |
| Maxpool3 | 3 | None | 0 | 2 |
| FC1 | 2048 | None | None | None |
| FC2 | 2048 | None | None | None |
| FC3 | 1000 | None | None | None |
AlexNet
import torch.nn as nn
import torch
class AlexNet(nn.Module):
def __init__(self, num_classes=1000, init_weights=False):
super(AlexNet, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 48, kernel_size=11, stride=4, padding=2), # input[3, 224, 224] output[48, 55, 55]
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), # output[48, 27, 27]
nn.Conv2d(48, 128, kernel_size=5, padding=2), # output[128, 27, 27]
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), # output[128, 13, 13]
nn.Conv2d(128, 192, kernel_size=3, padding=1), # output[192, 13, 13]
nn.ReLU(inplace=True),
nn.Conv2d(192, 192, kernel_size=3, padding=1), # output[192, 13, 13]
nn.ReLU(inplace=True),
nn.Conv2d(192, 128, kernel_size=3, padding=1), # output[128, 13, 13]
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), # output[128, 6, 6]
)
self.classifier = nn.Sequential(
nn.Dropout(p=0.5),
nn.Linear(128 * 6 * 6, 2048),
nn.ReLU(inplace=True),
nn.Dropout(p=0.5),
nn.Linear(2048, 2048),
nn.ReLU(inplace=True),
nn.Linear(2048, num_classes),
)
if init_weights:
self._initialize_weights()
def forward(self, x):
x = self.features(x)
x = torch.flatten(x, start_dim=1)
x = self.classifier(x)
return x
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)Train
import os
import sys
import json
import torch
import torch.nn as nn
from torchvision import transforms, datasets, utils
import matplotlib.pyplot as plt
import numpy as np
import torch.optim as optim
from tqdm import tqdm
from model import AlexNet
def main():
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("using {} device.".format(device))
data_transform = {
"train": transforms.Compose([transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]),
"val": transforms.Compose([transforms.Resize((224, 224)), # cannot 224, must (224, 224)
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])}
data_root = os.path.abspath(os.path.join(os.getcwd(), "")) # get data root path
image_path = os.path.join(data_root, "data_set", "flower_data") # flower data set path
assert os.path.exists(image_path), "{} path does not exist.".format(image_path)
train_dataset = datasets.ImageFolder(root=os.path.join(image_path, "train"),
transform=data_transform["train"])
train_num = len(train_dataset)
# {'daisy':0, 'dandelion':1, 'roses':2, 'sunflower':3, 'tulips':4}
flower_list = train_dataset.class_to_idx
cla_dict = dict((val, key) for key, val in flower_list.items())
# write dict into json file
json_str = json.dumps(cla_dict, indent=4)
with open('class_indices.json', 'w') as json_file:
json_file.write(json_str)
batch_size = 32
nw = min([os.cpu_count(), batch_size if batch_size > 1 else 0, 8]) # number of workers
print('Using {} dataloader workers every process'.format(nw))
train_loader = torch.utils.data.DataLoader(train_dataset,
batch_size=batch_size, shuffle=True,
num_workers=nw)
validate_dataset = datasets.ImageFolder(root=os.path.join(image_path, "val"),
transform=data_transform["val"])
val_num = len(validate_dataset)
validate_loader = torch.utils.data.DataLoader(validate_dataset,
batch_size=4, shuffle=False,
num_workers=nw)
print("using {} images for training, {} images for validation.".format(train_num,
val_num))
# test_data_iter = iter(validate_loader)
# test_image, test_label = test_data_iter.next()
#
# def imshow(img):
# img = img / 2 + 0.5 # unnormalize
# npimg = img.numpy()
# plt.imshow(np.transpose(npimg, (1, 2, 0)))
# plt.show()
#
# print(' '.join('%5s' % cla_dict[test_label[j].item()] for j in range(4)))
# imshow(utils.make_grid(test_image))
net = AlexNet(num_classes=5, init_weights=True)
net.to(device)
loss_function = nn.CrossEntropyLoss()
# pata = list(net.parameters())
optimizer = optim.Adam(net.parameters(), lr=0.0002)
epochs = 10
save_path = './AlexNet.pth'
best_acc = 0.0
train_steps = len(train_loader)
for epoch in range(epochs):
# train
net.train()
running_loss = 0.0
train_bar = tqdm(train_loader, file=sys.stdout)
for step, data in enumerate(train_bar):
images, labels = data
optimizer.zero_grad()
outputs = net(images.to(device))
loss = loss_function(outputs, labels.to(device))
loss.backward()
optimizer.step()
# print statistics
running_loss += loss.item()
train_bar.desc = "train epoch[{}/{}] loss:{:.3f}".format(epoch + 1,
epochs,
loss)
# validate
net.eval()
acc = 0.0 # accumulate accurate number / epoch
with torch.no_grad():
val_bar = tqdm(validate_loader, file=sys.stdout)
for val_data in val_bar:
val_images, val_labels = val_data
outputs = net(val_images.to(device))
predict_y = torch.max(outputs, dim=1)[1]
acc += torch.eq(predict_y, val_labels.to(device)).sum().item()
val_accurate = acc / val_num
print('[epoch %d] train_loss: %.3f val_accuracy: %.3f' %
(epoch + 1, running_loss / train_steps, val_accurate))
if val_accurate > best_acc:
best_acc = val_accurate
torch.save(net.state_dict(), save_path)
print('Finished Training')
if __name__ == '__main__':
main()Predict
import os
import json
import torch
from PIL import Image
from torchvision import transforms
import matplotlib.pyplot as plt
from model import AlexNet
def main():
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
data_transform = transforms.Compose(
[transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
# load image
img_path = "../tulip.jpg"
assert os.path.exists(img_path), "file: '{}' dose not exist.".format(img_path)
img = Image.open(img_path)
plt.imshow(img)
# [N, C, H, W]
img = data_transform(img)
# expand batch dimension
img = torch.unsqueeze(img, dim=0)
# read class_indict
json_path = './class_indices.json'
assert os.path.exists(json_path), "file: '{}' dose not exist.".format(json_path)
json_file = open(json_path, "r")
class_indict = json.load(json_file)
# create model
model = AlexNet(num_classes=5).to(device)
# load model weights
weights_path = "./AlexNet.pth"
assert os.path.exists(weights_path), "file: '{}' dose not exist.".format(weights_path)
model.load_state_dict(torch.load(weights_path))
model.eval()
with torch.no_grad():
# predict class
output = torch.squeeze(model(img.to(device))).cpu()
predict = torch.softmax(output, dim=0)
predict_cla = torch.argmax(predict).numpy()
print_res = "class: {} prob: {:.3}".format(class_indict[str(predict_cla)],
predict[predict_cla].numpy())
plt.title(print_res)
for i in range(len(predict)):
print("class: {:10} prob: {:.3}".format(class_indict[str(i)],
predict[i].numpy()))
plt.show()
if __name__ == '__main__':
main()